http://samza.incubator.apache.org/learn/documentation/0.7.0/introduction/architecture.html
Samza由三层组成:
Samza自身提供了对所有三个层的支持:
这三个部分组装到一起构成了Samza:

这个架构遵循了Hadoop的类似模式(使用YARN做为执行层,HDFS做存储,MapReduce做处理层API)

在对这三层的每一层做深入介绍之前,首先要说明下:Samza不仅支持Kafka和YARN。Samza的执行层和消息流层都是pluggable的,并且如果用户喜欢,可以自己实现。
Kafka是一个分布式的发布-订阅以及消息队列系统,提供了at least once的消息保证(也就是说这个系统保证了没有消息会丢失,但是在特定的错误情境下,一个consumer可能会收到多于一次的同一条消息),并且高可用的partition(也就是说一个stream的partition即使在机器down掉的情下仍然可用)。
在kafka,每一个流被称为一个topic。每个topic被分区以备份到多个机器上,这些机器叫broker。当一个producer发送一条消息到一个topic,这个producer提供一个key,来决定这个消息应该被送往topic的哪个partition。Kafka broker接收消息,并且存储消息。Kafka consumer可以通过订阅 这个topic的所有partition来读取这个topic(译注:Kafka consumer可以计阅特定的partition,但是要获取一个topic的所有消息,就得订阅这个topic的所有partition)。
Kafka有一些有趣的属性:
更详细的信息,请看kafka的文档。
YARN(Yet Another Resource Negotiator)是Hadoop的下一代集群调度器。它允许你分派一定数目的 container(进程)到一个集群中,并且在container中执行任意的指令。
当一个应用程序与YARN交互时,看起来就像这样:
Samza使用YARN来管理其部署、容错、日志记录、资源隔离、安全,以及本地化。下面有一个对YARN的简介;这篇Hortonworks的文章做了一个更好的概述。
YARN有三个重要的部分:一个资源管理器ResourceManager、一个NodeManager、一个ApplicationMaster。在一个YARN grid中,每个机器运行着一个NodeManager,NodeManager负责在这台机器上启动进程。ResourceManager告诉所有NodeManager它们应该运行什么。当应用程序想要在集群上运行的时候,它会与ResourceManager来对话。第三个部分,ApplicationMaster,实际上是一段应用程序指定的运行在YARN集群上的代码,它负责管理应用程序的工作负荷,请求获取container(通常是UNIX进程),以及当container出现故障时处理通知。
Samza提供了一个YARN ApplicationMaster和一个自带的YARN job。Samza和YARN的整合用下面的图列出(不同的颜色表示不同的主机)
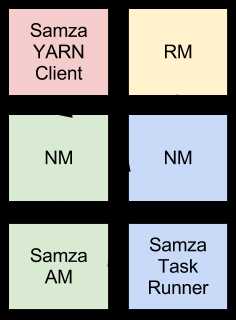
当Samza client启动一个Samza job时,它与YARN RM进行通信。YARN RN告诉一个YARN NM来在集群上给Samza的ApplicationMaster分配空间。当NM分配好空间以后,它启动Samza AM。当Samza AM启动后,它向YARN RM请求一个或更多的 YARN container来运行Samza TaskRunner。然后,RM和NM一起工作,来为containers安排空间。当空间被分配好了,NM启动Samza containers.
Samza使用YARN和Kafka来提供一个框架,用于多级流处理和分区stage-wise stream processing and partitioning。所有东西在一起,看来就样(用不同的颜色表示不同的主机)
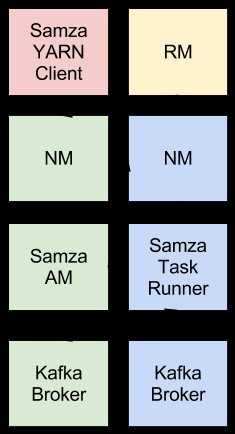
Samza client使用YARN来运行Samza任务。Samza TaskRunners运行在一个或更多的YARN containers,并且执行用户输入的Samza StreamTasks. Samza Stream Task的输入和输出都来自Kafka brokers,这些brokers通常和YARN NMs座落在同样的一些机器上。
让我们来看一下真正的例子:假如我们想要计算页面点击量的总数。使用SQL时,你可能会这么写:
SELECT user_id, COUNT(*) FROM PageViewEvent GROUP BY user_id.
虽然Samza现在不支持SQL,但是思想是一致的。这个查询需机两个job:一个将消息按user ID分组,另一个来做计数。
在第一个job里,把有相同user ID的消息发送到一个中间topic的相同partition里,以此来完成分组。为了做到这些,你可以在第一个job里用user ID做为消息的key,这key被映射到中间topic的一个partition(通过对key做哈希,然后对partition数量求模)。第二个job消费中间的topic。第二个job中的每个task,消费中间topic的一个partition,也就是所有user ID的一个子集对应的所有消息。Task对于分配给它的partition里的每一个用户id有一个计数器,每当这个task收到一个消息时,它就会更新这个消息中的user ID对应的计数器。

如果你熟悉Hadoop,你可能把这个认为是一个Map/Reduce操作,在mapper中,每条记录和一个特定的key关联,有相同key的记录被这个框架组织到一起,然后在reducer中进行计数。Hadoop和Samza的不同在于Hadoop操作于确定的输入,而Samza工作于无界的数据流。
kafka接受第一个job发送的消息,并把它们缓存在磁盘,分布在多个机器中。这样来帮助这个系统的容错:如果机器故障了,没有消息会丢失,因为它们被复制到了其它机器上。如果第二个job工作很慢或者因为某些原因停止消费消息,第一个job也不会受影响:磁盘缓存会吸收第一个job积压的消息直到第二个job追赶上来。
通过topic分区,以及把一个流处理分成在多个机器上运行的job和并行的task,Samza可以扩展到可以流处理非常高的消息吞吐量,通过使用YARN和Kafka,Samza实现容错:如果一个处理或者机器down了,它会自动在另一个机器上重启,并且从上次停下来的点继处理。
下一节:对比介绍
Samza文档翻译 : Architecture,布布扣,bubuko.com
原文:http://www.cnblogs.com/devos/p/3648303.html