这是之前学习编译原理过程中做下的笔记。
因能力有限,在很多地方都理解不到位,特别是对于词法分析与语法分析的过程感觉特别晦涩。
分享这个笔记也是为了自己做个总结,算是一个小的提纲吧,都没怎么深入解析编译的过程。
等以后领悟更多了再作补充吧。
希望各路人士能多加指点,谢谢。
词法分析
作用:将输入转换为一个一个的token,而其用一串整数来表示。
协作:只有当解析器需要的时候才会请求词法分析器,继续扫描输入流,在这个过程中将不断生成符号表。
实现:在通常的编程语言中,相对于不确定的有限自动机(NFA),确定的有限自动机(DFA)中不会有过多的记号使得状态数达到指数级。所以可以为每个NFA构造等价的DFA,而且最关键的是有限自动机的状态数,而在没有不确定状态的情况下,就要求DFA将每个不确定的状态转换成从起始到终结状态间的路径,而这可能会导致增加DFA的状态数。而在多数情况下,设计NFA要简单些,如可通过正则表达式构建,步骤是先分解正则表达式为简单的子表达式,并构造相应的NFA,再通过正则的运算符组合他们。
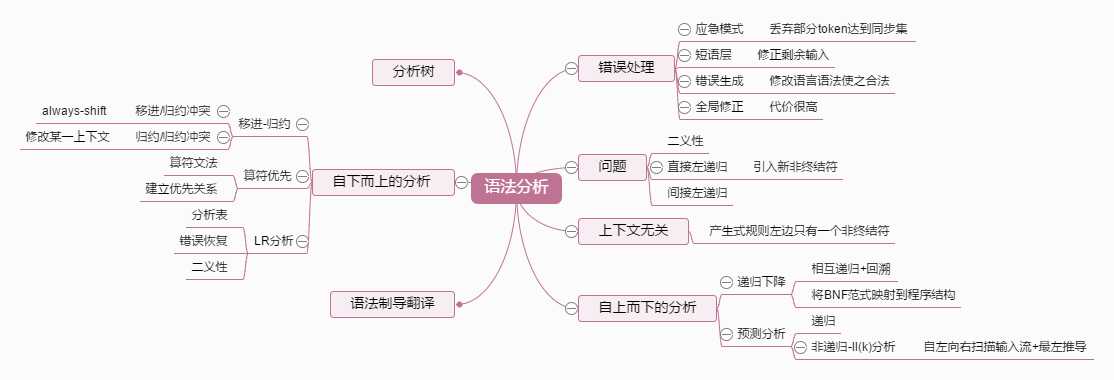
语法分析
部分概念解析
移进-归约(shift-reduce)解析器
其中有包括待解析短语的输入流+存放终结符以及之前归约产生的非终结符的堆栈。
移进操作等于将符号从输入移动到堆栈中;
归约操作则结合已完成的序列和最后移进的终结符形成堆栈中的非终结符;
算符文法
文法中的任一产生式规则右边不存在“空”或者两个连续出现的非终结符;
错误恢复
当前栈顶的终结符和输入的下一个符号之间没有任何优先关系:只允许移进下一个输入的字符,提前为优先表中的空白项指定恢复过程。
没有任何产生式的右句型可以匹配当前的句柄:从合法规则中选择近似的值,再报告差异错误;
LR分析
LR分析器一直追踪着句柄的活前缀,并使用自动机来识别这些活前缀,其中的一些工作呗goto部分模拟了,所以不需要扫描堆栈中的每个输入字符来判断当前的状态,因为状态始终都是在栈顶。
类型检查
类型检测
包括表达式,语句,函数;
第一次是关于操作数运算符的适用性;
第二次是检查需要确定使用的变量的定义;
类型等价
名称等价
结构等价:构造函数
类型转换
当强制转换类型时,只是在那个局部转换,原来的类型保持不变;
符号表
内容:名称,类型,位置,作用域,其他属性
嵌套的词法作用域
每个作用域单独一张表:堆栈/列表/树/hash
单个全局表: 使用列表时需要额外的符号位来表示作用域;树的话新符号都是在叶子端,删除也要遍历;hash存根节点;
当存放记录项(对象)时,要访问记录项(对象)的不同字段(属性),如R.a和R.b可以通过包含a,b定义的符号表来访问;也可以将其看做R.a和R.b来访问;
运行时环境管理
活动记录:参数空间,簿记(bookkeeping)信息包括返回地址,局部变量空间,局部临时变量空间;
含有局部过程的环境:
访问变量的定义相对于当前的过程是局部的,所以要查看嵌套过程的活动记录来决定;
这可以通过访问链来解决;
首先计算出声明和引用的两个词法嵌套层之间的差异d;
再沿着d的访问链到达正确的活动记录;
通过偏移量来访问变量。
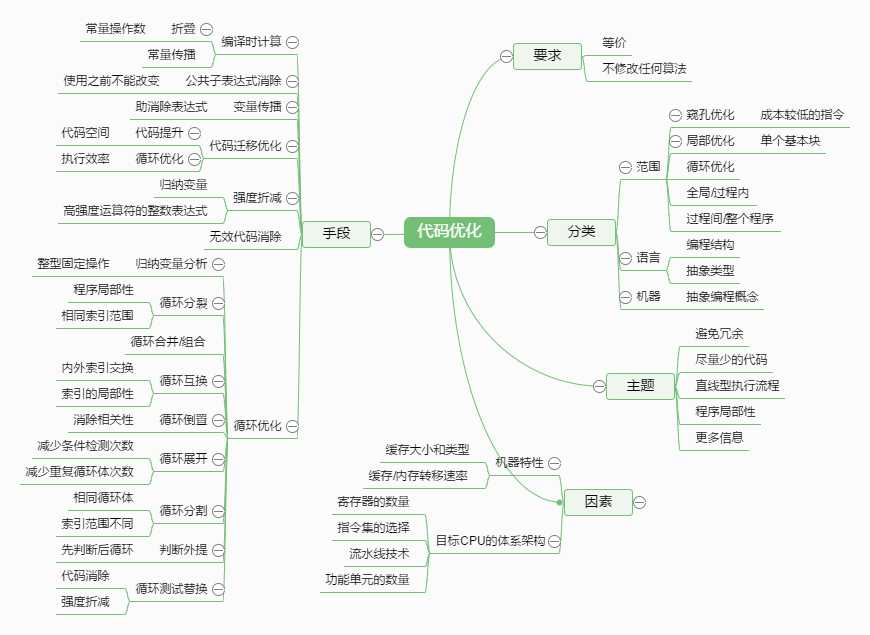
优化
而在搜索访问链的时候,由于是虚拟的页面环境,可能会因为页面交换而变得十分缓慢,为了可以不搜索,可以使用display。
display是活动记录的全局指针数组,d[i]指向嵌套深度为i的代码块中最近的活动;
所以要访问非局部变量X,只要最靠近X嵌套声明的深度为i,则d[i]指向包含X的活动记录,再根据相对地址就可以访问X了。
中间代码生成
高级表示
抽象语法树
有向非循环图:公共子表达式由单个节点构成
P-代码:用于基于堆栈的虚拟机
低级表示
三地址代码
实现:四元组表示法
代码生成:对于非终结符E,分别用不同属性保存E的值的名称,和对应计算的三地址语句序列;
数组:一维:(base-low * w)+i * w;(w是每个元素的宽度);二维:base+((i1 - low1) * n2 + i2 - low2) * w;
布尔类型:为解决两阶段生成代码问题,引入truelist, falselist和相应creatlist(i), mergelist(list1,list2), backpatch(list,target)函数;
case:当分支数量较少时可使用线性查找/二分查找;多则使用转移表,若分支值不紧密聚集,空间成本会更高;
函数调用
目标代码生成
影响因素
输入的匹配程度,即中间代码与目标代码的映射程度;
目标代码的结构:绝对代码,可重定位,汇编;
指令集的选择:CISC, RISC;
寄存器分配:数据+地址;
求值次序:使用寄存器的数目;
基本块:程序的第一个语句;转移目标;紧跟在转移语句之后的语句;
寄存器分配
无向寄存器冲突图;
图着色;
k可着色图:选取边数少于k的节点t,将t压栈并从图中删除它和它的所有邻接边,重复直至所有节点删除;
k不可着色图:
必须选择节点溢出到内存,需要时再载入分配;
如何选取:冲突最大的;定义和使用很少的;尽量不在循环体内的;
使用动态规划生成;
代码优化
了解编译原理-笔记小结
原文:http://www.cnblogs.com/annsshadow/p/4986928.html