支持向量机(Support Vector Machine) 名字听起来很炫,功能也很炫,但公式理解起来常有眩晕感。所以本文尝试不用一个公式来说明SVM的原理,以保证不吓跑一个读者。理解SVM有四个关键名词: 分离超平面、最大边缘超平面、软边缘、核函数 。
所以 选择合适的核函数以及软边缘参数C就是训练SVM的重要因素 。一般来讲,核函数越复杂,模型越偏向于拟合过度。在参数C方面,它可以看作是 Lasso算法中的lambda的倒数,C越大模型越偏向于拟合过度,反之则拟合不足。实际问题中怎么选呢?用人类最古老的办法,试错。
常用的核函数有如下种类:
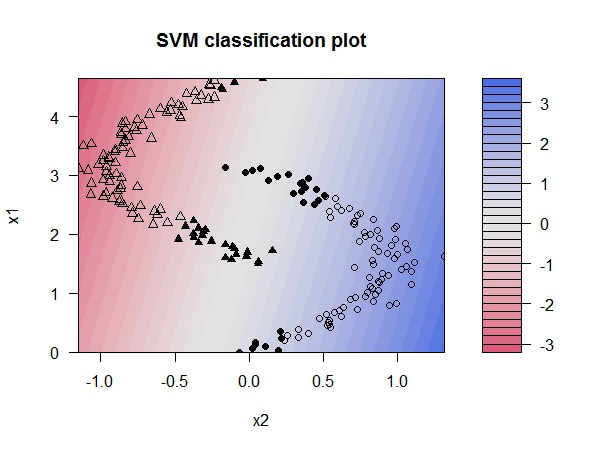
好吧,理论说了一大堆,关键得在R里面出手。R语言中可以用 e1071包 中的 svm函数 建模,而另一个 kernlab包 中则包括了更多的核方法函数,本例用其中的 ksvm函数 ,来说明参数C的作用和核函数的选择。我们先人为构造一个线性不可分的数据,先用线性核函数来建模,其参数C取值为1。然后我们用图形来观察建模结果,下图是根据线性SVM得到各样本的判别值等高线图(判别值decision value相当于Logistic回归中的X,X取0时为决策边界)。可以清楚的看到决策边界为线性,中间的决策边缘显示为白色区域,有相当多的样本落入此区域。
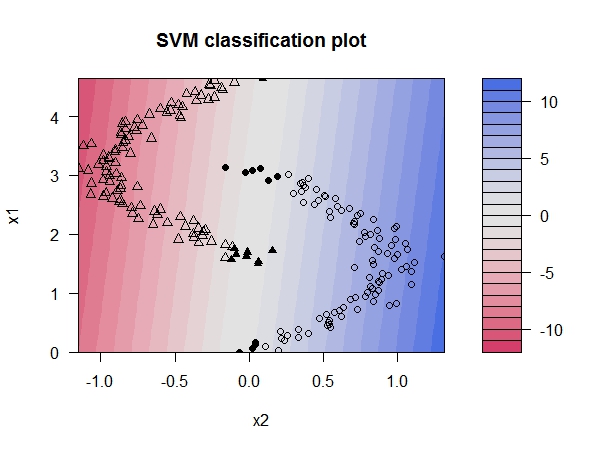
下面为了更好的拟合,我们加大了C的取值,这样如下图所示。可以预料到,当加大惩罚参数后决策边缘缩窄,也使训练误差减少,但仍有个别样本未被正确的分类。
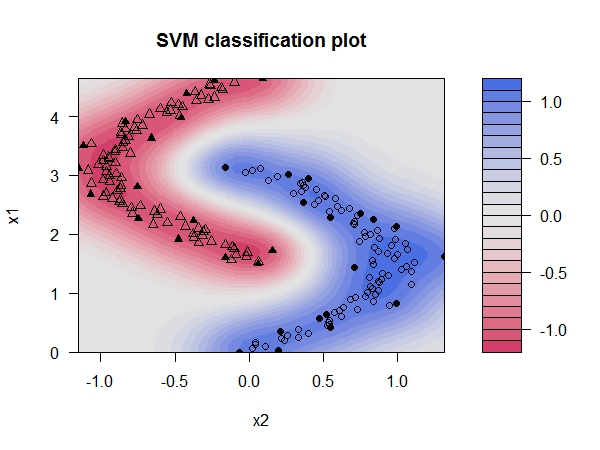
最后我们换用高斯核函数,这样得到的非线性决策边界。所有的样本都得到了正确的分类。
在实际运用中,为了寻找最优参数我们还可以用caret包来配合建模,并且使用多重交叉检验来评价模型。还需要注意一点SVM建模最好先标准化处理。最后来总结一下SVM的优势:
代码如下:
library(caret) library(kernlab) library(e1071) # 构造数据 x1 <- seq(0,pi,length.out=100) y1 <- sin(x1) + 0.1*rnorm(100) x2 <- 1.5+ seq(0,pi,length.out=100) y2 <- cos(x2) + 0.1*rnorm(100) data <- data.frame(c(x1,x2),c(y1,y2),c(rep(1, 100), rep(-1, 100))) names(data) <- c(‘x1‘,‘x2‘,‘y‘) data$y <- factor(data$y) # 使用线性核函数,不能很好的划分数据 model1 <- ksvm(y~.,data=data,kernel=‘vanilladot‘,C=0.1) plot(model1,data=data) # 加大惩罚参数,决策边缘缩窄,使训练误差减小 model2 <- ksvm(y~.,data=data,kernel=‘vanilladot‘,C=100) plot(model2,data=data) # 使用高斯核函数,正确的分类 model3 <- ksvm(y~.,data=data,kernel=‘rbfdot‘) plot(model3,data=data) # 10折交叉检验训练iris数据,选择最优参数C为0.5 fitControl <- trainControl(method = "repeatedcv", number = 10, repeats = 3,returnResamp = "all") model <- train(Species~., data=iris,method=‘svmRadialCost‘,trControl = fitControl)
原文:http://my.oschina.net/dfsj66011/blog/514420