链接http://www.aiuxian.com/article/p-2042151.html
同一个block的threads使用shared memory space 要比global memory快很多,所以只要有机会就把global memory整成shared memory。
例子:matrixmultiply
main()程序
1 // Matrices are stored in row-major order: 2 // M(row, col) = *(M.elements + row * M.width + col) 3 typedef struct { 4 int width; 5 int height; 6 float* elements; 7 } Matrix; 8 9 // Thread block size 10 #define BLOCK_SIZE 16 11 12 // Forward declaration of the matrix multiplication kernel 13 __global__ void MatMulKernel(const Matrix, const Matrix, Matrix); 14 15 // Matrix multiplication - Host code 16 // Matrix dimensions are assumed to be multiples of BLOCK_SIZE 17 void MatMul(const Matrix A, const Matrix B, Matrix C) 18 { 19 // Load A and B to device memory 20 Matrix d_A; 21 d_A.width = A.width; d_A.height = A.height; 22 size_t size = A.width * A.height * sizeof(float); 23 cudaMalloc(&d_A.elements, size); 24 cudaMemcpy(d_A.elements, A.elements, size, 25 cudaMemcpyHostToDevice); 26 Matrix d_B; 27 d_B.width = B.width; d_B.height = B.height; 28 size = B.width * B.height * sizeof(float); 29 cudaMalloc(&d_B.elements, size); 30 cudaMemcpy(d_B.elements, B.elements, size, 31 cudaMemcpyHostToDevice); 32 33 // Allocate C in device memory 34 Matrix d_C; 35 d_C.width = C.width; d_C.height = C.height; 36 size = C.width * C.height * sizeof(float); 37 cudaMalloc(&d_C.elements, size); 38 39 // Invoke kernel 40 dim3 dimBlock(BLOCK_SIZE, BLOCK_SIZE); 41 dim3 dimGrid(B.width / dimBlock.x, A.height / dimBlock.y); 42 MatMulKernel<<<dimGrid, dimBlock>>>(d_A, d_B, d_C); 43 44 // Read C from device memory 45 cudaMemcpy(C.elements, Cd.elements, size, 46 cudaMemcpyDeviceToHost); 47 } 48 49 // Free device memory 50 cudaFree(d_A.elements); 51 cudaFree(d_B.elements); 52 cudaFree(d_C.elements); 53 }
使用Global memory
55 // Matrix multiplication kernel called by MatMul() 56 __global__ void MatMulKernel(Matrix A, Matrix B, Matrix C) 57 { 58 // Each thread computes one element of C 59 // by accumulating results into Cvalue 60 float Cvalue = 0; 61 int row = blockIdx.y * blockDim.y + threadIdx.y; 62 int col = blockIdx.x * blockDim.x + threadIdx.x; 63 for (int e = 0; e < A.width; ++e) 64 Cvalue += A.elements[row * A.width + e]* B.elements[e * B.width + col]; 65 C.elements[row * C.width + col] = Cvalue; 66 }
使用share memory
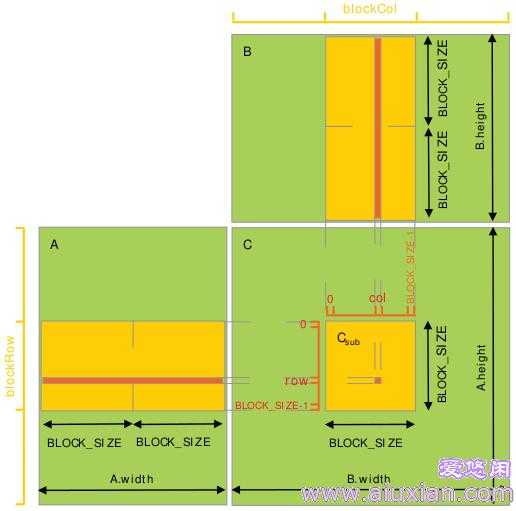
每个thread block负责计算一个子矩阵Csub, 其中每个thread负责计算Csub中的一个元素。如下图所示。为了将fit设备资源,A,B都分割成很多block_size维的方形matrix,Csub将这些方形matrix的乘积求和而得。每次计算一个乘积时,先将两个对应方形矩阵从global memory 载入 shared memory,然后每个thread计算乘积的一个元素,再由每个thread将这些product加和,存入一个register,最后一次性写入global memory。计算时注意同步。
1 __global__ void MatMulKernel(Matrix A, Matrix B, Matrix C) 2 { 3 // Block row and column 4 int blockRow = blockIdx.y; 5 int blockCol = blockIdx.x; 6 7 // Each thread block computes one sub-matrix Csub of C 8 Matrix Csub = GetSubMatrix(C, blockRow, blockCol); //仅仅得到global memory的地址 9 10 // Each thread computes one element of Csub by accumulating results into Cvalue 11 12 float Cvalue = 0; 13 14 // Thread row and column within Csub 15 int row = threadIdx.y; 16 int col = threadIdx.x; 17 18 // Loop over all the sub-matrices of A and B that are 19 // required to compute Csub 20 // Multiply each pair of sub-matrices together 21 // and accumulate the results 22 23 for (int m = 0; m < (A.width / BLOCK_SIZE); ++m) { 24 25 // Get sub-matrix Asub of A 26 Matrix Asub = GetSubMatrix(A, blockRow, m);//仅仅得到global memory的地址 27 // Get sub-matrix Bsub of B 28 Matrix Bsub = GetSubMatrix(B, m, blockCol);//仅仅得到global memory的地址 29 30 // Shared memory used to store Asub and Bsub respectively 31 __shared__ float As[BLOCK_SIZE][BLOCK_SIZE]; 32 __shared__ float Bs[BLOCK_SIZE][BLOCK_SIZE]; 33 34 // Load Asub and Bsub from device memory to shared memory // load 数据一次 35 // Each thread loads one element of each sub-matrix 36 As[row][col] = GetElement(Asub, row, col); 37 Bs[row][col] = GetElement(Bsub, row, col); 38 39 // Synchronize to make sure the sub-matrices are loaded 40 // before starting the computation 41 __syncthreads(); 42 43 // Multiply Asub and Bsub together 44 for (int e = 0; e < BLOCK_SIZE; ++e) 45 Cvalue += As[row][e] * Bs[e][col]; 46 47 // Synchronize to make sure that the preceding 48 // computation is done before loading two new 49 // sub-matrices of A and B in the next iteration 50 __syncthreads(); 51 } 52 53 // Write Csub to device memory 54 // Each thread writes one element 55 SetElement(Csub, row, col, Cvalue); 56 }
注意:
1、使用global memory, A中的每个元素从global memory 读入N次;使用share memory,A中的每个元素从global memory 仅读入 N/BLOCK_SIZE次;
2、thread中的变量,如果没有声明__share__或者__constant__则表示放在thread自己的register中,如果register不够,则放在L1 cache 或者 local memory中。其他threads是不能访问的。
3、如果在变量前加__share__表示将数据放在share memory中,好处,如果一个数据被同一个block中的thread多次访问,放在share memory中,每次从share memory中取数据,比每次去global memory中取数据快很多。
4、例子的share memory的使用如下:
(1、将As[][]声明为share memory变量,放在share memory;
(2、每个thread从global memory load 一个元素放到As[][]中,即放到share memory;
(3、同步。确保As[][]的所有数据都到达share memory,因为下一步是计算,必须确保所有元素都已到达share memory,否则不正确;
(4、同一个block的所有threads开始计算;
(5、同步。因为下一步是重新load 另一块As[][],会覆盖当前As[][]的数据。
5、share memory 可以减少多次从 global memory load数据。记住:share memory的数据计算的时候,还是需要load 到register中,从share memory到register的距离明显比global memory到register的时间少!!
原文:http://www.cnblogs.com/xingzifei/p/4862533.html