试例网站:豆瓣电影TOP250:http://movie.douban.com/top250
关键点:在审查元素下查看后页即可以看到跳转的url。而且最后一页就此属性就没有了。
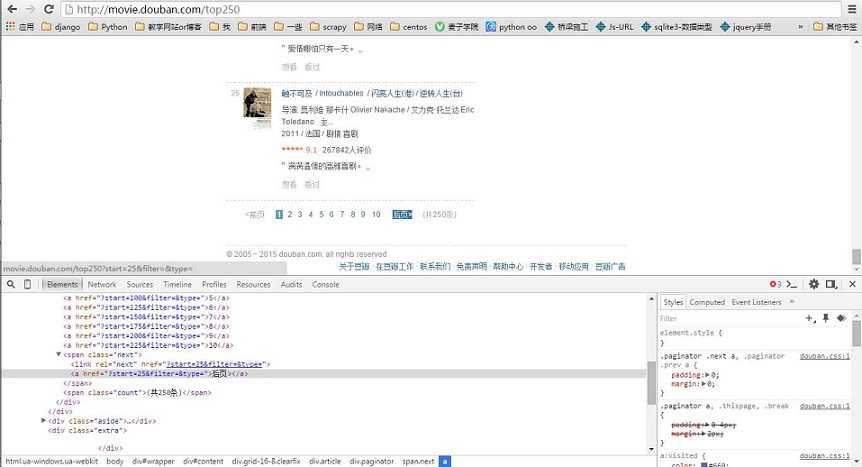
由于关键是实现分页,所以只爬取title:
目录:
items.py:
只需要加一个title就行
dbmspider.py:
1 # -*- coding: utf-8 -*- 2 from dbmovie.items import DbmovieItem 3 from scrapy.contrib.spiders import CrawlSpider 4 from scrapy.http import Request 5 6 7 class TopMovie(CrawlSpider): 8 name = "dbmovie" 9 allowed_domains = ["movie.douban.com"] 10 start_urls=[‘http://movie.douban.com/top250‘] 11 url = ‘http://movie.douban.com/top250‘ 12 def parse(self,response): 13 item = DbmovieItem() 14 Movie = response.xpath(‘//div[@class="info"]‘) 15 for eachMovie in Movie: 16 title = eachMovie.xpath(‘//a[contains(@href,"http://movie.douban.com/subject/")]/span[1]/text()‘).extract() 17 item[‘title‘] = title 18 # print item 19 yield item 20 21 nextLink = response.xpath(‘//span[@class="next"]/link/@href‘).extract() 22 if nextLink: 23 nextLink = nextLink[0] 24 print nextLink 25 yield Request(self.url+nextLink,callback = self.parse)
原文:http://www.cnblogs.com/pengsixiong/p/4909432.html