延续之前的用R语言读琅琊榜小说,继续讲一下利用R语言做一些简单的文本处理、分词的事情。其实就是继续讲一下用R语言读书的事情啦,讲讲怎么用它里面简单的文本处理方法,来优化我们的读书体验,如果读邮件和读代码也算阅读的话。。用的代码超级简单,不涉及其他包
这里讲两个示例,结尾再来吐槽和总结。
1)R-Blogger订阅邮件拆分
2) R代码库快速阅读方法
不在博客园上阅读时才会看到的,这篇博文归 http://www.cnblogs.com/weibaar所有
仅保证在博客园博客上的排版干净利索还有代码块与图片正确显示,他站转载请保留作者信息尊重版权啊
这个案例用的文本数据来自于R-Blooger网站。R-Blogger是一个专门收集和发布与R语言相关文章的地方。它提供一个每日邮件订阅功能,会把今天好的文章,直接发到你邮箱去。本身网站是不用FQ就可以上的,但是订阅的确认邮件却要求FQ后才能上(基于google)
我之前批量订阅了快半年吧,最开始的时候还每天都瞅瞅,但是它一封邮件信息量有些大,而且有些文章不太感兴趣,渐渐就兴趣转移,累计了一堆未读的在里面。
我们可以利用outlook软件来批量获得这些邮件的文本。(outlook,选中所有R-Blogger邮件,另存为,即可把所有邮件存到一个txt文件里)
接下来是代码示例。
源数据文本文件请在这里下载:
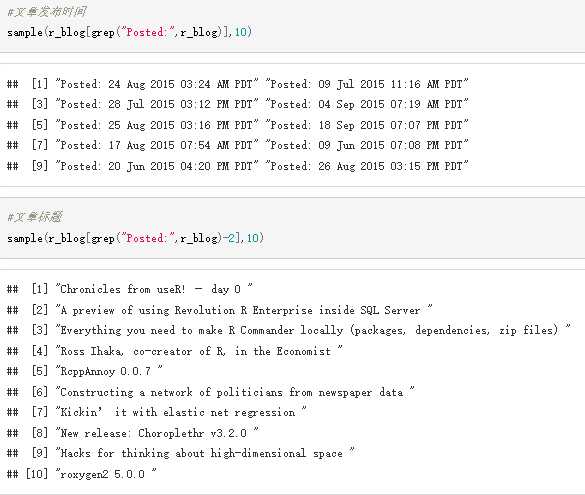
1 #1、读取数据 2 r_blog<-readLines("F:/R/R-ReadBooks/R-blogger.txt") 3 r_blog[20:30] 4 5 #2、以posted为定位条件,分别提取出文章的时间、标题、作者等关系 6 #文章发布时间 7 sample(r_blog[grep("Posted:",r_blog)],10) 8 #文章标题 9 sample(r_blog[grep("Posted:",r_blog)-2],10) 10 #文章作者 11 sample(r_blog[grep("Posted:",r_blog)+3],5) 12 13 #3、根据上述信息,按文章拆分长文本(4.5M) 14 15 #4、以library为条件,看看最近流行什么库 16 library_list<-strsplit(r_blog[grep("^library\\(",r_blog)],"\\(|\\)|\\,") 17 library_list<-sapply(library_list,function(e) e[2]) 18 library_list<-gsub("\\p{P}","",library_list,perl=TRUE) 19 a<-sort(table(library_list),decreasing = TRUE) 20 #最流行 21 head(a,20) 22 23 #5、以github+http为条件,选出邮件里涉及到的所有github地址 24 url_raw<-r_blog[grepl("\\<http.*\\>",r_blog) &(!grepl("\\.jpg|\\.png",r_blog))] 25 url_list<-sapply(strsplit(url_raw,"<|>"),function(e) e[2]) 26 url_list<-unique(url_list[!is.na(url_list)]) 27 sample(grep("github",url_list,value=TRUE),10)
样图:

刚刚已经提到,R语言可以处理一些简单的文本。那么我们扩展一下来想,代码.R,为什么不能也被视为是我们要处理的文本,按之前的逻辑,去扫一下里面的文本数据?
尤其是在大家都说要多写代码,多看别人的代码,多积累代码功能块,但每次打开别人的代码,都对那成千上百的英文望而生畏,用程序去处理代码块,是否能得出一些规律,从更加客观敏捷的角度,做一些统计和分析呢?
源数据来源于这本书: 《机器学习:实用案例解析》
该书代码的github地址如下,可直接下载:
https://github.com/johnmyleswhite/ML_for_Hackers
请看代码示例。
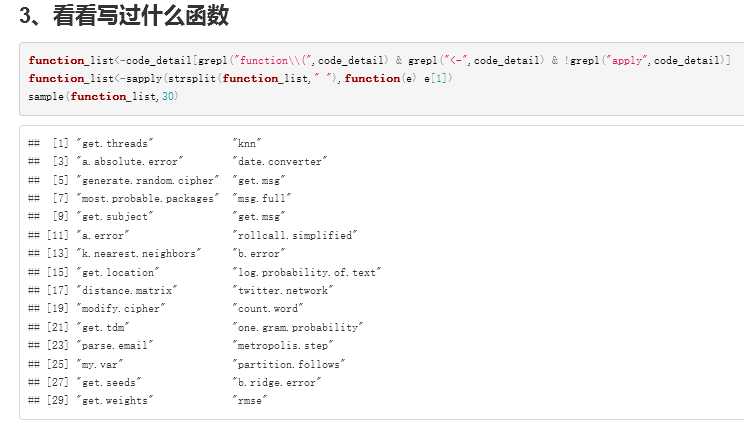
1 #1.读入原始数据,确实可以如文本一样一行行读入,这里需要遍历的方法读入数据,因为文件夹里不止一个R文件 2 fileslist<-list.files("F:/Code/ML_for_Hackers-master/",recursive = TRUE,pattern="\\.R$",full.names = TRUE) 3 code_detail<-NULL 4 for (i in 1:length(fileslist)){ 5 code_detail<-c(code_detail,readLines(fileslist[i])) 6 } 7 8 #2、看看用了什么R包 9 library_list<-strsplit(code_detail[grep("^library\\(",code_detail)],"\\(|\\)|\\,") 10 library_list<-sapply(library_list,function(e) e[2]) 11 library_list<-gsub("\\p{P}","",library_list,perl=TRUE) 12 a<-sort(table(library_list),decreasing = TRUE) 13 a 14 15 #3、看看注释占总代码行的多少 16 zhushi<-code_detail[grep("#",code_detail)] 17 length(zhushi)/length(code_detail) 18 #这里约占30% 19 20 #4、看看自定义了什么函数 21 function_list<-code_detail[grepl("function\\(",code_detail) & grepl("<-",code_detail) & !grepl("apply",code_detail)] 22 function_list<-sapply(strsplit(function_list," "),function(e) e[1]) 23 sample(function_list,30)
那么现在来总结一下三个样例的特点。
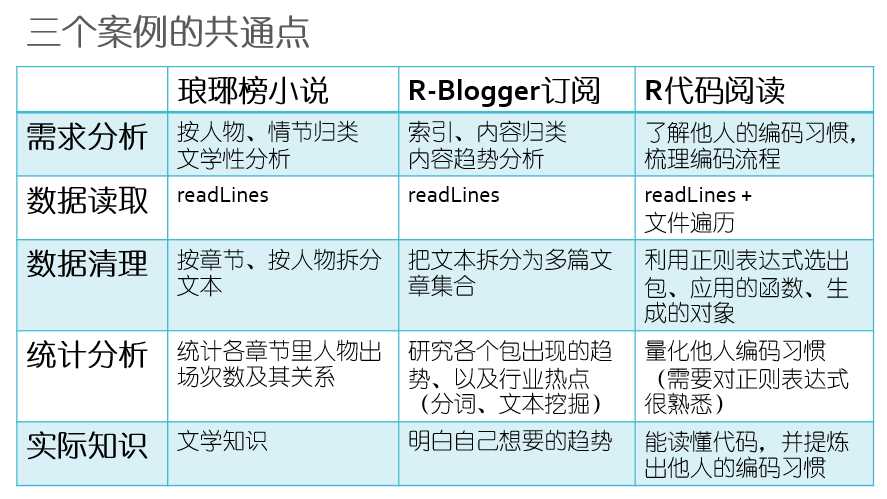
如果用一个数据分析的框架去套的话,他们都符合需求分析、获取数据、处理数据、分析再整合数据等等一套基本流程。其实这个也是我们日常做分析也好,搞报表也好都要遵循的一套定理。
而且用这几类文本数据入门R语言的数据处理与分析流程,也能很好地保持住学习者的兴趣。
当年我学R时最大的痛苦就是,在coursera JHU的R课里,老师总是喜欢用各种社会统计数据,天气数据,生物数据给我们举例子。但是这些数据一来专业性太强,二来多为欧美社会的数据,用起这些数据时总觉得非常痛苦。
所以当我之前弄那个R语言看琅琊榜小说时,我发现这些数据才是我们日常都感兴趣的,学来确实可以用的,每个人都有自己的一套分析技法的,你可以很轻易得去设计一套数据分析流程,获得一个推论和结论的数据。而且这些方法用得好,我们的阅读体验、读书体验会有很高的提高,且加速了知识积累归类的过程。
我们周围都充斥着数据,为什么不能把文本也看成是另类的一种数据呢?一个合格的想往处理数据方向走的人,至少要在生活里随时随地能发现文字背后的奥秘与数字吧?
另外,需要指出的是:
像读琅琊榜小说,我们要关注的是以【人物】来串联【情节】,以及人物与人物的关系,所以如text[gerpl(“飞流”,text) & grepl(“蔺晨”,text)]这样的多条件筛选就比比皆是
而对于R-blogger,因为这个数据来自于多个作者,且有时间跨度,如何有效地选出这些作者,然后如何去决定哪些内容对我们有用,在时间变换下人们关注趋势有什么变化,这些处理就更加重要了。甚至要设计一些分词、文本挖掘、频率统计的内容。
不在博客园上阅读时才会看到的,这篇博文归 http://www.cnblogs.com/weibaar所有
仅保证在博客园博客上的排版干净利索还有代码块与图片正确显示,他站转载请保留作者信息尊重版权啊
而对于代码的甄选,我们要熟练掌握正则表达式,能够在多个{},()中选出一些共通的东西,还要把那些乱命名的变量通通筛选出来,抛离掉,只留下函数啊、技术的关键应用点。这里更多考察的是取数的能力,因为它不像前两个案例的文本那么规整易取。
仅仅只是这里指的三个简单的案例,他们的处理方法就大相径庭,而且如果弄小说不懂人物带动情节,看订阅没有自己的看邮件习惯,甚至不懂代码的话,也没办法对上面的数据做进一步的处理。
所以熟悉业务,不仅仅是熟悉业务数据的特点,也要熟悉业务的需求,自己能找出一些可以深入的点来继续挖掘
这里有一些畅想:
从文本处理的角度,当我们要背单词时,为什么不能找一部美剧或电影的字幕,导入R里面,然后匹配一下雅思托福词汇,或者单词本,把要背的单词所在的段落全部选出来阅读?(灵感来源:书《单词社交网络》)
然后以前那些编写汇总集、梳理角色关系十分痛苦的编辑工作,是否可以用一个简单的代码程序替代,让人从无意义的翻找典故里解脱出来,更加专注于对内部逻辑的思考?不再需要人工去剪切网页、摘抄报纸,一切的一切,就只是记关键词与出处?(我们中学时要看的那些经典诗词解析)
然后对于一个网站的运营,如那些经常要关注敌方上什么促销的运营来说,是否可以简单弄个爬虫,定期给自己推送其他家的价格促销,从而了解他们的运营策略?(其实现在若干大电商都在做,但工具下放到运营自身的,还没有那么多)
如果写剧本的,要经典桥段可以自己写个程序把想要的意境从成千上万本剧本小说里摘出来看看,那效率该有多大提高啊,只需要学会一点点小编程,我们就可以把自己从重复性劳动中解放出来,去做真正有价值的事情时,我觉得这才是非计算机人士业余学编程最有价值的地方。
顺便,最近在用codecademy刷python课程,感谢这世界上总是有人愿意把一个枯燥的编程学习过程做的像打游戏那么生动有趣实时可互动。越多人做这些编程推广的事情,就会有越多人能自如编写比本文提到那些文本处理更复杂的程序脚本,编程的门槛是越来越低了。
---
最后就是,多读书,多看看。。当初写这些代码本质上是想要阅读得快一点,记得牢一点,整理东西快一点,绝对不是为了积累资料而不看书的。如果辛辛苦苦写了个代码帮我们把所有感兴趣的文字都取了出来,却什么也不看,这跟做数据分析不愿意跟那些业务打交道了解实情的傻子有啥区别呢。。。
顺便附上用R玩过的其他事情,欢迎吐槽:
PS又PS:
这文加用R语言读琅琊榜小说一起,是之前为一个演讲准备的演示材料,不过当时太紧张了,还准备一些别的东西然后最后忘记讲了哈哈哈哈——结论是如果上台讲话,一定要把想讲的东西写个小抄,或者放在PPT的要点里,不然铁定忘记= =
终于赶在11月底完成了2015每月一博的任务。。。
原文:http://www.cnblogs.com/weibaar/p/5005591.html