闭包长得像函数,但是闭包不是函数。闭包可以访问函数之外的环境,这不是简单的函数可以做到的。按照这里的定义,闭包更应该是函数与定义函数的环境所组成的实体。可以将闭包与面向对象的对象类比,定义闭包函数的环境(父函数的参数与变量)是属性,闭包函数的方法。闭包是比较特殊的对象,主要是:闭包的生命周期比较特殊,创建闭包的父函数执行完毕,闭包仍然可以存在;对象的核心是数据,而闭包的核心是函数。对象是附有方法的数据,闭包是附有数据的方法。
函数是一等公民,也就是函数可以作为方法的返回值,函数可以被引用,函数可以被用来传值等;
定义内部函数,进而内部函数可以访问父函数的环境,这一特性使得闭包程序程序巧妙、简洁、功能强大而又非常合乎情理。
作为返回值并不是仅仅指的是函数作为“return”的对象,还包括闭包函数作为事件的回调函数,定义全局变量等;
function add(){ //父函数 var sum =4; //自由变量 var func = function (var num) { //内部函数 return sum + num //引用了自由变量 } return func //函数作为返回值 } var addFunc = add() addFunc()
这是一个非常标准的闭包
1 function add(){ 2 var sum =4; 3 var func = function (var num) { 4 return sum + num 5 } 6 func() 7 }
在js里面这也是一个闭包,他可以访问父函数的环境变量,只是生命周期比较特殊,父函数执行完毕,闭包的生命周期就结束了
1 function add(){ 2 war sum =4; 3 func = function (var num) { 4 return sum + num 5 } 6 func() 7 }
在这个例子当中,闭包函数虽然没有被显式的return,但是由于func 没有var关键修饰,所以func 变量是全局变量,全局变量的生命周期直到整个页面文件被销毁才结束,因此,这个闭包的生命周期比父函数要长。这是一种非常不好的变成习惯,使用全局变量会降低程序的执行速度,而且内存得不到及时的释放。
闭包可以使的程序更加简洁优雅,合理的使用闭包有如下的作用:
因为闭包可以访问父函数的成员变量,合理的使用闭包能够减少全局变量的数量。
1 /*不实用闭包*/ 2 //生产者 3 function produce(){ 4 var data = new(...) 5 return data 6 } 7 //消费者 8 function consume(data){ 9 do consume... 10 } 11 var data = produce() 12 13 14 /*使用闭包*/ 15 function process(){ 16 var data = new (...) 17 return function consume(){ 18 do consume data ... 19 } 20 } 21 22 var processFunc = produce() 23 processFunc()
使用闭包可以讲消费者函数作为闭包函数,这样消费者就能直接使用生产者产生的数据,少定义了一个全局变量。至于为什么全局变量访问速度慢,在后面的内存模型会讲到。
之前说过,闭包是一种特殊的对象,通过闭包可以模拟对象的行为。
1 function newObject(){ 2 //私有变量 3 var name = "default"; 4 5 return { 6 getName : function(){ //get 7 return name; 8 }, 9 setName : function(newName){ //set 10 name = newName; 11 } 12 } 13 }(); 14 var object = newObject() 15 print(object.name);//直接访问,结果为undefined 16 print(object.getName()); 17 object.setName("newName"); 18 print(object.getName());
这个例子模拟了对象的get与set方法。通过闭包,实现了对object内部变量的封装,只能通过闭包定义的内部函数访问object
1 var object1 = newObject() 2 object1.setName("object1") 3 4 var object2 = newObject() 5 object2.setName("object2")
面向对象的编程语言都提供类的机制,不同对象有不同的属性,表示不同的状态。上面的例子实现了面向对象中的对象。
js闭包函数可以访问不属于自己的变量,主要是因为闭包函数的存储机制比较特殊。
主要是参考这里,里面的例子做了少许的修改
首先了解一下普通函数从创建到执行一直到消亡内存的变化过程。通过这个过程,可以解决有关于变量的作用域、重名变量的问题
function add(num){ var sum = 5; return sum + num; }
js函数也是对象,对象拥有自己的属相。scope属性是每个函数都有的属相,这个属性只供js引擎使用。scope属性指向了一个链表(scopeChain),scopeChain保存了函数被创建的时的全局变量。
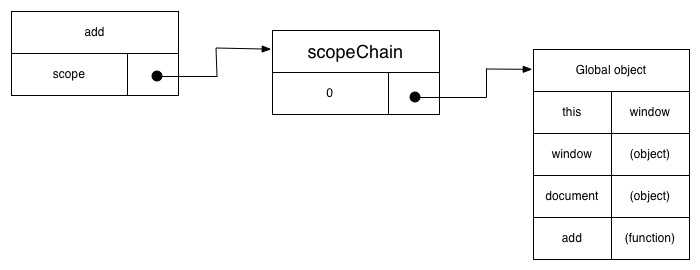
在add函数创建的时候,scopeChain中index为0的引用指向的是Global Object,global object保存的是函数创建的时候全局变量。注意,此时函数还没有被执行
var sum = add(4)
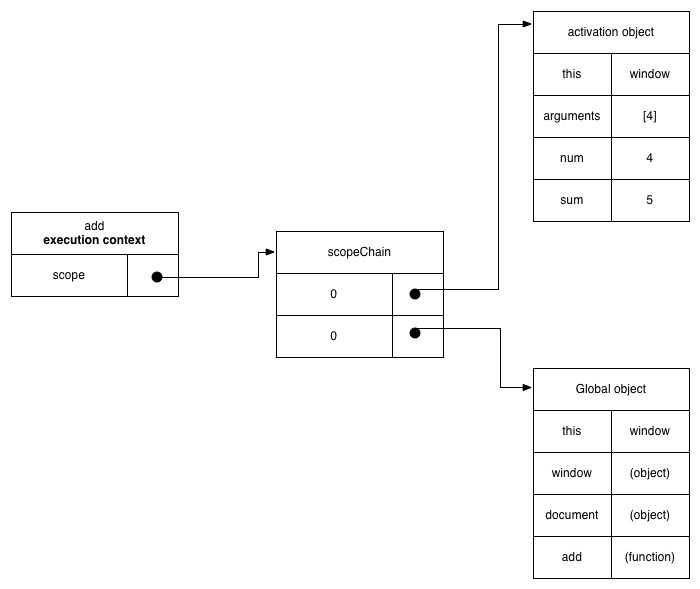
函数被创建之后才能被执行。函数执行时,会创建一个运行时上下文(execution context),这个运行时上下文做两件事情:
1.运行时上下文会创建自己的scopeChain,然后将创建时的scopeChain中的globalObject拷贝过来
2.创建activation object(活动对象),活动对象的作用是记录函运行时的形参实参与定义的局部变量,然后将活动对象插入到运行时上下文的scopeChain中index为0的位置。每当函数执行过程中遇到变量时,先去搜索活动对象,也就是局部变量,然后再去搜索全局变量。
1 function add(){ 2 var sum =5; 3 var func = function (var num) { 4 return sum + num 5 } 6 return func() 7 } 8 var addFunc = add() 9 addFunc(4)
父函数执行的时,js引擎发现在函数的内部定义了函数,闭包函数也是函数,也需要为闭包函数记录创建时的上下文,比较特殊的是,此时的父函数处于执行期,父函数的执行期上下文还没有被销毁,刚好,闭包函数就直接引用了父函数的执行器上下文。
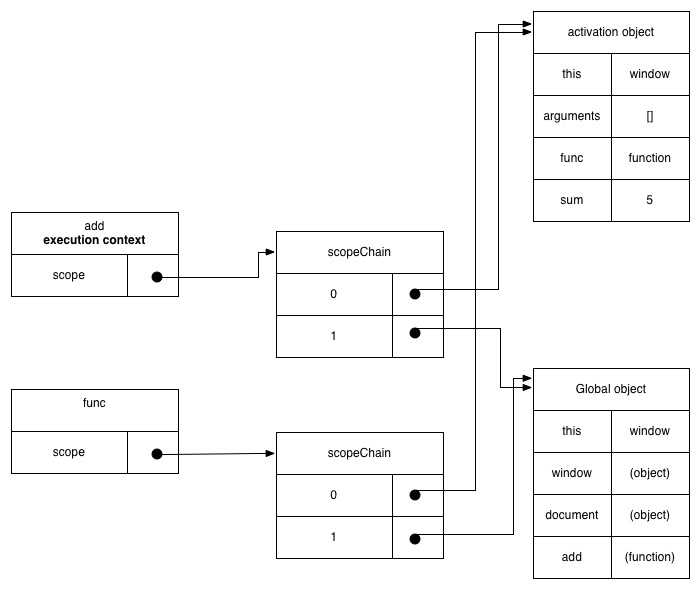
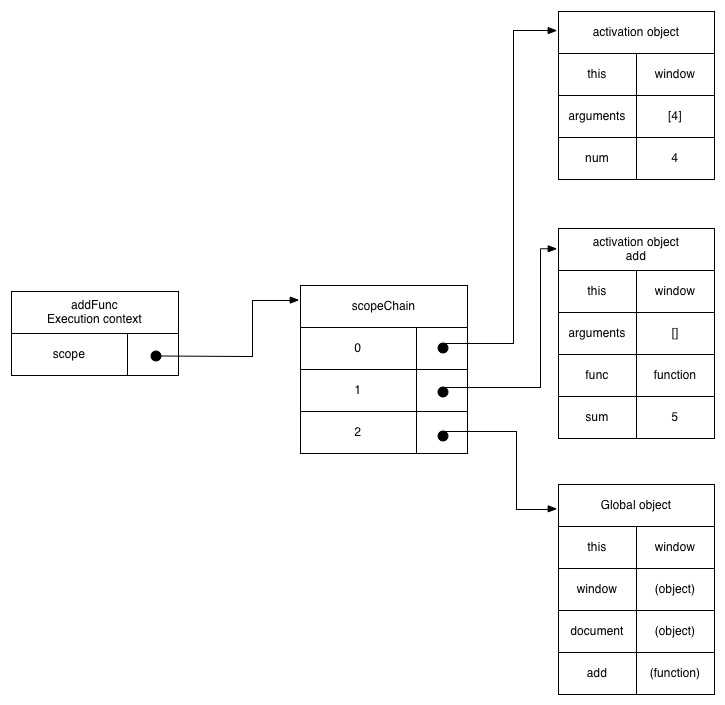
闭包函数执行的时候会创建自己的运行时上下文,然后将自己的形参实参局部变量包装成活动对象,然后将这个活动对象加到scopeChain的index为0的位置。
根据这个过程,我们可以解释为什么闭包函数可以访问自身的参数与局部变量,父函数的环境以及全局变量。闭包函数遇到一个变量的时候,会从上到下由内而外的搜索变量,因此,尽量将变量定义成局部变量,定义成局部变量可以提高访问速度,局部变量会被gc及时的释放,不会长期的占用内存。闭包能够访问反函数是因为闭包保存了父函数的环境变量的引用。没有内存,就没有闭包。
http://coolshell.cn/articles/6731.html 这里有一些有意思的js闭包的例子,能够更好的理解闭包的内存
刚接触js,团队内部做技术分享,时间仓促,对于闭包的理解会有很多不正确的地方。
1.举例详细说明javascript作用域、闭包原理以及性能问题
2.https://www.ibm.com/developerworks/cn/linux/l-cn-closure/
原文:http://www.cnblogs.com/walter-white/p/4981151.html