一、不废话太多 直接进入例子。
1 问题:
CREATE TABLE 收藏表( `id` bigint(20) unsigned NOT NULL auto_increment COMMENT ‘primary key‘, `uid` bigint(20) unsigned NOT NULL default 0 COMMENT ‘uid‘,<br> `status` tinyint(3) unsigned NOT NULL default 0 COMMENT ‘status‘, `book_id` bigint(20) unsigned NOT NULL default 0 COMMENT ‘book Id‘, `create_time` int(11) unsigned not null default 0 COMMENT ‘create time‘, PRIMARY KEY (`id`), UNIQUE KEY `uid_book_id` (`uid`, `book_id`),<br> KEY `uid_status` (`uid`, `status`) )ENGINED=Innodb Auto_increment=1 default charset=gbk COMMENT ‘用户收藏信息‘;最容易想到的第一种分页语句是(这也是我们最容易想到的语句):
|
1
2
|
select distinct uid from 收藏表 order by uid desc limit 0, 10;select distinct uid from 收藏表 order by uid desc limit 11, 10; |
再高级点语句,第二种($last_min_uid表示上一次读到的最后一个uid):
|
1
2
|
select distinct uid from 收藏表 order by uid desc limit 10;select distinct uid from 收藏表 where uid < $last_min_uid order by uid desc limit 10; |
最高级的方式
1 select uid from 收藏表 group by uid order by uid desc limit 10; 2 select uid from 收藏表 group by uid having uid < $last_min_uid order by uid desc limit 10;以上三种方式都可以实现分页获取到用户ID列表,那么区别是什么?我现在就把每一种跟大家分析下。
第一种在业务场景中,会出现丢数据的情况。——这是比较严重的情况,不予采纳。
具体的业务场景是这样的:当你读取第5页的时候,前四页的用户id列表中,假如有一页的用户ID从库中删除掉,那么你这时读到的第5页(limit 51, 10),就是原来的第6页,你会把1页的用户ID丢失掉。
第二种的第二条语句,通过explain分析,实际并没有命中唯一索引,而只是命中了一般索引,数据查询范围在7百万级别,故explain建议我们使用group by。——这个查询会有严重的性能问题。
+----+--------------+---------------+-------+-------------------------------------------------------------+-------------+----------+-------+------------+------------------------------------------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+--------------+---------------+-------+-------------------------------------------------------------+---------------------+---------+------+---------+---------------------------------------------------------------------+
| 1 | SIMPLE | ubook_room | range | uid_book_id | uid_status | 4 | NULL | 7066423 | Using where; Using index for group-by; Using temporary; Using filesort |
+----+--------------+---------------+-------+-------------------------------------------------------------+-------------+----------+-------+------------+------------------------------------------------------------------------+
第三种explain分析,数据查询范围在12万级别(跟第二种相差一个数量级),查询性能高。
+----+---------------+------------+-------+-----------------+-----------------+---------+----------+----------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+---------------+------------+-------+-----------------+-----------------+---------+----------+----------+-------------+
| 1 | SIMPLE | 收藏表 | index | NULL | uid_book_id | 12 | NULL | 121719 | Using index |
+----+---------------+------------+-------+-----------------+-----------------+---------+----------+----------+-------------+
二、 PHP的正则:
正则表达式相信大家在很多种开发语言中都见到过,像javascript,java,php中。
$regex = ‘/^http:\/\/([\w.]+)\/([\w]+)\/([\w]+)\.html$/i‘;$matches = array();if(preg_match($regex, $str, $matches)){ var_dump($matches);}echo "\n"; |
preg_match中的$matches[0]将包含与整个模式匹配的字符串。
使用"#"定界符的代码如下.这个时候对"/"就不转义!
$matches = array();if(preg_match($regex, $str, $matches)){ var_dump($matches);}echo "\n"; |
¤ 修饰符:用于改变正则表达式的行为。
我们看到的(‘/^http:\/\/([\w.]+)\/([\w]+)\/([\w]+)\.html/i‘)中的最后一个"i"就是修饰符,表示忽略大小写,还有一个我们经常用到的是"x"表示忽略空格。
贡献代码:
$regex = ‘/HELLO/‘;$str = ‘hello word‘;$matches = array();if(preg_match($regex, $str, $matches)){ echo ‘No i:Valid Successful!‘,"\n";}if(preg_match($regex.‘i‘, $str, $matches)){ echo ‘YES i:Valid Successful!‘,"\n";} |
¤ 字符域:[\w]用方括号扩起来的部分就是字符域。
¤ 限定符:如[\w]{3,5}或者[\w]*或者[\w]+这些[\w]后面的符号都表示限定符。现介绍具体意义。
{3,5}表示3到5个字符。{3,}超过3个字符,{,5}最多5个,{3}三个字符。
* 表示0到多个
+ 表示1到多个。
¤ 脱字符号
^:
> 放在字符域(如:[^\w])中表示否定(不包括的意思)——“反向选择”
> 放在表达式之前,表示以当前这个字符开始。(/^n/i,表示以n开头)。
注意,我们经常管"\"叫"跳脱字符"。用于转义一些特殊符号,如".","/"
$regex = ‘/(?<=c)d(?=e)/‘; /* d 前面紧跟c, d 后面紧跟e*/$str = ‘abcdefgk‘;$matches = array();if(preg_match($regex, $str, $matches)){ var_dump($matches);}echo "\n"; |
否定意义:
$regex = ‘/(?<!c)d(?!e)/‘; /* d 前面不紧跟c, d 后面不紧跟e*/$str = ‘abcdefgk‘;$matches = array();if(preg_match($regex, $str, $matches)){ var_dump($matches);}echo "\n"; |
$regex = ‘/HE(?=L)LO/i‘;$str = ‘HELLO‘;$matches = array();if(preg_match($regex, $str, $matches)){ var_dump($matches);}echo "\n"; |
打印不出结果!
$regex = ‘/HE(?=L)LLO/i‘;$str = ‘HELLO‘;$matches = array();if(preg_match($regex, $str, $matches)){ var_dump($matches);}echo "\n"; |
能打印出结果!
说明:(?=L)意思是HE后面紧跟一个L字符。但是(?=L)本身不占字符,要与(L)区分,(L)本身占一个字符。
$regex = ‘/^(Chuanshanjia)[\w\s!]+\1$/‘; $str = ‘Chuanshanjia thank Chuanshanjia‘;$matches = array();if(preg_match($regex, $str, $matches)){ var_dump($matches);}echo "\n"; |
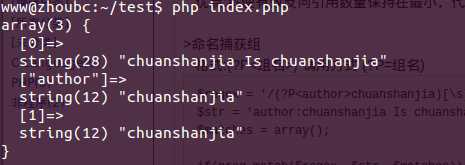
$regex = ‘/(?P<author>chuanshanjia)[\s]Is[\s](?P=author)/i‘;$str = ‘author:chuanshanjia Is chuanshanjia‘;$matches = array();if(preg_match($regex, $str, $matches)){ var_dump($matches);}echo "\n"; |
运行结果
惰性匹配(记住:会进行两部操作,请看下面的原理部分)
格式:限定符?
原理:"?":如果前面有限定符,会使用最小的数据。如“*”会取0个,而“+”会取1个,如过是{3,5}会取3个。
先看下面的两个代码:
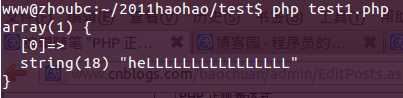
代码1.
<?php$regex = ‘/heL*/i‘;$str = ‘heLLLLLLLLLLLLLLLL‘;if(preg_match($regex, $str, $matches)){ var_dump($matches);}echo "\n"; |
结果1.
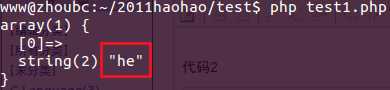
代码2
<?php$regex = ‘/heL*?/i‘;$str = ‘heLLLLLLLLLLLLLLLL‘;if(preg_match($regex, $str, $matches)){ var_dump($matches);}echo "\n"; |
结果2
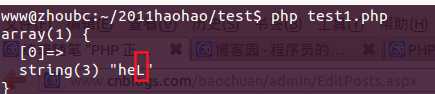
代码3,使用“+”
<?php$regex = ‘/heL+?/i‘;$str = ‘heLLLLLLLLLLLLLLLL‘;if(preg_match($regex, $str, $matches)){ var_dump($matches);}echo "\n"; |
结果3
代码4,使用{3,5}
<?php$regex = ‘/heL{3,10}?/i‘;$str = ‘heLLLLLLLLLLLLLLLL‘;if(preg_match($regex, $str, $matches)){ var_dump($matches);}echo "\n"; |
结果4
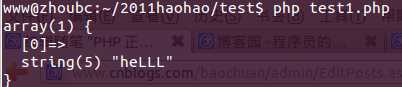
$regex = ‘/ ^host=(?<!\.)([\d.]+)(?!\.) (?#主机地址)\| ([\w!@#$%^&*()_+\-]+) (?#用户名)\| ([\w!@#$%^&*()_+\-]+) (?#密码)(?!\|)$/ix‘;$str = ‘host=192.168.10.221|root|123456‘;$matches = array();if(preg_match($regex, $str, $matches)){ var_dump($matches);}echo "\n"; |
| 特殊字符 | 解释 |
| * | 0到多次 |
| + | 1到多次还可以写成{1,} |
| ? | 0或1次 |
| . | 匹配除换行符外的所有单个的字符 |
| \w | [a-zA-Z0-9_] |
| \s | 空白字符(空格,换行符,回车符)[\t\n\r] |
| \d | [0-9] |
三、PHP一些性能优化问题
|
1
2
3
4
5
6
7
8
9
10
11
|
class dog { public $name = ‘‘; public function setName($name) { $this->name = $name; } public function getName() { return $this->name; }} |
注意:setName()和getName()除了存储和返回name属性外,没做任何工作。
|
1
2
3
|
$rover = new dog();$rover->setName(‘rover‘);echo $rover->getName(); |
直接设置和访问name属性,性能能提升100%,而且也能缩减开发时间!
|
1
2
3
|
$rover = new dog();$rover->name = ‘rover‘;echo $rover->name; |
|
1
2
|
$description = strip_tags($_POST[‘description‘]);echo $description; |
|
1
|
echo strip_tags($_POST[‘description‘]); |
|
1
2
3
4
|
foreach ($userList as $user) { $query = ‘INSERT INTO users (first_name,last_name) VALUES("‘ . $user[‘first_name‘] . ‘", "‘ . $user[‘last_name‘] . ‘")‘; mysql_query($query);} |
过程:
|
1
|
INSERT INTO users (first_name,last_name) VALUES("John", "Doe") |
替换这种循环方案,你能够拼接数据成为一个单一的数据库操作。
|
1
2
3
4
5
6
|
$userData = array();foreach ($userList as $user) { $userData[] = ‘("‘ . $user[‘first_name‘] . ‘", "‘ . $user[‘last_name‘] . ‘")‘; }$query = ‘INSERT INTO users (first_name,last_name) VALUES‘ . implode(‘,‘, $userData);mysql_query($query); |
过程:
|
1
|
INSERT INTO users (first_name,last_name) VALUES("John", "Doe"),("Jane", "Doe")... |
分页查询不知你是否真正的懂和PHP的正则的应用和一些性能优化
原文:http://www.cnblogs.com/newbalanceteam/p/4967132.html