This documentation is for Apache Flink version 1.0-SNAPSHOT, which is the current development version of the next upcoming major release of Apache Flink.
Apache Flink is an open source platform for distributed stream and batch data processing. Flink’s core is a streaming dataflow engine that provides data distribution, communication, and fault tolerance for distributed computations over data streams. Flink also builds batch processing on top of the streaming engine, overlaying native iteration support, managed memory, and program optimization.
If you want to write your first program, look at one of the available quickstarts, and refer to the DataSet API guide or the DataStream API guide.
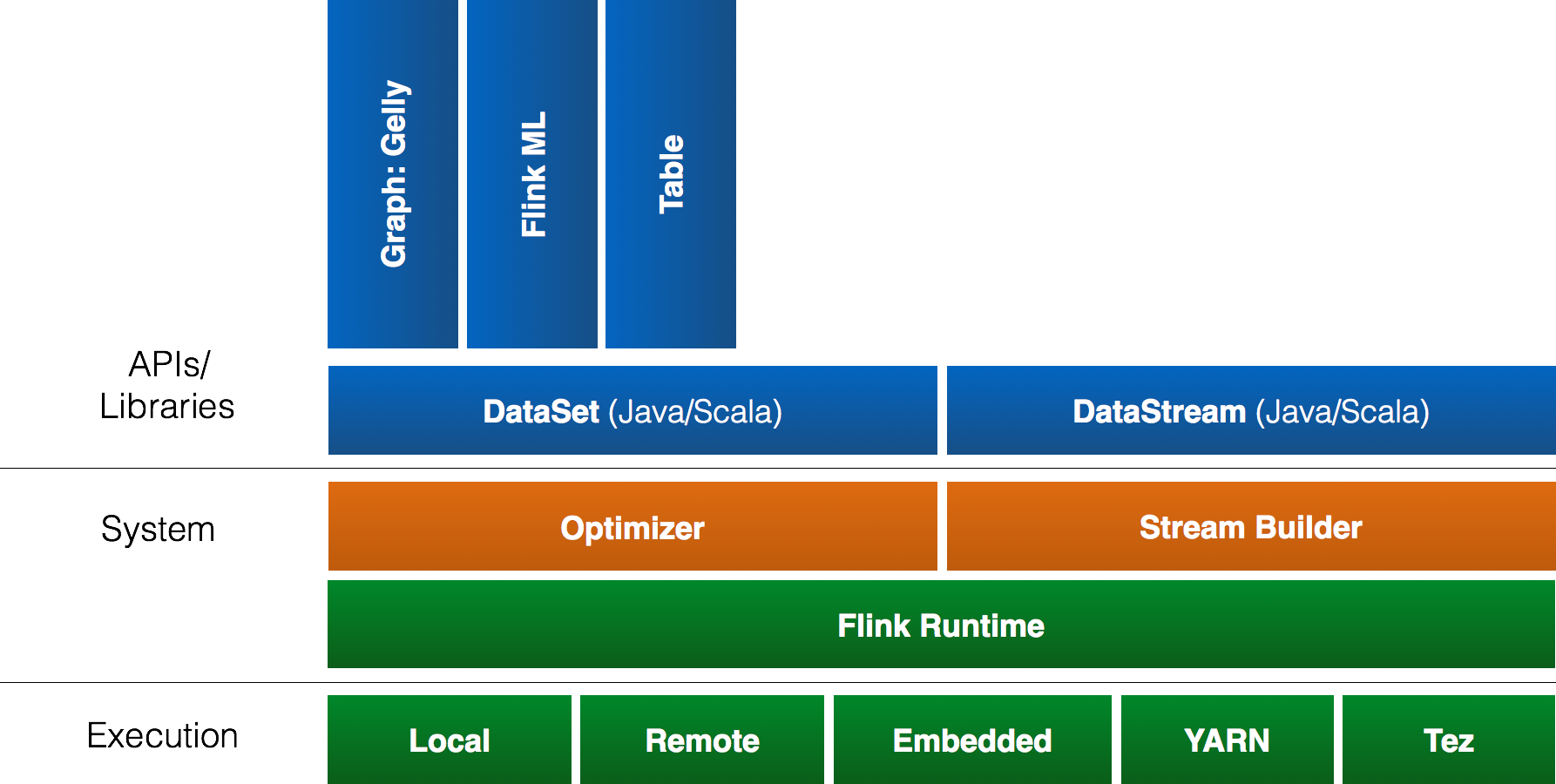
This is an overview of Flink’s stack. Click on any component to go to the respective documentation page.
原文:http://www.cnblogs.com/Chuck-wu/p/5031170.html