python有各种库的支持,写起爬虫来十分方便。刚开始学时,使用了标准库中的urllib, urllib2, re,还算比较容易,后来使用了bs4和requests的组合,感觉就更加方便快捷了。
urllib用于封装HTTP post的数据,urllib2用于设置请求和获取返回数据,re用于从返回数据中提取自己想要的结果。我的python版本是2.7,2.x默认编码是ascii,会遇到很多编码问题,各个网页的编码也不尽相同,我们需要根据实际情况进行decode 和encode ,以下我写的第一个爬虫:
1 # coding:utf-8 2 import urllib 3 import urllib2 4 import re 5 6 #请求地址 7 url = ‘http://www.chinagscourt.gov.cn/WebSearch/result.htm?site=lanzhou‘ 8 #设置请求头部 9 user_agent = ‘Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)‘ 10 headers = {‘User-Agent‘: user_agent} 11 #封装post的数据 12 values = {‘keyWord‘: ‘什么‘.decode(‘utf-8‘).encode(‘gbk‘)} 13 data = urllib.urlencode(values) 14 #设置正则匹配模式 15 pattern = re.compile(‘<div class="list_tit">.*?<a href="(?P<url>.*?)".*?title=(?P<title>.*?)>‘,re.S) 16 try: 17 #设置请求 18 request = urllib2.Request(url, data, headers=headers) 19 #打开请求,获取返回结果 20 response = urllib2.urlopen(request) 21 content = response.read().decode(‘gbk‘).encode(‘utf-8‘) 22 #匹配得到想要的数据 23 items = re.findall(pattern,content) 24 25 except urllib2.URLError, e: 26 if hasattr(e, "code"): 27 print e.code 28 if hasattr(e, "reason"): 29 print e.reason 30 #写入文件 31 with open("item.txt","w") as f: 32 for item in items: 33 f.write(item[0]+‘;‘+item[1]+‘\n‘)
以下是执行后,item.txt中的结果:
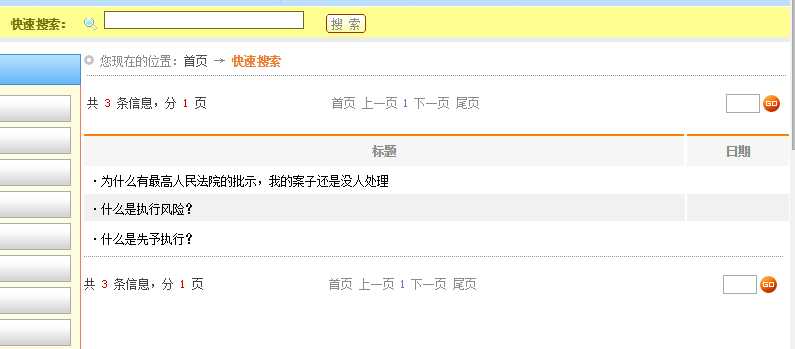
1 ../zyDetail.htm?id=924739;"为什么有最高人民法院的批示,我的案子还是没人处理" 2 ../zyDetail.htm?id=152422;"什么是执行风险?" 3 ../zyDetail.htm?id=152426;"什么是先予执行?"
对比网页结果:
原文:http://www.cnblogs.com/AlexLin/p/4985789.html