TF-IDF可以用来评估一个词对文档的重要程度

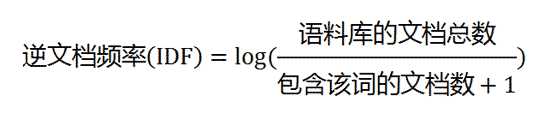
![]()
公式说明了 (某词在文章中出现越多|某词在其他文档出现越少)=>该词对该文档越重要, 一定程度说明了该词是该文档的关键词。
可用于对文档VSM模型化中计算权值,每个文档以各个词为维度构成向量,两文档的相似度可计算其空间向量的夹角余弦值。
根据文档间的相似度,结合机器学习算法(神经网络,KNN,贝叶斯等),可将文档集进行聚类。
但是他的缺点是相似度计算量大,新文档加入时又要重新计算权值。
上面说的是TF-IDF对于(词-文档)这个组合的使用,可用于聚类,但如果用于分类呢?此时变成(词-文档-类别),上述公式也不再适用了
但思想还是可以迁移的嘛(“文档”->“类别”):(某词在某类中出现越多|某词在其他类中出现越少)=>该词对该类越重要
于是学术中就出现了TF-IDF的各种各样的改进公式,如
TF=词在类中出现的次数/语料库总词数
IDF=log(语料库的文档数*类中出现该词的文档数/出现该词的总文档数)
TF-IDF=TF*IDF
这样一来,对于每个类中的词,都可以得到其TF-IDF权值,其权值表示该词对该类的重要程度。
在归一化处理后,我们可以看到,有些词在多个类中出现,对不同的类重要度不一样;有些词只在某类中出现,全部贡献度都在该类上。
例如,有A,B,C类,t1,t2,t3,t4,t5,t6词,每个词对各个类贡献度如下
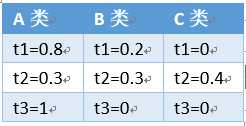
t1出现在A,B两类中,但是出现t1时,更可能是属于A类。
t2出现在三个类中,重要程度也差不多,t2并不怎么具有区分度。
t3只出现在A类中,能很好地识别出A类。
这时候如果有一个新的文档,不知其属于哪个类,如果它具有词t1,t2,t3,累加其对三个类的可能性:2.1,0.5,0.4,则该文本最可能属于类A
当然这只是简单的预测,也可结合文本中词出现的频率去考虑。
但是,当语料库庞大时,词量剧增,这时候就需要文本特征提取,也就是这么多词,有些低频词,区分度不高的词并没什么用,可以去掉,只看一些区分度强的词
这里也有蛮多问题的...暂时还有点模糊,待我多学一点再回来写 _(:зゝ∠)_
以上是我看论文/博客/书+自己的思考,如果有什么写错了的地方,望赐教!
原文:http://www.cnblogs.com/IvanSSSS/p/4944067.html