简介
xlrd是python的一个第三方模块,可以实现跨平台读Microsoft Excel文件。(它有一个兄弟叫xlwt,专注于写Excel文件。)
它并不像win2com那样借助COM技术来访问Excel,而是直接分析Excel文件格式,从中解析数据。因此你可以在任何支持python的平台上使用excel文件。这一点它比win2com要优秀得多。
另外,它对unicode支持的很好,这也是我青睐它的重要原因。
它的工作原理所限,我们不能期望它覆盖Excel全部的功能,访问到全部的数据。
比如,下面这些数据类型xlrd会忽略掉:
图表,宏,图片等嵌入对象(包括嵌入的worksheet)。
VBA模块。
公式(只能识别公式的计算结果,而不是公式本身)。
注释。
链接。
但一些简单的读取还是得心应手的,这已经能满足大多数情况下的需求。
现在它能支持的Excel版本包括:2004, 2003, XP, 2000, 97, 95, 5.0, 4.0, 3.0, 2.1, 2.0。 官方未说明它是否能支持Excel 2007。
它有两个分支,分别是:
xlrd (http://pypi.python.org/pypi/xlrd) 针对Python 2.x系列。
xlrd3(http://pypi.python.org/pypi/xlrd3) 针对Python 3.x系列。
这两个分支是100%兼容的,也就是说,它们的使用完全一样,你在3.x系列中怎么用xlrd,在2.x系列中仍然这么用。
以下的实际操作都使用xlrd3,在python 3.2下完成。
试用
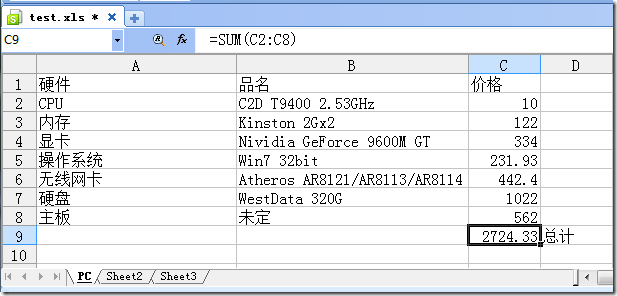
假设我们有一个文件叫test.xls,位于D:\Workspace\Python\xlrd3-test\test.xls
其内容如下:
clipboard[1]
这是一张9行4列的PC主机报价单,当然,价格全是扯淡。
下面使用xlrd程序将PC这张表的内容打印出来。
01 import xlrd3
02
03 def main():
04 xlsfile=xlrd3.open_workbook("D:\\Workspace\\Python\\xlrd3-test\\test.xls")
05 try:
06 mysheet = xlsfile.sheet_by_name("PC")
07 except:
08 print("no sheet in %s named PC")
09 return
10
11 # total rows and cols
12 print("%d rows, %d cols"%(mysheet.nrows, mysheet.ncols))
13
14 for row in range(0, mysheet.nrows):
15 temp=""
16 for col in range(0, mysheet.ncols):
17 if mysheet.cell(row, col).value != None:
18 temp+=str(mysheet.cell(row, col).value)+"\t"
19 print(temp)
20
21 if __name__ == ‘__main__‘:
22 main()
输出:
clipboard[2]

将lang下的txt文件导出到一个excel里:
01.import os
02.import glob
03.path = os.getcwd()
04.files = glob.glob(‘../trunk/Resource/lang/ja/*.txt‘)
05.import xlwt3
06.if len(files) > 0:
07.wb = xlwt3.Workbook()
08.for file in files:
09.fileName = file.split(‘\\‘)[1].split(‘.‘)[0]
10.print(fileName)
11.ws = wb.add_sheet(fileName)
12.with open(file, encoding=‘utf-8‘) as a_file:
13.line_number = 0
14.for a_line in a_file:
15.a_line = a_line.rstrip()
16.mark = a_line.find("=")
17.ws.write(line_number, 0, a_line[0:mark])
18.ws.write(line_number, 1, a_line[mark+1:])
19.ws.col(0).width = 8000
20.ws.col(1).width = 40000
21.line_number += 1
22.a_file.close()
23.wb.save(‘langPack_ja.xls‘)
将sourceExcel下的excel文件导出为各txt文件:
01.import os
02.import glob
03.import xlrd3 as xlrd
04.import re
05.
06.path = os.getcwd()
07.
08.files = glob.glob(‘sourceExcel/*‘)
09.
10.for file in files:
11.wb = xlrd.open_workbook(file)
12.for sheetName in wb.sheet_names():
13.txtFile = open(‘outputTxts/‘ + sheetName + ‘.txt‘, mode=‘w‘, encoding=‘utf-8‘)
14.sheet = wb.sheet_by_name(sheetName)
15.for rownum in range(sheet.nrows):
16.v1 = sheet.cell(rownum, 0).value
17.if (type(v1) == float):
18.v1 = str(v1)
19.v1 = re.sub(‘\.0*$‘, "", v1)
20.v1 = v1.rstrip()
21.v2 = sheet.cell(rownum, 1).value
22.if (type(v2) == float):
23.v2 = str(v2)
24.v2 = re.sub(‘\.0*$‘, "", v2)
25.v2 = v2.rstrip()
26.dataStr = v1 + ‘=‘ + v2 + ‘\n‘
27.txtFile.write(dataStr)
28.txtFile.close()
原文:http://my.oschina.net/duguaoxue/blog/493688