需求分析
自然语言处理的人机对话中,用户的语句表达具有多样性,例如“我喜欢你”、“你被我喜欢着”表达的是同一个意思,如何让计算机理解识别这些多样化的句子,面对各式各样的同义问题,都能作出相同的问答,本文尝试通过语法树、依赖树等工具将多样化的问句转换成较为统一形式的句子,以方便计算机识别这些语句。
特征表示
我们的目标是解决中文语句的多样性,考虑到如果直接使用词汇作为特征,有可能由于多样化的组合导致问题复杂化,例如:①你被我喜欢着;②她被我喜欢着,都可以转换成相同的形式 ①我喜欢你;我喜欢她。这些相同的形式就作为语句的分类,计算机根据这些分类来组织回答。
上述例子中,我们可以考虑通过标注来解决组合复杂化的问题,可以根据领域知识进行语义标注,也可以使用语法词性标注。考虑到领域知识归纳的困难度,本文使用第二种方法来解决问题。例如:①我喜欢你;我喜欢她,都可以标注成PN + V + PN。
特征选取
自然语言处理中存在语法树、依赖树这两种工具,我们可以考虑使用语法树、依赖树的词性标注、语法边、树结构等作为特征,表示同一类进行的语句,同一类的语句给它记录一条规则使之转换至统一形式的语句。
模型选择
特征选取完后,如何将同一类的语句给它记录一条规则使之转换至统一形式的语句,本文使用同步树替换文法模型。
资料整理自 Sentence Compression as Tree Transduction.pdf 与 一种基于同步树替换文法的统计机器翻译模型.pdf 摘抄自《人工智能原理及其应用(第2版)》
在Sentence Compression as Tree Transduction 一文中,Abstract摘要 这样写道:
“This paper presents a tree-to-tree transduction method for sentence compression. Our model is based on synchronous tree substitution grammar, a formalism that allows local distortion of the tree topology and can thus naturally capture structural mismatches.”作者提出了一种基于同步树替换文法(STSG,synchronous tree substitution grammar)的树-树转换句子压缩算法。
在 一种基于同步树替换文法的统计机器翻译模型 一文中,Abstract摘要 这样写道:
“提出一种基于同步树替换文法 的机器翻译模型。相对于基于短语的模型,此模型可以对远距离结构性调序和非连续短语翻译进行建模;相对于基于同步上下文无关文法 模型,此模型可以对任何层次上的树节点调序进行建模。”
上下文无关文法(context free grammar)是乔姆斯基提出的一种能对自然语言语法知识进行形式化描述的方法。在这种文法中,语法知识使用重写规则 表示的。下面举一个例子:
我们对一个英文子集“The professor trains Jack. ”作上下文无关文法分析。
人工编写的重写规则 为:
语句→句子 终结符
句子→名词短语 动词短语
动词短语→动词 名词短语
名词短语→冠词 名词
名词短语→专用名词
冠词→the
名词→professor
动词→wrote
名词→book
动词→trains
专用名词→Jack
终结符→.
使用上面的重写规则,就可以把句子改写成一棵文法分析树(parse tree,语法树),
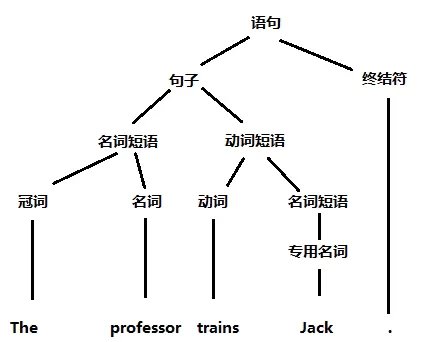
上下文无关文法反映了自然语言结构的层次特性,用它对自然语言的语法 进行形式化描述既严谨,又便于计算机实现。知识点:
在重写规则中,作为终结符 的有英语单词the, professor, wrote, book, trains, Jack 及 “.”,其余均为非终结符 。也可以这样理解,在上图中,叶子结点 就是终结符,非叶子结点 就是非终结符 。并且,“语句”是一个特殊的非终结符,称为起始符 ,可以看做根结点 。上述文法之所以被称为上下文无关,其原因是这些重写规则的左边均为孤立的非终结符,它们可以被右边的符号串替换,而不管左边出现的上下文,“冠词”并不影响“名词”替换成“professor”。
上下文无关文法反映的仅是一个句子本身的层次结构和生成过程 ,它不可能与另外的句子发生关系。而自然语言是上下文有关的,句子之间的关系也是客观存在的。于是,乔姆斯基提出了变换文法(transformational grammar)。变换文法认为,英语句子的结构有深层 和表层 两个层次。例如,句子“She read me a story.”和“She read a story to me.”的表层结构不一样,但它们指的是同一回事,即这两个句子的深层结构是一样的。再例如,主动句与被动句。在变换文法中,句子深层结构和表层结构之间 的变换是通过变换规则 实现的,变换规则把句子从一种结构变换成另一种结构。知识点:
变换文法的主要算法思路 就是,先用上下文无关文法建立相应句子的深层结构,然后再应用变换规则将深层结构变换为符合人们习惯的表层结构。目前许多双语翻译、缩句、句子成分移位的解决正是利用了这种思想。
其实变换规则就是,记录这两句平行预料的语法树结构,以后新进来一个句子,只要语法树结构跟上面的Source的语法树结构完全匹配,就可以应用这条规则,改写成Target的语法树,然后得到目标句子。
我的理解,同步树替换文法就是变换文法。有了上面的知识点,我们可以来看同步树替换文法 的定义:

在上述定义中,提到“元树 (elementary tree)”,我们来看一下元树的定义:

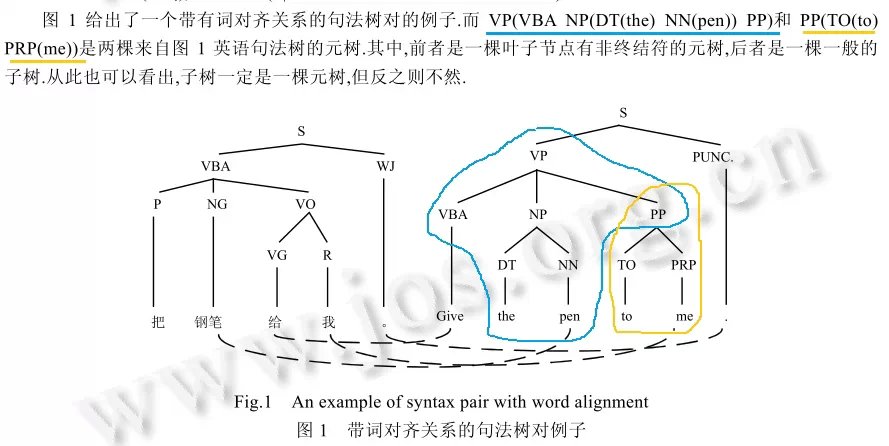
从定义及例子中,我们可以看出,元树是完整的子树 或子树缺失了某些部分,但必须保证的是,元树中的每个结点的第一层子结点必须是完整的,像PP(TO(to))这种就是不合法 的。树核向量中所用到的应该也称为子树。
为什么提到元树的呢?因为涉及到提取到的规则是否具有泛化能力,举个例子S(VBS WJ)既可以代表S(VBA(P NG VO) WJ),也可以代表S(VBA(XX XX) WJ),这样就可以防止提取到的变换规则的量太多而记录不下。
在基于同步树替换文法的缩句算法中,规则的约束条件为,树-树间的成分要么是成对的对齐成分,要么是被删除成分。变换规则提取学习算法一般为:

算法实现
乔姆斯基提出变换文法(transformational grammar),变换文法认为,句子的结构有深层 和表层 两个层次,例如:
She read me a story. 和 She read a story a story to me.
上述两个句子的表层结构不一样,但它们指的是同一回事,即其深层结构是唯一的。
本项目使用STSG(同步树替换文法)和 依赖树(句子主干提取)完成中文句子从表层结构到深层结构的转换。
使用依赖树进行「句子主干提取」其主要原理跟STSG 一样,只不过STSG 使用语法树 来提取规则,而语法树使用词性节点来表示句子的语法信息,树的结构较为复杂,针对句子成分移位 问题很难提取出较有泛化能力 的变换规则;而依赖树 使用语义边来表示句子的语法信息,树的结构较为简单,这时可以提取到较有泛化能力 的变换规则。但是,目前这种规则只能人工编写,缺少像STSG 规则自学习算法 那样强大的支撑,而人工编写规则很难覆盖全面 。
目前规则使用七元组:<边属性名,dep词项,dep词性,dep转换后位置,gov词项,gov词性,gov转换后位置>。七元组就是特征,详见第3节 特征选取。

项目代码
http://git.oschina.net/Keyven/IKeyven
Reference
人工智能原理及其应用(第2版)
Sentence Compression as Tree Transduction.pdf
一种基于同步树替换文法的统计机器翻译模型.pdf
原文:http://my.oschina.net/keyven/blog/513129