R树在数据库等领域做出的功绩是非常显著的。它很好的解决了在高维空间搜索等问题。举个R树在现实领域中能够解决的例子吧:查找20英里以内所有的餐厅。如果没有R树你会怎么解决?一般情况下我们会把餐厅的坐标(x,y)分为两个字段存放在数据库中,一个字段记录经度,另一个字段记录纬度。这样的话我们就需要遍历所有的餐厅获取其位置信息,然后计算是否满足要求。如果一个地区有100家餐厅的话,我们就要进行100次位置计算操作了,如果应用到谷歌地图这种超大数据库中,我想这种方法肯定不可行吧。
R树就很好的解决了这种高维空间搜索问题。它把B树的思想很好的扩展到了多维空间,采用了B树分割空间的思想,并在添加、删除操作时采用合并、分解结点的方法,保证树的平衡性。因此,R树就是一棵用来存储高维数据的平衡树。
好了简介就到此为止。以下,本文将详细介绍R树的数据结构以及R树的操作。至于R树的扩展与R树的性能问题,我就仅仅在文末简单介绍一下吧,这些问题最好查阅相关论文比较合适。
R树的数据结构
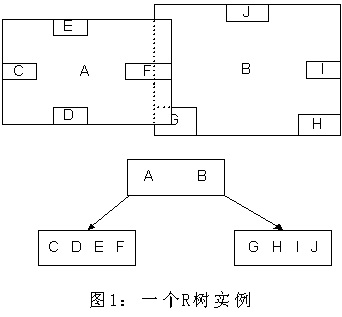
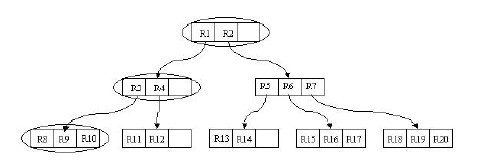
如上所述,R树是B树在高维空间的扩展,是一棵平衡树。每个R树的叶子结点包含了多个指向不同数据的指针,这些数据可以是存放在硬盘中的,也可以是存在内存中。根据R树的这种数据结构,当我们需要进行一个高维空间查询时,我们只需要遍历少数几个叶子结点所包含的指针,查看这些指针指向的数据是否满足要求即可。这种方式使我们不必遍历所有数据即可获得答案,效率显著提高。下图1是R树的一个简单实例:
我们在上面说过,R树运用了空间分割的理念,这种理念是如何实现的呢?R树采用了一种称为MBR(Minimal Bounding Rectangle)的方法,在此我把它译作“最小边界矩形”。从叶子结点开始用矩形(rectangle)将空间框起来,结点越往上,框住的空间就越大,以此对空间进行分割。有点不懂?没关系,继续往下看。在这里我还想提一下,R树中的R应该代表的是Rectangle(此处参考wikipedia),而不是大多数国内教材中所说的Region(很多书把R树称为区域树,这是有误的)。我们就拿二维空间来举例吧。下图是Guttman论文中的一幅图。
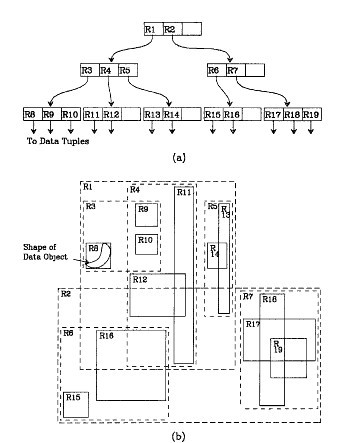
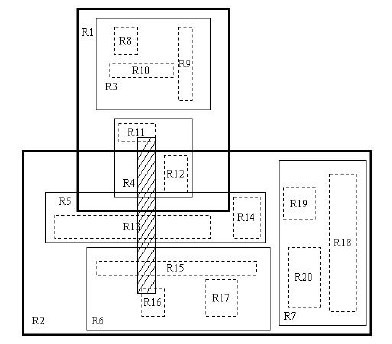
我来详细解释一下这张图。先来看图(b)吧。首先我们假设所有数据都是二维空间下的点,图中仅仅标志了R8区域中的数据,也就是那个shape of data object。别把那一块不规则图形看成一个数据,我们把它看作是多个数据围成的一个区域。为了实现R树结构,我们用一个最小边界矩形恰好框住这个不规则区域,这样,我们就构造出了一个区域:R8。R8的特点很明显,就是正正好好框住所有在此区域中的数据。其他实线包围住的区域,如R9,R10,R12等都是同样的道理。这样一来,我们一共得到了12个最最基本的最小矩形。这些矩形都将被存储在子结点中。下一步操作就是进行高一层次的处理。我们发现R8,R9,R10三个矩形距离最为靠近,因此就可以用一个更大的矩形R3恰好框住这3个矩形。同样道理,R15,R16被R6恰好框住,R11,R12被R4恰好框住,等等。所有最基本的最小边界矩形被框入更大的矩形中之后,再次迭代,用更大的框去框住这些矩形。我想大家都应该理解这个数据结构的特征了。用地图的例子来解释,就是所有的数据都是餐厅所对应的地点,先把相邻的餐厅划分到同一块区域,划分好所有餐厅之后,再把邻近的区域划分到更大的区域,划分完毕后再次进行更高层次的划分,直到划分到只剩下两个最大的区域为止。要查找的时候就方便了吧。
下面就可以把这些大大小小的矩形存入我们的R树中去了。根结点存放的是两个最大的矩形,这两个最大的矩形框住了所有的剩余的矩形,当然也就框住了所有的数据。下一层的结点存放了次大的矩形,这些矩形缩小了范围。每个叶子结点都是存放的最小的矩形,这些矩形中可能包含有n个数据。
在这里,读者先不要去纠结于如何划分数据到最小区域矩形,也不要纠结怎样用更大的矩形框住小矩形,这些都是下一节我们要讨论的。
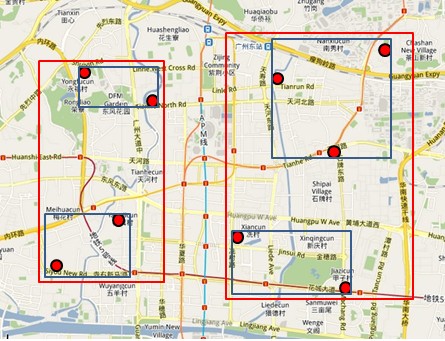
讲完了基本的数据结构,我们来讲个实例,如何查询特定的数据吧。又以餐厅为例吧。假设我要查询广州市天河区天河城附近一公里的所有餐厅地址怎么办?打开地图(也就是整个R树),先选择国内还是国外(也就是根结点)。然后选择华南地区(对应第一层结点),选择广州市(对应第二层结点),再选择天河区(对应第三层结点),最后选择天河城所在的那个区域(对应叶子结点,存放有最小矩形),遍历所有在此区域内的结点,看是否满足我们的要求即可。怎么样,其实R树的查找规则跟查地图很像吧?对应下图:
一棵R树满足如下的性质:
1. 除非它是根结点之外,所有叶子结点包含有m至M个记录索引(条目)。作为根结点的叶子结点所具有的记录个数可以少于m。通常,m=M/2。
2. 对于所有在叶子中存储的记录(条目),I是最小的可以在空间中完全覆盖这些记录所代表的点的矩形(注意:此处所说的“矩形”是可以扩展到高维空间的)。
3. 每一个飞叶子结点拥有m至M个孩子结点,除非它是根结点。
4. 对于在非叶子结点上的每一个条目,i是最小的可以在空间上完全覆盖这些条目所代表的店的矩形(同性质2)。
5. 所有叶子结点都位于同一层,因此R树为平衡树。
叶子结点的结构
先来探究一下叶子结点的结构吧。叶子结点所保存的数据形式为:(I, tuple-identifier)。
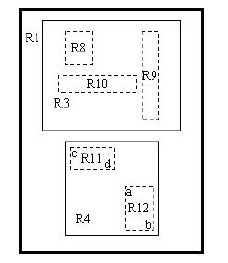
其中,tuple-identifier表示的是一个存放于数据库中的tuple,也就是一条记录,它是n维的。I是一个n维空间的矩形,并可以恰好框住这个叶子结点中所有记录代表的n维空间中的点。I=(I0,I1,…,In-1)。其结构如下图所示:

下图描述的就是在二维空间中的叶子结点所要存储的信息。
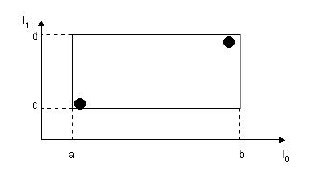
在这张图中,I所代表的就是图中的矩形,其范围是a<=I0<=b,c<=I1<=d。有两个tuple-identifier,在图中即表示为那两个点。这种形式完全可以推广到高维空间。大家简单想想三维空间中的样子就可以了。这样,叶子结点的结构就介绍完了。
非叶子结点
非叶子结点的结构其实与叶子结点非常类似。想象一下B树就知道了,B树的叶子结点存放的是真实存在的数据,而非叶子结点存放的是这些数据的“边界”,或者说也算是一种索引(有疑问的读者可以回顾一下上述第一节中讲解B树的部分)。
同样道理,R树的非叶子结点存放的数据结构为:(I, child-pointer)。
其中,child-pointer是指向孩子结点的指针,I是覆盖所有孩子结点对应矩形的矩形。这边有点拗口,但我想不是很难懂吧?给张图:
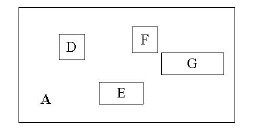
D,E,F,G为孩子结点所对应的矩形。A为能够覆盖这些矩形的更大的矩形。这个A就是这个非叶子结点所对应的矩形。这时候你应该悟到了吧?无论是叶子结点还是非叶子结点,它们都对应着一个矩形。树形结构上层的结点所对应的矩形能够完全覆盖它的孩子结点所对应的矩形。根结点也唯一对应一个矩形,而这个矩形是可以覆盖所有我们拥有的数据信息在空间中代表的点的。
我个人感觉这张图画的不那么精确,应该是矩形A要恰好覆盖D,E,F,G,而不应该再留出这么多没用的空间了。但为尊重原图的绘制者,特不作修改。
R树的操作
这一部分也许是编程者最关注的问题了。这么高效的数据结构该如何去实现呢?这便是这一节需要阐述的问题。
搜索
R树的搜索操作很简单,跟B树上的搜索十分相似。它返回的结果是所有符合查找信息的记录条目。而输入是什么?就我个人的理解,输入不仅仅是一个范围了,它更可以看成是一个空间中的矩形。也就是说,我们输入的是一个搜索矩形。
先给出伪代码:
Function:Search
描述:假设T为一棵R树的根结点,查找所有搜索矩形S覆盖的记录条目。
S1:[查找子树] 如果T是非叶子结点,如果T所对应的矩形与S有重合,那么检查所有T中存储的条目,对于所有这些条目,使用Search操作作用在每一个条目所指向的子树的根结点上(即T结点的孩子结点)。
S2:[查找叶子结点] 如果T是叶子结点,如果T所对应的矩形与S有重合,那么直接检查S所指向的所有记录条目。返回符合条件的记录。
我们通过下图来理解这个Search操作。
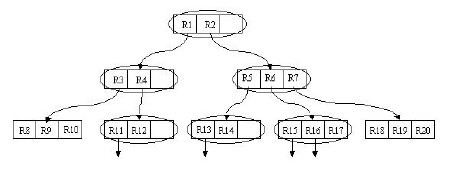
阴影部分所对应的矩形为搜索矩形。它与根结点对应的最大的矩形(未画出)有重叠。这样将Search操作作用在其两个子树上。两个子树对应的矩形分别为R1与R2。搜索R1,发现与R1中的R4矩形有重叠,继续搜索R4。最终在R4所包含的R11与R12两个矩形中查找是否有符合条件的记录。搜索R2的过程同样如此。很显然,该算法进行的是一个迭代操作。
插入
R树的插入操作也同B树的插入操作类似。当新的数据记录需要被添加入叶子结点时,若叶子结点溢出,那么我们需要对叶子结点进行分裂操作。显然,叶子结点的插入操作会比搜索操作要复杂。插入操作需要一些辅助方法才能够完成。
来看一下伪代码:
Function:Insert
描述:将新的记录条目E插入给定的R树中。
I1:[为新记录找到合适插入的叶子结点] 开始ChooseLeaf方法选择叶子结点L以放置记录E。
I2:[添加新记录至叶子结点] 如果L有足够的空间来放置新的记录条目,则向L中添加E。如果没有足够的空间,则进行SplitNode方法以获得两个结点L与LL,这两个结点包含了所有原来叶子结点L中的条目与新条目E。
I3:[将变换向上传递] 开始对结点L进行AdjustTree操作,如果进行了分裂操作,那么同时需要对LL进行AdjustTree操作。
I4:[对树进行增高操作] 如果结点分裂,且该分裂向上传播导致了根结点的分裂,那么需要创建一个新的根结点,并且让它的两个孩子结点分别为原来那个根结点分裂后的两个结点。
Function:ChooseLeaf
描述:选择叶子结点以放置新条目E。
CL1:[Initialize] 设置N为根结点。
CL2:[叶子结点的检查] 如果N为叶子结点,则直接返回N。
CL3:[选择子树] 如果N不是叶子结点,则遍历N中的结点,找出添加E.I时扩张最小的结点,并把该结点定义为F。如果有多个这样的结点,那么选择面积最小的结点。
CL4:[下降至叶子结点] 将N设为F,从CL2开始重复操作。
Function:AdjustTree
描述:叶子结点的改变向上传递至根结点以改变各个矩阵。在传递变换的过程中可能会产生结点的分裂。
AT1:[初始化] 将N设为L。
AT2:[检验是否完成] 如果N为根结点,则停止操作。
AT3:[调整父结点条目的最小边界矩形] 设P为N的父节点,EN为指向在父节点P中指向N的条目。调整EN.I以保证所有在N中的矩形都被恰好包围。
AT4:[向上传递结点分裂] 如果N有一个刚刚被分裂产生的结点NN,则创建一个指向NN的条目ENN。如果P有空间来存放ENN,则将ENN添加到P中。如果没有,则对P进行SplitNode操作以得到P和PP。
AT5:[升高至下一级] 如果N等于L且发生了分裂,则把NN置为PP。从AT2开始重复操作。
同样,我们用图来更加直观的理解这个插入操作。
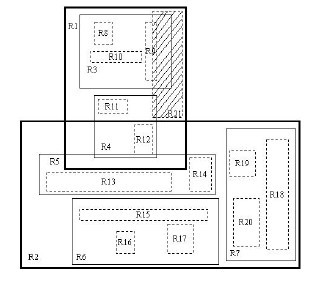
我们来通过图分析一下插入操作。现在我们需要插入R21这个矩形。开始时我们进行ChooseLeaf操作。在根结点中有两个条目,分别为R1,R2。其实R1已经完全覆盖了R21,而若向R2中添加R21,则会使R2.I增大很多。显然我们选择R1插入。然后进行下一级的操作。相比于R4,向R3中添加R21会更合适,因为R3覆盖R21所需增大的面积相对较小。这样就在B8,B9,B10所在的叶子结点中插入R21。由于叶子结点没有足够空间,则要进行分裂操作。
插入操作如下图所示:
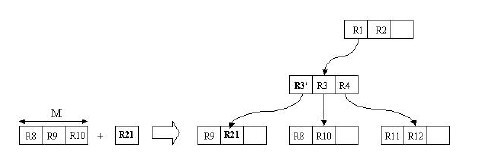
这个插入操作其实类似于第一节中B树的插入操作,这里不再具体介绍,不过想必看过上面的伪代码大家应该也清楚了。
删除
R树的删除操作与B树的删除操作会有所不同,不过同B树一样,会涉及到压缩等操作。相信读者看完以下的伪代码之后会有所体会。R树的删除同样是比较复杂的,需要用到一些辅助函数来完成整个操作。
伪代码如下:
Function:Delete
描述:将一条记录E从指定的R树中删除。
D1:[找到含有记录的叶子结点] 使用FindLeaf方法找到包含有记录E的叶子结点L。如果搜索失败,则直接终止。
D2:[删除记录] 将E从L中删除。
D3:[传递记录] 对L使用CondenseTree操作
D4:[缩减树] 当经过以上调整后,如果根结点只包含有一个孩子结点,则将这个唯一的孩子结点设为根结点。
Function:FindLeaf
描述:根结点为T,期望找到包含有记录E的叶子结点。
FL1:[搜索子树] 如果T不是叶子结点,则检查每一条T中的条目F,找出与E所对应的矩形相重合的F(不必完全覆盖)。对于所有满足条件的F,对其指向的孩子结点进行FindLeaf操作,直到寻找到E或者所有条目均以被检查过。
FL2:[搜索叶子结点以找到记录] 如果T是叶子结点,那么检查每一个条目是否有E存在,如果有则返回T。
Function:CondenseTree
描述:L为包含有被删除条目的叶子结点。如果L的条目数过少(小于要求的最小值m),则必须将该叶子结点L从树中删除。经过这一删除操作,L中的剩余条目必须重新插入树中。此操作将一直重复直至到达根结点。同样,调整在此修改树的过程所经过的路径上的所有结点对应的矩形大小。
CT1:[初始化] 令N为L。初始化一个用于存储被删除结点包含的条目的链表Q。
CT2:[找到父条目] 如果N为根结点,那么直接跳转至CT6。否则令P为N 的父结点,令EN为P结点中存储的指向N的条目。
CT3:[删除下溢结点] 如果N含有条目数少于m,则从P中删除EN,并把结点N中的条目添加入链表Q中。
CT4:[调整覆盖矩形] 如果N没有被删除,则调整EN.I使得其对应矩形能够恰好覆盖N中的所有条目所对应的矩形。
CT5:[向上一层结点进行操作] 令N等于P,从CT2开始重复操作。
CT6:[重新插入孤立的条目] 所有在Q中的结点中的条目需要被重新插入。原来属于叶子结点的条目可以使用Insert操作进行重新插入,而那些属于非叶子结点的条目必须插入删除之前所在层的结点,以确保它们所指向的子树还处于相同的层。
R树删除记录过程中的CondenseTree操作是不同于B树的。我们知道,B树删除过程中,如果出现结点的记录数少于半满(即下溢)的情况,则直接把这些记录与其他叶子的记录“融合”,也就是说两个相邻结点合并。然而R树却是直接重新插入。
同样,我们用图直观的说明这个操作。
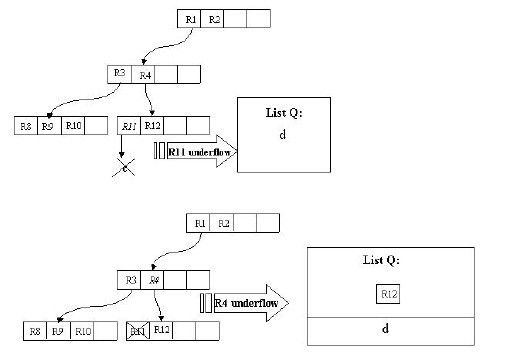
假设结点最大条目数为4,最小条目数为2。在这张图中,我们的目标是删除记录c。首先使用FindLeaf操作找到c所处在的叶子结点的位置——R11。当c从R11删除时,R11就只有一条记录了,少于最小条目数2,出现下溢,此时要调用CondenseTree操作。这样,c被删除,R11剩余的条目——指向记录d的指针——被插入链表Q。然后向更高一层的结点进行此操作。这样R12会被插入链表中。原理是一样的,在这里就不再赘述。
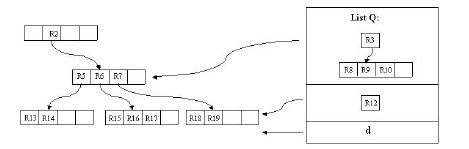
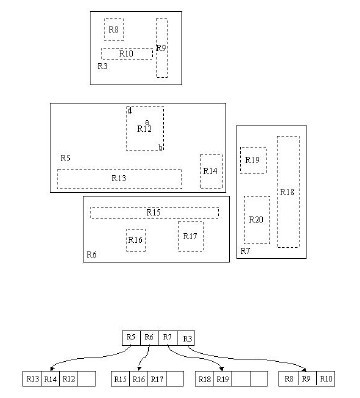
有一点需要解释的是,我们发现这个删除操作向上传递之后,根结点的条目R1也被插入了Q中,这样根结点只剩下了R2。别着急,重新插入操作会有效的解决这个问题。我们插入R3,R12,d至它原来所处的层。这样,我们发现根结点只有一个条目了,我们把这个根结点删除,它的孩子结点,即R5,R6,R7,R3所在的结点被置为根结点。至此,删除操作结束。
2. 平方耗费算法:(时间复杂度为平方的近似算法)
原文:http://www.cnblogs.com/chenying99/p/4922004.html