DATE 数据类型由年、月、日信息组成,表示一个日期值。 DATA 类型的默认格式为‘YYYY-MM-DD’。 YYYY 表示年, MM 表示月而 DD 表示日。时间值的范围从 0001-01-01 至 9999-12-31。
除了内置的SQL数据类型,在SQLScript里用户可以自定义一些表类型的数据类型
SQLScript类型系统是基于SQL-92类型系统的,它支持以下基础数据类型:
Numeric types: TINYINT SMALLINT INT BIGINT DECIMAL SMALLDECIMAL REAL DOUBLE
Character String Types : VARCHAR NVARCHAR ALPHANUM
Datetime Types: TIMESTAMP SECONDDATE DATE TIME
Binary Types :VARBINARY
Large Object Types :CLOB NCLOB BLOB
注:除了TEXT 、 SHORTTEXT类型外,与SQL语句的类型相同
SQLScript里可以定义Table数据类型。表类型一般用于存储过程的参数类型
CREATE TYPE用来创建自定义数据类型的
CREATE TYPE <type_name> AS TABLE (<column_list_definition>)
<type_name> ::= [<schema_name>.]<identifier>
<column_list_definition> ::= <column_elem>[{, <column_elem>}...]
<column_elem> ::= <column_name> <data_type>[<column_store_data_type>][<ddic_data_type>]
<data_type> ::= DATE | TIME | SECONDDATE | TIMESTAMP | TINYINT | SMALLINT |INTEGER | BIGINT | SMALLDECIMAL | DECIMAL| REAL |
DOUBLE | VARCHAR | NVARCHAR | ALPHANUM | SHORTTEXT |VARBINARY | BLOB | CLOB |
NCLOB | TEXT
<column_store_data_type> ::= CS_ALPHANUM | CS_INT | CS_FIXED |
CS_FLOAT |CS_DOUBLE | CS_DECIMAL_FLOAT | CS_FIXED(p-s, s)|
CS_SDFLOAT | CS_STRING | CS_UNITEDECFLOAT |CS_DATE | CS_TIME | CS_FIXEDSTRING |
CS_RAW| CS_DAYDATE | CS_SECONDTIME | CS_LONGDATE |CS_SECONDDATE
<ddic_data_type> ::= DDIC_ACCP | DDIC_ALNM | DDIC_CHAR |
DDIC_CDAY | DDIC_CLNT| DDIC_CUKY | DDIC_CURR | DDIC_D16D| DDIC_D34D |
DDIC_D16R | DDIC_D34R | DDIC_D16S | DDIC_D34S| DDIC_DATS | DDIC_DAY | DDIC_DEC|
DDIC_FLTP | DDIC_GUID | DDIC_INT1 | DDIC_INT2 | DDIC_INT4| DDIC_INT8 |
DDIC_LANG | DDIC_LCHR| DDIC_MIN | DDIC_MON | DDIC_LRAW | DDIC_NUMC | DDIC_PREC|
DDIC_QUAN | DDIC_RAW | DDIC_RSTR| DDIC_SEC | DDIC_SRST | DDIC_SSTR | DDIC_STRG
| DDIC_STXT| DDIC_TIMS | DDIC_UNIT | DDIC_UTCM| DDIC_UTCL | DDIC_UTCS |
DDIC_TEXT | DDIC_VARC | DDIC_WEEK
CREATETYPE tt_publishers ASTABLE (
publisher INTEGER,
name VARCHAR(50),
price DECIMAL,
cnt INTEGER);
DROP TYPE <type_name> [<drop_option>]
删除用户自定义类型
<type_name> ::= [<schema_name>.]<identifier>
<drop_option> ::= CASCADE | RESTRICT
如果未指定<drop_option>则将会执行一个非级联删除,仅删除指定的类型,相关联的类型不会被删除且不能被再使用,除非该自定义类型重新被创建
CREATETYPE my_type ASTABLE ( column_a DOUBLE );
DROPTYPE my_type;
CREATE
PROCEDURE [<schema_name>.]<proc_name> [(<parameter_clause>)]
[LANGUAGE <lang>] [SQL SECURITY <mode>]
[DEFAULT SCHEMA <default_schema_name>][READS SQL DATA [WITH RESULT VIEW
<view_name>]] AS
BEGIN [SEQUENTIAL EXECUTION]
<procedure_body>
END
The CREATE PROCEDURE statement creates a procedure using the specified programming language <lang>.
<parameter_clause> ::= <parameter> [{,<parameter>}...]
<parameter> ::= [<param_inout>] <param_name> <param_type>
<param_inout> ::= IN|OUT|INOUT
<param_type> ::= <sql_type> | <table_type> | <table_type_definition>
<sql_type> ::= DATE | TIME| TIMESTAMP | SECONDDATE | TINYINT |
SMALLINT |INTEGER | BIGINT | DECIMAL | SMALLDECIMAL | REAL | DOUBLE
| VARCHAR | NVARCHAR | ALPHANUM | VARBINARY | CLOB | NCLOB | BLOB
<table_type_defintion> ::= TABLE (<column_list_definition>)
<column_list_definition> ::= <column_elem>[{, <column_elem>}...]
<column_elem> ::= <column_name> <data_type>
输入或输出参数类型可以是标准的基础数据类型与表类型,但INOUT参数只能是标准数据类型
<param_inout>:默认为IN
<table_type_defintion>:参数类型如果是表类型,这个表类型可以是预先使用Create Type…As Table语句创建的类型对象,也可以在指定存储过程参数类型时才定义表类型
<lang> ::= SQLSCRIPT | R
默认为: SQLSCRIPT。指定存储过程实现的程序语言
<mode> ::= DEFINER | INVOKER
默认: DEFINER,指定存储过程的安全模式
DEFINER:Specifies that the execution of the procedure is performed with the privileges of the definer of the procedure. 只有存储过程的定义者才能执行?
INVOKER:Specifies that the execution of the procedure is performed with the privileges of the invoker of the procedure.
存储过程为只读的,不能包含DDL与DML(INSERT、UPDATE、DELETE)语句(即只能使用查询SQL与DCL语句),如果调用其他存储过程,则被调用过程也是只读的。设置参数会有特定的优化
Specifies the result view to be used as the output of a read-only procedure.将只读取存储过程的输出看做结果视图
When a result view is defined for a procedure, it can be called by an SQL statement in the same way as a tableor view. See Example 2 - Using a result view below.定义了结果视图的存储过程,可以被其他查询SQL用来查询,此时存储过程就像一个表或视图
This statement will force sequential execution of the procedure logic. No parallelism takes place.不允许存储过程并行执行
<procedure_body>
::= [<proc_decl_list>] 定义块
[<proc_handler_list>] 异常处理块
<proc_stmt_list> 存储体语句块
Defines the main body of the procedure according to the programming language selected.过程的主体由设定的程序语言来定义
<proc_decl_list> ::= <proc_decl> [{<proc_decl>}…]
<proc_decl> ::= DECLARE {<proc_variable>|<proc_table_variable>|<proc_cursor>|<proc_condition>} ;
<proc_variable>::= <variable_name_list> [CONSTANT] {<sql_type>|<array_datatype>}[NOT NULL][<proc_default>]
<variable_name_list> ::= <variable_name>[{, <variable_name}...]
<array_datatype> ::= <sql_type> ARRAY [ = <array_constructor> ]
<array_constructor> ::= ARRAY (<expression> [ { , <expression> }...] )
<proc_default> ::= (DEFAULT | ‘=‘ ) <value>|<expression>
<proc_table_variable> ::= <variable_name_list> {<table_type_definition>|<table_type>}
<variable_name_list> ::= <variable_name>[{, <variable_name}...]
<table_type_definition> ::= TABLE(<column_list_elements>)
<column_list_elements> ::= (<column_definition>[{,<column_definition>}...])
<proc_cursor> ::= CURSOR <cursor_name> [ ( proc_cursor_param_list ) ] FOR <subquery> ;
<proc_cursor_param_list> ::= <proc_cursor_param> [{,<proc_cursor_param>}...]
<proc_cursor_param> ::= <param_name> <datatype>
<proc_condition> ::= <variable_name> CONDITION | <variable_name> CONDITION FOR <sql_error_code>
CREATEprocedure proc() LANGUAGE SQLSCRIPT AS
BEGIN
declare a intdefault 2;--基本类型变量使用前一定要定义
-- 如果某个变量是表类型的变量,可以不用声明,直接就可以使用,这与基本类型变量是不一样的
-- ——基本类型变量使用前需要定义
--declare tab_var1 table(a int,b int); 表类型变量可不定义就使用
a := 1;
-- a = 1; 基本类型变量赋值时,等号前一定要加冒号,这与表类型变量恰好相反
tab_var1 = select 1 as a,2 as b from dummy;
--tab_var1 := select 1 as a,2 as b from dummy; 这是错误,表类型变量赋值时,只能使用等号,不能在等号前加冒号,这与基本类型变量赋值相反
END;
<proc_handler_list> ::= <proc_handler> [{, <proc_handler>}...]
<proc_handler>::= DECLARE EXIT HANDLER FOR <proc_condition_value_list> <proc_stmt> ;
<proc_condition_value_list> ::= <proc_condition_value>{,<proc_condition_value>}...]
<proc_condition_value> ::= SQLEXCEPTION | SQLWARNING | <sql_error_code> | <condition_name>
<proc_stmt_list> ::= {<proc_stmt>}...
<proc_stmt>
::= <proc_block>| <proc_assign>| <proc_single_assign>|
<proc_multi_assign>| <proc_if>| <proc_loop>|
<proc_while>| <proc_for>|
<proc_foreach>| <proc_exit>| <proc_continue>|
<proc_signal>| <proc_resignal>| <proc_sql>|
<proc_open>| <proc_fetch>| <proc_close>| <proc_call>|
<proc_exec>| <proc_return>
<proc_block> ::= BEGIN <proc_block_option>[<proc_decl_list>][<proc_handler_list>] <proc_stmt_list> END ;
<proc_block_option> ::= [SEQUENTIAL EXECUTION]
[AUTONOMOUS TRANSACTION]| [AUTONOMOUS TRANSACTION] [SEQUENTIAL
EXECUTION]
内嵌块, BEGIN 、 END是可以内嵌的
<proc_assign> ::= <variable_name> = { <expression> | <array_function> } ;| <variable_name> ‘[‘ <expression> ‘]‘ = <expression> ;
<array_function> = ARRAY_AGG (
<table_variable>.<column_name> [ ORDER BY <sort_spec_list> ]
) | CARDINALITY ( <array_variable_name>) | TRIM_ARRAY
( <array_variable_name> , <array_variable_name>) | ARRAY (
<array_variable_name_list> )
<array_variable_name_list> ::=< array_variable_name > [{, < array_variable_name >}...] 这个是自己 加的,是否正确?
Assign values to variables. An <expression> can be either a simple expression, such as a character, a date, or a number, or it can be a scalar function or a scalar user-defined function.将值赋给变量。<expression>可以是一个简单的表达式(如字符、日期、数字表达式),或者是标准函数,或用户自定义函数
有关 ARRAY 、ARRAY_AGG、CARDINALITY、TRIM_ARRAY函数请参考后面数组函数
<proc_single_assign>
::= <variable_name> = <subquery> | <variable_name> =
<proc_ce_call> | <variable_name> = <proc_apply_filter>|
<variable_name> =
<unnest_function>
<proc_ce_call> ::= TRACE ( <variable_name> ) ;|
CE_LEFT_OUTER_JOIN ( <table_variable> , <table_variable> ,‘[‘
<expr_alias_comma_list> ‘]‘ <expr_alias_vector>] ) ;
| CE_RIGHT_OUTER_JOIN ( <table_variable> , <table_variable>
,‘[‘ <expr_alias_comma_list> ‘]‘ [ <expr_alias_vector>] ) ; |
CE_FULL_OUTER_JOIN ( <table_variable> , <table_variable> ,‘[‘
<expr_alias_comma_list> ‘]‘ [ <expr_alias_vector>] ); | CE_JOIN (
<table_variable> , <table_variable> ,
‘[‘<expr_alias_comma_list> ‘]‘ [<expr_alias_vector>] ) ;|
CE_UNION_ALL ( <table_variable> , <table_variable> ) ;| CE_COLUMN_TABLE
( <table_name> [ <expr_alias_vector>] ) ; | CE_JOIN_VIEW (
<table_name> [ <expr_alias_vector>] ) ;| CE_CALC_VIEW (
<table_name> [ <expr_alias_vector>] ) ; | CE_OLAP_VIEW (
<table_name> [ <expr_alias_vector>] ) ; | CE_PROJECTION (
<table_variable> , ‘[‘<expr_alias_comma_list> ‘]‘
<opt_str_const> ) ; | CE_PROJECTION ( <table_variable>
<opt_str_const> ) ; | CE_AGGREGATION ( <table_variable> ,
‘[‘<agg_alias_comma_list> ‘]‘ [ <expr_alias_vector>] ); |
CE_CONVERSION ( <table_variable> , ‘[‘<proc_key_value_pair_comma_list>
‘]‘ [ <expr_alias_vector>] ) ;| CE_VERTICAL_UNION (
<table_variable> , ‘[‘<expr_alias_comma_list> ‘]‘
<vertical_union_param_pair_list> ) ;| CE_COMM2R ( <table_variable>
, <int_const> , <str_const> ,<int_const> , <int_const>
, <str_const> ) ;
<table_name> ::= [<schema_name>.]<identifier>
<proc_apply_filter> ::= APPLY_FILTER ( {<table_name> | <table_variable>},<variable_name> ) ;
<unnest_function> ::= UNNEST ( <variable_name_list> ) [ WITH ORDINALITY ][<as_col_names>] ;
<variable_name_list> ::= <variable_name> [{, <variable_name>}...]
<as_col_names> ::= AS [table_name] ( <column_name_list> )
<column_name_list> ::= <column_name>[{, <column_name>}...]
WITH ORDINALTIY:Appends an ordinal column to the return values.
<proc_multi_assign> ::= (<var_name_list>) = <function_expression>
Assign values to a list of variables with only one function evaluation. For example, <function_expression>must be a scalar user defined function and the number of elements in <var_name_list> must be equal to the number of output parameters of the scalar UDF(用户定义函数).
<function_expression>:用户自定义函数
函数的输入参数个数需与<var_name_list>中的参数个数相同
<proc_if> ::= IF <condition> THEN [SEQUENTIAL EXECUTION][<proc_decl_list>] [<proc_handler_list>] <proc_stmt_list> [<proc_elsif_list>] [<proc_else>] END IF ;
<proc_elsif_list> ::= ELSEIF <condition> THEN [SEQUENTIAL EXECUTION][<proc_decl_list>] [<proc_handler_list>] <proc_stmt_list>
<proc_else> ::= ELSE [SEQUENTIAL EXECUTION][<proc_decl_list>][<proc_handler_list>] <proc_stmt_list>
You use IF - THEN - ELSE IF to control execution flow with conditionals.
<proc_loop> ::= LOOP [SEQUENTIAL EXECUTION][<proc_decl_list>] [<proc_handler_list>] <proc_stmt_list> END LOOP ;
You use loop to repeatedly execute a set of statements.
<proc_while> ::= WHILE <condition> DO [SEQUENTIAL EXECUTION][<proc_decl_list>] [<proc_handler_list>] <proc_stmt_list> END WHILE ;
You use while to repeatedly call a set of trigger statements while a condition is true.
<proc_for> ::= FOR <column_name> IN [ REVERSE ] <expression> [...] <expression> DO [SEQUENTIAL EXECUTION]
[<proc_decl_list>]
[<proc_handler_list>]
<proc_stmt_list>
END FOR ;
You use FOR - IN loops to iterate over a set of data.
<proc_foreach> ::= FOR <column_name> AS <column_name> [<open_param_list>] DO [SEQUENTIAL EXECUTION]
[<proc_decl_list>]
[<proc_handler_list>]
<proc_stmt_list>
END FOR ;
<open_param_list> ::= ( <expression> [ { , <expression> }...] )
You use FOR - EACH loops to iterate over all elements in a set of data.
<proc_exit> ::= BREAK ;
Terminates a loop.结束循环
<proc_continue> ::= CONTINUE ;
Skips a current loop iteration and continues with the next value.结束当前循环继续下一次循环
<proc_signal> ::= SIGNAL <signal_value> [<set_signal_info>] ;
You use the SIGNAL statement to explicitly raise an exception from within your trigger procedures.
<proc_resignal> ::= RESIGNAL [<signal_value>] [<set_signal_info>] ;
You use the RESIGNAL statement to raise an exception on the action statement in an exception handler. If an error code is not specified, RESIGNAL will throw the caught exception.重新抛出异常?
<signal_value> ::= <signal_name> | <sql_error_code>
<signal_name> ::= <identifier>
<sql_error_code> ::= <unsigned_integer>
You can SIGNAL or RESIGNAL a signal name or an SQL error code.
<set_signal_info> ::= SET MESSAGE_TEXT = ‘<message_string>‘
<message_string> ::= <any_character>
You use SET MESSAGE_TEXT to deliver an error message to users when specified error is thrown during procedure execution.
<proc_sql> ::= <subquery> | <select_into_stmt> | <insert_stmt> | <delete_stmt> | <update_stmt> | <replace_stmt> | <call_stmt> | <create_table> | <drop_table>
<insert_stmt>, <delete_stmt>,<update_stmt>,<replace_stmt> and <upsert_stmt>请参考HANA SQL中INSERT , DELETE, UPDATE, REPLACE and UPSERT SQL语句
<select_into_stmt> ::= SELECT <select_list> INTO
<var_name_list> <from_clause > [<where_clause>] [<group_by_clause>]
[<having_clause>] [{<set_operator>
<subquery>, ... }] [<order_by_clause>] [<limit>] ;
<var_name_list> ::= <var_name>[{, <var_name>}...] <var_name>为基础类型变量
<proc_open> ::= OPEN <cursor_name> [ <open_param_list>] ;
<proc_fetch> ::= FETCH <cursor_name> INTO <column_name_list> ;
<proc_close> ::= CLOSE <cursor_name> ;
Cursor operations
<proc_call> ::= CALL <proc_name> (<param_list>) ;
Calling a procedure
<proc_exec> ::= {EXEC | EXECUTE IMMEDIATE} <proc_expr> ;
You use EXEC to make dynamic SQL calls.
<proc_return> ::= RETURN [<proc_expr>] ;
Return a value from a procedure.
Example 1 - Creating an SQL Procedure
You create an SQLScript procedure with the following definition.
CREATECOLUMNTABLE"SYSTEM"."T" ("ID"INTEGER CS_INT,
"NAME"VARCHAR(30),
"PAYMENT"INTEGER CS_INT) UNLOADPRIORITY 5 AUTO MERGE;
insertinto"SYSTEM"."T"values(1,‘a‘,10);
insertinto"SYSTEM"."T"values(2,‘b‘,20);
insertinto"SYSTEM"."T"values(3,‘c‘,30);
CREATEPROCEDURE orchestrationProc LANGUAGE SQLSCRIPT AS
BEGIN
DECLARE v_id INT;
DECLARE v_name VARCHAR(30);
DECLARE v_pmnt INT;
DECLARE v_msg VARCHAR(200);
DECLARECURSOR c_cursor1 (p_payment INT) FORSELECT id, name, PAYMENT FROM t
WHERE payment >= p_payment ORDERBY id ASC;
OPEN c_cursor1(20);
FETCH c_cursor1 INTO v_id, v_name, v_pmnt;
v_msg := v_name || ‘ (id ‘ || v_id || ‘) earns ‘ || v_pmnt || ‘ $.‘;
select v_msg from dummy;
CLOSE c_cursor1;
end;
Example 2 - Using a result view
创建带返回视图结果的存储过程:
CREATEPROCEDURE ProcWithResultView(IN id INT, OUT o1 t)
LANGUAGE SQLSCRIPT
READS SQL DATA WITH RESULT VIEW ProcView AS
BEGIN
o1 = SELECT * FROM t WHERE id = :id;
END;
调用存储视图:
select * from ProcView with parameters (‘placeholder‘ = (‘$$id$$‘ ,‘2‘ ));
Note
Procedures and result views produced by procedures are not connected from the security perspective and therefore do not inherit privileges from each other. The security aspects of each object must be handled separately. For example, you must grant the SELECT privilege on a result view and EXECUTE privilege on a connected procedure.
DROPPROCEDURE [<schema_name>.]<proc_name> [<drop_option>]
<drop_option> ::= CASCADE | RESTRICT
如果未指定删除选项,则默认为非级联删除,这将只会删除存储过程本身,这会导致相关联的其他对象无效,但不会被删除。如果存储过程重建则相关联失效的对应将重新生效
CASCADE:存储过程与相关联对象一起被删除
RESTRICT:如果有相关联的对象没有被删除,则删除时被报错,不让被删除。只有当没有关联的对象时,才可以删除
使用非级联删除:DROPPROCEDURE my_proc;
ALTERPROCEDURE [<schema_name>.]<proc_name> RECOMPILE [WITHPLAN]
WITH PLAN:
Specifies that internal debug information should be created during execution of the procedure.
Description
The ALTER PROCEDURE RECOMPILE statement manually triggers a recompilation of a procedure by generating an updated execution plan. For production code a procedure should be compiled without the WITH PLAN option to avoid overhead during compilation and execution of the procedure.
Example
You trigger the recompilation of the my_proc procedure to produce debugging information.
ALTERPROCEDURE my_proc RECOMPILEWITHPLAN;
CALL <proc_name> (<param_list>) [WITH OVERVIEW] [INDEBUGMODE]
<param_list> ::= <proc_param>[{, <proc_param>}...]
<proc_param> ::= <identifier> | <string_literal> |
<unsigned_integer> |<signed_integer>|
<signed_numeric_literal> | <unsigned_numeric_literal>
|<expression>
Parameters passed to a procedure are scalar constants and can be passed either as IN, OUT or INOUT parameters. Scalar parameters are assumed to be NOT NULL. Arguments for IN parameters of table type can either be physical tables or views. The actual value passed for tabular OUT parameters must be`?`.
IN DEBUG MODE
When specified additional debug information will be created during the execution of the procedure. This information can be used to debug the instantiation of the internal execution plan of the procedure.
WITH OVERVIEW
Defines that the result of a procedure call will be stored directly into a physical table.
Calling a procedure WITH OVERVIEW will return one result set that holds the information of which table contains the result of a particular table‘s output variable. Scalar outputs will be represented as temporary tables with only one cell. When you pass existing tables to the output parameters WITH OVERVIEW will insert the result set tuples of the procedure into the provided tables. When you pass ‘?‘ to the output parameters, temporary tables holding the result sets will be generated. These tables will be dropped automatically once the database session is closed.
CALL conceptually returns list of result sets with one entry for every tabular result. An iterator can be used to iterate over these results sets. For each result set you can iterate over the result table in the same way as for query results. SQL statements that are not assigned to any table variable in the procedure body will be added as result sets at the end of the list of result sets. The type of the result structures will be determined during compilation time but will not be visible in the signature of the procedure.
CALL when executed by the client the syntax behaves in a way consistent with the SQL standard semantics, for example, Java clients can call a procedure using a JDBC CallableStatement. Scalar output variables will be a scalar value that can be retrieved from the callable statement directly.
Note:
Unquoted identifiers are implicitly treated as upper case. Quoting identifiers will respect capitalization and allow for using white spaces which are normally not allowed in SQL identifiers.
Examples:
For the examples, consider the following procedure signature:
CREATEPROCEDURE proc(INvalueinteger,IN currency nvarchar(10),OUT outTable typeTable,OUT valid integer) AS
BEGIN
…
END;
Calling the proc procedure:
CALL proc (1000, ‘EUR‘, ?, ?);
Calling the proc procedure in debug mode:
CALL proc (1000, ‘EUR‘, ?, ?) INDEBUGMODE;
Calling the proc procedure using the WITH OVERVIEW option:
CALL proc(1000, ‘EUR‘, ?, ?) WITH OVERVIEW;
It is also possible to use scalar user defined function as parameters for procedure call:
CALL proc( udf(),’EUR’,?,?);
CALL proc( udf() * udf() - 55,’EUR’, ?, ?);
In this example, udf() is a scalar user-defined function. For more information about scalar user-defined functions, see CREATE FUNCTION
WITH OVERVIEW实例:
CREATETABLE COL_COSTS
( CHANNEL_ID INTEGER
, PROD_ID INTEGER
, UNIT_COST DOUBLE
, UNIT_PRICE DOUBLE
);
CREATEPROCEDURE PR_SAMPLE_OVERVIEW ( OUT P_COL_COSTS COL_COSTS )--输出参数为物理表
LANGUAGE SQLSCRIPT AS
BEGIN
P_COL_COSTS =
SELECT 123 as CHANNEL_ID,
555 as PROD_ID,
7.5 as UNIT_COST,
9.99 as UNIT_PRICE
FROM DUMMY;
END;
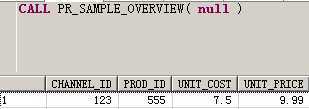
CALL PR_SAMPLE_OVERVIEW( null );-- 如果不存储结果时,需传入NULL或者?
SELECT * FROM col_costs; -- COL_COSTS表中没有数据
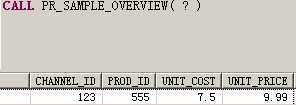
CALL PR_SAMPLE_OVERVIEW( ? );-- 如果不存储结果时,需传入NULL或者?
SELECT * FROM col_costs; --COL_COSTS表中没有数据
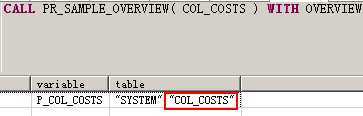
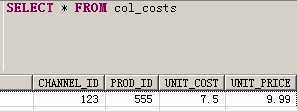
CALL PR_SAMPLE_OVERVIEW( COL_COSTS ) WITH OVERVIEW; --将结插入到COL_COSTS物理表中了
SELECT * FROM col_costs; --COL_COSTS表中有数据
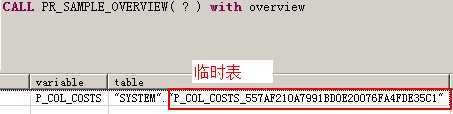
CALL PR_SAMPLE_OVERVIEW( ? ) with overview;-- 如果加上了 with overview选项,但没有传入物理表,则会将结果存储到临时表中
在存储过程内部调用
CALL <proc_name > (<param_list>)
<param_list> ::= <param>[{, <param>}...]
<param>::= <in_table_param> | <in_scalar_param> |<out_scalar_param> |<out_table_param>
<in_table_param> ::= <read_variable_identifier>|<sql_identifier>
<in_scalar_param>::=<read_variable_identifier>|<scalar_value>|<expression>
<in_param> ::=:<identifier> 请注意在输入参数明有个冒号
<out_param> ::= <identifier>
Description:
For an internal procedure, where one procedure calls another procedure, all existing variables of the caller or literals are passed to the IN parameters of the callee and new variables of the caller are bound to the OUT parameters of the callee. That is to say, the result is implicitly bound to the variable that is given in the function call.
Example:
CALL addDiscount (:lt_expensive_books, lt_on_sale);
When procedure addDiscount is called, the variable <:lt_expensive_books> is assigned to the function and the variable <lt_on_sales> is bound by this function call.
CREATEPROCEDURE addDiscount(in old_pric int , out dic_pric int) as
begin
dic_pric := old_pric * 2;
--dic_pric := :old_pric * 2; 这样好像也可以
end;
createprocedure callerProc() as
begin
declare pric int;
pric := 10;
call addDiscount(pric,pric);
--call addDiscount(:pric,:pric); 这样好像也可以
select pric from dummy;
end;
call callerProc();--20
参数传递时,可以不按声明的顺序
You can call a procedure passing named parameters by using the token =>.
For example:
CALL myproc (i => 2)
When you use named parameters you can ignore the order of the parameters in the procedure signature. Run the following commands and you can try some examples below.
createtype mytab_t astable (i int);
createtable mytab (i int);
insertinto mytab values (0);
insertinto mytab values (1);
insertinto mytab values (2);
insertinto mytab values (3);
insertinto mytab values (4);
insertinto mytab values (5);
createprocedure myproc (in intab mytab_t,in i int, out outtab mytab_t) as
begin
outtab = select i from :intab where i > :i;
end;
Now you can use the following CALL possibilities:
createtype mytab_t astable (i int);
createtable mytab (i int);
insertinto mytab values (0);
insertinto mytab values (1);
insertinto mytab values (2);
insertinto mytab values (3);
insertinto mytab values (4);
insertinto mytab values (5);
createprocedure myproc (in intab mytab_t,in i int, out outtab mytab_t) as
--create procedure myproc (in intab mytab,in i int, out outtab mytab) as 类型可以直接是物理表类型
begin
outtab = select i from :intab where i > :i;
end;
call myproc(intab=>mytab, i=>2, outtab =>?);-- mytab 实参为物理表。问号表示不传此参数,但即使不传实参,型参在过程里一样使用,只是结果不能传出来而已
--call myproc(intab=>mytab, i=>2, outtab =>null); 也可以使用NULL,但运行会警告,并且不推荐使用,以后新版本会使用问号逐渐代替NULL
or
call myproc( i=>2, intab=>mytab, outtab =>?)
Both call formats will produce the same result.
Parameter Modes
The following table lists the parameters you can use when defining your procedures.
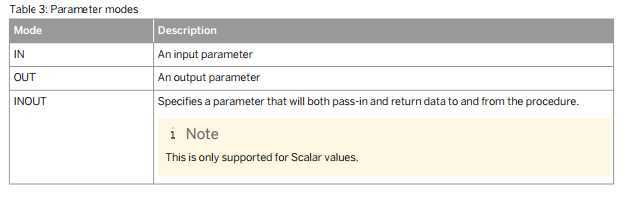
INOUT类型的参数仅支持基本类型的参数,不支持表类型?
Supported Parameter Types
Both scalar and table parameter types are supported. For more information on datatypes, see Datatype Extension
Scalar Parameters基本类型
Consider the following procedure:
CREATEPROCEDURE test_scalar (IN i INT, IN a VARCHAR)
AS
BEGIN
SELECT i AS"I", a AS"A"FROM DUMMY;
END;
You can pass parameters using scalar value binding:
CALL test_scalar (1, ‘ABC‘);
You can also use expression binding.
CALL test_scalar (1+1, upper(‘abc‘))
Table parameters表类型
Consider the following procedure:
CREATETYPE tab_type ASTABLE (I INT, A VARCHAR);
CREATETABLE tab1 (I INT, A VARCHAR);
CREATEPROCEDURE test_table (IN tab tab_type)
--CREATE PROCEDURE test_table (IN tab tab1) 参数类型也可以直接是物理表
AS
BEGIN
SELECT * FROM :tab;
END;
You can pass tables and views to the parameter of this function.
CALL test_table (tab1);
You should always use sql special identifiers when binding a value to a table variable.在将表做为参数传递时,一般你应该使用表名,所以使用又引号引导起来再传递
CALL test_table ("TAB1");-- 也可以直接写上表名或视图名,但要注意的是:使用引号引起来后,要全部大写
--CALL test_table ("tab1") 由于是小写,所以找不到所对应的表或视图
In the procedure signature you can define default values for input parameters by using the DEFAULT keyword.
Consider the following procedure:
CREATEPROCEDURE MYPROC(IN P1 INT, IN P2 INTDEFAULT 1, OUT out1 DUMMY) AS
BEGIN
out1 = SELECT :P1 + :P2 AS DUMMY FROM DUMMY;
END;
You can see that the second parameter has a default value of 1.
To use the default values in the procedure signature, you need to pass in procedure parameters using Named Parameters.
You can call this procedure in the following ways:
With all input values specified:
CALL MYPROC(3, 4,?);
Using the default value via named parameters:
CALL MYPROC(P1 => 3, out1 => ?)
存储过程元数据
当一个存储过程在创建时,关系这个存储过程的创建信息(元数据)会被存储到一系列相关视图中
When a procedure is created, information about the procedure can be found in the database catalog. You can use this information for debugging purposes.
The procedures observable in the system views vary according to the privileges that a user has been granted.
The following visibility rules apply:
● • CATALOG READ or DATA ADMIN – All procedures in the system can be viewed.
● • SCHEMA OWNER, or EXECUTE – Only specific procedures where the user is the owner, or they have execute privileges, will be shown.
Procedures can be exported and imported like tables, see the SQL Reference documentation for details. For more information see Data Import Export Statements.
The system views for procedures are summarized below:
下面是一些存储过程元数据信息所在的视图,具体视图的结构可打开HANA查看
SYS.PROCEDURES:可用存储过程视图,
SYS. PROCEDURE_PARAMETERS:存储过程的参数
SYS.OBJECT_DEPENDENCIES:Dependencies between objects, for example, views which refer to a specific table。所依赖的对象
In this section we explore the ways in which you can query the OBJECT_DEPENDENCIES system view.
You create the following database objects and procedures.
dropschema deps CASCADE;
dropTYPE mytab_t;
dropTABLE mytab1;
dropTABLE mytab2 ;
CREATESCHEMA deps;
CREATETYPE mytab_t ASTABLE (id int, key_val int, val int);
CREATETABLE mytab1 (id INTPRIMARYKEY, key_val int, val INT);
CREATETABLE mytab2 (id INTPRIMARYkey, key_val int, val INT);
CREATEPROCEDURE deps.get_tables(OUT outtab1 mytab_t, OUT outtab2 mytab_t)
LANGUAGE SQLSCRIPT READS SQL DATA AS
BEGIN
outtab1 = SELECT * FROM mytab1;
outtab2 = SELECT * FROM mytab2;
END;
CREATEPROCEDURE deps.my_proc (IN val INT, OUT outtab mytab_t) LANGUAGE
SQLSCRIPT READS SQL DATA AS
BEGIN
CALL deps.get_tables(tab1, tab2);
IF :val > 1 THEN
outtab = SELECT * FROM :tab1;
ELSE
outtab = SELECT * FROM :tab2;
ENDIF;
END;
Object dependency examination对象依赖测试:
Firstly you will find all the (direct and indirect) base objects of the procedure DEPS.MY_PROC. You execute the following statement.
SELECT * FROM OBJECT_DEPENDENCIES WHERE dependent_object_name = ‘MY_PROC‘and dependent_schema_name = ‘DEPS‘;;
The result obtained is as follows:

Let’s examine(看看) the DEPENDENCY_TYPE column in more detail. As you obtained the results in the table above via a select on all the base objects of the procedure, the objects show include both persistent and transient objects. You can distinguish(区分) between these object dependency types using the DEPENDENCY_TYPE column, as shown below:
1. EXTERNAL_DIRECT: base object is directly used in the dependent procedure.直接依赖
2. EXTERNAL_INDIRECT: base object is not directly used in the dependent procedure.间接依赖
查看MY_PROC在哪被使用了:
SELECT * FROM OBJECT_DEPENDENCIES WHERE base_object_name = ‘MY_PROC‘and base_schema_name = ‘DEPS‘
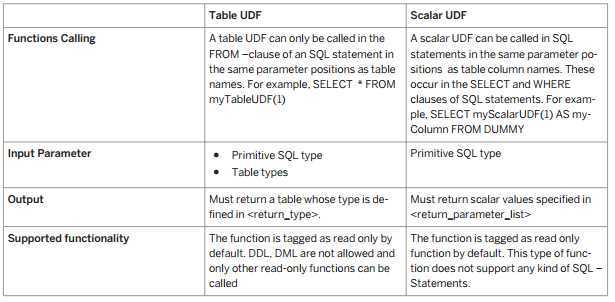
There are two different kinds of user defined function (UDF): Table User Defined Function and Scalar User Defined Function in the following table are referred to as Table UDF and Scalar UDF. They differ by input/output parameter, supported functions in the body, and the way they are consumed in SQL statements.
两种不同类型的用户自定义函数:表类型用户定义函数(返回结果为表类型)、基本类型用户定义函数(返回结果为基本类型)
表类型函数只能在Select…From…后面使用,而基本类型函数则在Select…或Where…后面使用
表类型函数的输入参数可以是基本类型,也可以是表类型,但基本类型函数的输入参数只能是基本类型
表类型函数的输出只能表类型,而基本类型函数的输出只能是标量类型
表类型函数体是只读的,不支持DDL与DML语句,而基本类型函数也是只读的,并且此种类型的函数不支持任何SQL语句
This SQL statement creates read-only user defined functions that are free of side-effects. This means that neither DDL nor DML statements (INSERT, UPDATE, and DELETE) are allowed in the function body. All functions or procedures selected or called from the body of the function must be read-only.
Syntax
CREATEFUNCTION [<schema_name>.]<func_name> [(<parameter_clause>)] RETURNS <return_type>
[LANGUAGE <lang>] [SQL SECURITY <mode>][DEFAULTSCHEMA <default_schema_name>]
AS
BEGIN
<function_body>
END
<parameter_clause> ::= <parameter> [{,<parameter>}...]
<parameter> ::= [IN] <param_name> <param_type>
<param_type> ::= <sql_type> | <table_type> | <table_type_definition>
Scalar UDF only supports primitive SQL types as input, whereas Table UDF also supports table types as input.标量用户函数的输入参数仅支持SQL基本类型,表类型函数除SQL基本类型外,还支持表类型
Currently the following primitive SQL types are allowed in scalar UDF:
<sql_type> ::= DATE | TIME | TIMESTAMP | SECONDDATE | TINYINT | SMALLINT | INTEGER | BIGINT | DECIMAL | SMALLDECIMAL | REAL | DOUBLE | VARCHAR | NVARCHAR
Table UDF allows a wider range(扩展范围的基本类型) of primitive SQL types:
<sql_type> ::= DATE | TIME | TIMESTAMP | SECONDDATE | TINYINT | SMALLINT |INTEGER | BIGINT | DECIMAL | SMALLDECIMAL | REAL | DOUBLE | VARCHAR | NVARCHAR |ALPHANUM | VARBINARY | CLOB | NCLOB | BLOB
To look at a table type previously defined with the CREATE TYPE command, see CREATE TYPE.
<table_type_defintion> ::= TABLE (<column_list_definition>)
<column_list_definition > ::= <column_elem>[{, <column_elem>}...]
<column_elem> ::= <column_name> <data_type>
<table_type_defintion> :A table type implicitly defined within the signature.在定义函数时,直接在函数参数签名中定义表类型,而不用Create Type…Table 预先定义
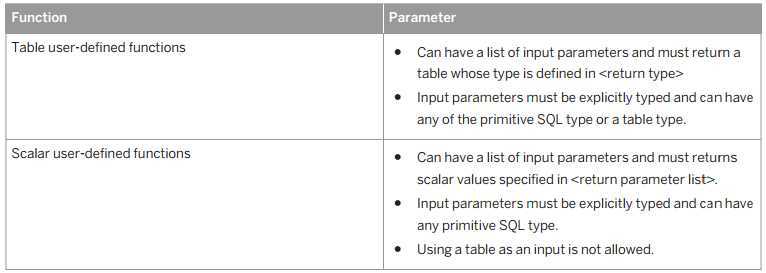
<return_type> ::= <return_parameter_list> | <return_table_type>
Table UDF must return a table whose type is defined by <return_table_type>. And scalar UDF must return scalar values specified in <return_parameter_list>.表用户函数必须返回通过<return_table_type>定义的表类型,标量用户函数必须返回由<return_parameter_list>中指定的标量值
<return_parameter_list> ::= <return_parameter>[{, <return_parameter>}...]
<return_parameter> ::= <parameter_name> <sql_type>
<return_table_type> ::= TABLE ( <column_list_definition> )
标量函数可以返回多个值?
LANGUAGE <lang>
<lang> ::= SQLSCRIPT
Default: SQLSCRIPT
Defines the programming language used in the function.
Note:Only SQLScript UDF can be defined.
SQL SECURITY <mode>
<mode> ::= DEFINER | INVOKER
Default: DEFINER (Table UDF) / INVOKER (Scalar UDF)
Specifies the security mode of the function.
DEFINER:Specifies that the execution of the function is performed with the privileges of the definer of the function.
INVOKER:Specifies that the execution of the function is performed with the privileges of the invoker of the function.
DEFAULT SCHEMA <default_schema_name>
<default_schema_name> ::= <identifier>
Specifies the schema for unqualified objects in the function body. If nothing is specified, then the current_schema of the session is used.
<function_body> ::= <scalar_function_body>|<table_function_body>
<scalar_function_body> ::= [DECLARE <func_var>] <proc_assign>
<table_function_body> ::= [<func_block_decl_list>]
[<func_handler_list>]
<func_stmt_list>
<func_return_statement>
Defines the main body of the table UDF and scalar UDF. As the function is flagged as read-only, neither DDL nor DML statements (INSERT, UPDATE, and DELETE) are allowed in the function body. A scalar UDF does not support table-typed variables as its input and table operations in the function body.由于函数被标识为只读的,所以DDL和DML语句都是不允许的。标量用户函数不支持表类型变量做为输入参数,并且在函数中也不支持表操作。
For the definition of <proc_assign>, see CREATE PROCEDURE.
<func_block_decl_list> ::= DECLARE { <func_var>|<func_cursor>|<func_condition> }
<func_var> ::= <variable_name_list> [CONSTANT] { <sql_type>|<array_datatype> } [NOT NULL][<func_default>];
<array_datatype> ::= <sql_type> ARRAY [ = <array_constructor> ]
<array_constructor> ::= ARRAY ( <expression> [{,<expression>}...] )
<func_default> ::= { DEFAULT | = } <func_expr>
<func_expr> ::= !!An element of the type specified by <sql_type>
Defines one or more local variables with associated scalar type or array type.
An array type has <type> as its element type. An Array has a range from 1 to 2,147,483,647, which is the limitation of underlying structure.
You can assign default values by specifying <expression>s. See Expressions in the SAP HANA SQL and System Views Reference .
<func_handler_list> ::= <proc_handler_list>
See CREATE PROCEDURE .
<func_stmt_list> ::= <func_stmt>| <func_stmt_list> <func_stmt>
<func_stmt> ::= <proc_block>| <proc_assign>|
<proc_single_assign>| <proc_if>| <proc_while>|
<proc_for>| <proc_foreach>| <proc_exit>|
<proc_signal>| <proc_resignal>| <proc_open>|
<proc_fetch>| <proc_close>
For further information of the definitions in <func_stmt>, see CREATE PROCEDURE .
<func_return_statement> ::= RETURN <function_return_expr>
<func_return_expr> ::= <table_variable> | <subquery>
A table function must contain a return statement.表类型函数必须要有一个return语句
You create a table UDF with the following definition.
dropFUNCTION scale;
CREATEFUNCTION scale(val INT) RETURNSTABLE (a INT, b INT) LANGUAGE SQLSCRIPT AS
BEGIN
RETURNSELECT 20 as a, :val * 2 AS b FROM dummy;
END;
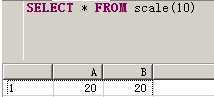
You use the scale function like a table. See the following example:
SELECT * FROM scale(10);
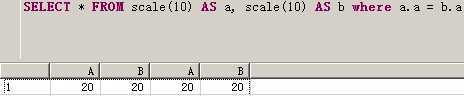
SELECT * FROM scale(10) AS a, scale(10) AS b where a.a = b.a
You also create a scalar UDF with the following definition.
CREATEFUNCTION func_add_mul(x Double, y Double) RETURNS result_add Double, result_mul Double--标量函数可以返回多个值
LANGUAGE SQLSCRIPT READS SQL DATA AS
BEGIN
--标量函数体里不能有SQL语句,且返回的值直接使用 := 返回,而不是Result
result_add := :x + :y;
result_mul := :x * :y;
END;
You use the func_add_mul function like a built-in function. See the following example:
CREATETABLE TAB (a Double, b Double);
INSERTINTO TAB VALUES (1.0, 2.0);
INSERTINTO TAB VALUES (3.0, 4.0);
--在使用时,使用点号来提取不同的返回参数值
SELECT a, b, func_add_mul(a, b).result_add asADD, func_add_mul(a,b).result_mul as MUL FROM TAB ORDERBY a;
![]()
You create a function func_mul which is assigned to a scalar variable in the func_mul_wrapper function.
CREATEFUNCTION func_mul(input1 INT) RETURNS output1 INTLANGUAGE SQLSCRIPT
AS
BEGIN
output1 := :input1 * :input1;
END;
CREATEFUNCTION func_mul_wrapper(input1 INT) RETURNS output1 INTLANGUAGE SQLSCRIPT AS
BEGIN
output1 := func_mul(:input1);
END;
SELECT func_mul_wrapper(2) as RESULT FROM dummy;--4
DROPFUNCTION[<schema_name>.]<func_name> [<drop_option>]
<drop_option> ::= CASCADE | RESTRICT
When <drop_option> is not specified a non-cascaded drop will be performed. This will only drop the specified function, dependent objects of the function will be invalidated but not dropped.
The invalidated objects can be revalidated when an object that has same schema and object name is created.
CASCADE:Drops the function and dependent objects.级联删除
RESTRICT:Drops the function only when dependent objects do not exist. If this drop option is used and a dependent object exists an error will be thrown.如果有关联对象删除时会报错
Examples
You drop a function called my_func from the database using a non-cascaded drop.
DROPFUNCTION my_func;
The following tables list the parameters you can use when defining your user-defined functions.
When a function is created, information about the function can be found in the database catalog. You can use his information for debugging purposes. The functions observable in the system views vary according to the privileges that a user has been granted. The following visibility rules apply:
● CATALOG READ or DATA ADMIN – All functions in the system can be viewed.
● SCHEMA OWNER, or EXECUTE – Only specific functions where the user is the owner, or they have execute privileges, will be shown.
元数据视图:
SYS.FUNCTIONS A list of available functions
SYS.FUNCTIONS_PARAMETERS A list of parameters of functions
[IN|OUT] <param_name> {<table_type>|<table_type_definition>}
<table_type_definition> ::= TABLE(<column_list_elements>)
Description:
Table parameters that are defined in the Signature are either input or output. They must be typed explicitly.
This can be done either by using a table type previously defined with the CREATE TYPE command or by writing it directly in the signature without any previously defined table type.
Example:
(IN inputVar TABLE(I INT),OUT outputVar TABLE (I INT, J DOUBLE))
Defines the tabular structure directly in the signature.直接在签名中定义表类型
(IN inputVar tableType, OUT outputVar outputTableType)
Using previously defined tableType and outputTableType table types.使用预定义的表类型
The advantage of previously defined table type is that it can be reused by other procedure and functions. The disadvantage is that you must take care of its lifecycle.使用预先定义好的表类型的好处是可以在不同的过程与函数中重用它,不好的是要小心其生命周期(如删除后,导致使用的的过程函数不能再用)
The advantage of a table variable structure that you directly define in the signature is that you do not need to take care of its lifecycle. In this case, the disadvantage is that it cannot be reused.在过程与函数定义时,在签名中临时定义局部表类型的好处是不有担心其生命周期,不好的是不能重用
6.2 Local Table Variables
Local table variables are, as the name suggests, variables with a reference to tabular data structure. This data
structure originates from an SQL Query.
The type of a table variable in the body of procedure or table function is either derived from the SQL Query or it can be declared explicitly.
表类型的变量可以在过程(或表类型函数)中从SQL Query赋值获得,或明确定义
CREATEprocedure proc() LANGUAGE SQLSCRIPT AS
BEGIN
declare a intdefault 2;--基本类型变量使用前一定要定义
-- 如果某个变量是表类型的变量,可以不用声明,直接就可以使用,这与基本类型变量是不一样的
-- ——基本类型变量使用前需要定义
--declare tab_var1 table(a int,b int); 明确定义,表类型变量可不定义就使用
a := 1;
-- a = 1; 基本类型变量赋值时,等号前一定要加冒号,这与表类型变量恰好相反
tab_var1 = select 1 as a,2 as b from dummy;
--tab_var1 := select 1 as a,2 as b from dummy; 这是错误,表类型变量赋值时,只能使用等号,不能在等号前加冒号,这与基本类型变量赋值相反
END;
If the table variable derived its type from the SQL Query, the SQLScript compiler determines the type from the first assignments of that variable. This provides a great deal of flexibility. One disadvantage however, is that it also lead to many type conversions in the background. This is because sometimes the derived table type does not match the typed table parameters at the signature. This can lead to additional conversion costs, which are unnecessary.如果表类型变量是从某个SQL Query派生而来,在第一次给变量赋值时SQLScript编译器就决定变量的类型。这样有很大的灵活性。然而一个不好的是,这样会导致许多类型在后台发生转换。这是因为有时候派生表类型与签名中的表类型参数不匹,这会导致额外的转换成本
To avoid this unnecessary cost, you can declare the type of a table variable explicitly.避免转换成本,则可以明确定义
Signature定义:
DECLARE <sql_identifier> [{,<sql_identifier> }...] {TABLE (<column_list_definition>)|<table_type>}
Sample Code:
DECLARE temp TABLE (n int);
DECLARE temp MY_TABLE_TYPE;
Description:
Local table variables are declared using the DECLARE keyword. A table variable var can be referenced by using :var. For more information, see Referencing Variables. The <sql_identifier> must be unique among all other scalar variables and table variables in the same code block. You can, however, use names that are identical to the name of another variable in a different code block. Additionally, you can reference these identifiers only in their local scope.局部表变量使用是DECLARE关键进行定义。如表变量var在引用时,:var 这样使用。变量的名不能与其他变量名重名。但,你可以在不同的块中定义相同的变量名,但也只限于本块中使用
CREATEPROCEDURE exampleExplicit (OUT outTab TABLE(n int))
LANGUAGE SQLScript READS SQL DATA AS
BEGIN
DECLARE temp TABLE (n int);
temp = SELECT 1 as n FROM DUMMY ;
BEGIN
DECLARE temp TABLE (n int);--可以在不同的块中定义同名的变量,屏蔽了外层同名变量
temp = SELECT 2 as n FROM DUMMY ;
outTab = Select * from :temp;--执行时,该Select不会显示,原因是外层块又重新给表输出变量outTab重新赋值了
END;
outTab = Select * from :temp;
END;
call exampleExplicit(?);
In each block there are table variables declared with identical names. However, since the last assignment to the output parameter <outTab> can only have the reference of variable <temp> declared in the same block, the result is as follows:
![]()
CREATEPROCEDURE exampleDerived (OUT outTab TABLE(n int))
LANGUAGE SQLScript READS SQL DATA
AS
BEGIN
temp = SELECT 1 as n FROM DUMMY ;
BEGIN
temp = SELECT 2 as n FROM DUMMY ;--由于temp是派生而来,在内层块并没有重新Declare,所以与外层的temp是同一个
outTab = Select * from :temp;--与前面实例一样,在执行时,这个Select也不会显示出来
END;
outTab = Select * from :temp;
END;
call exampleDerived (?);
In this code example, there is no explicit table variable declaration where done, that means the <temp> variable is visible among all blocks. For this reason, the result is as follows:
![]()
Table变量派生法与明确定义的区别(经测试好像不是这样,新版本没有这样的限制了?):
The following declarations are not supported (compare with scalar variable declaration): CONSTANT, NOT NULL option, Default Value.与基本变量声明对比,表类型变量声明时不能使用 CONSTANT, NOT NULL, Default这些
Table variables are bound using the equality operator(表变量只能使用等号赋值=,而不是冒号加等号 :=,这与基本变量赋值恰好相近).
如果是在赋值左边时,直接就是变量名,如果是在赋值右边或其它表达式中时使用该变量时,则使用 :var方式来引用
lt_expensive_books = SELECT title, price, crcy FROM :it_books WHERE price > :minPrice AND crcy = :currency;
In this assignment, the variable <lt_expensive_books>(明确定义的表类型变量是或者是派生的表变量) is bound. The <:it_books> variable in the FROM clause refers to an IN parameter of a table type. It would also be possible to consume variables of type table in the FROM clause which were bound by an earlier statement. <:minPrice> and <:currency> refer to IN parameters of a scalar type.
SELECT * FROM <column_view> ( <named_parameter_list> );
<named_parameter_list> ::= <named_parameter> [{,<named_parameter>}…}]
A list of parameters to be used with the column view.
<named_parameter> ::= <parameter_name> => <expression>
Defines the parameter used to refer to the given expression.
<parameter_name> ::= {PLACEHOLDER.<identifier> | HINT.<identifier> |<identifier>}
The parameter name definition. PLACEHOLDER is used for place holder parameters and HINT for hint parameters.
Description:
Using column view parameter binding it is possible to pass parameters from a procedure/scripted calculation view to a parameterized column view e.g. hierarchy view, graphical calculation view, scripted calculation view.
Examples:
Example 1 - Basic example
In the following example, assume(假设) you have the calculation view CALC_VIEW(计算视图) with placeholder parameters "client" and "currency". You want to use this view in a procedure and bind the values of the parameters during the execution of the procedure.
CREATEPROCEDURE my_proc_caller (IN in_client INT, IN in_currency INT, OUT outtab mytab_t) LANGUAGE SQLSCRIPT READS SQL DATA AS
BEGIN
outtab = SELECT * FROM CALC_VIEW (PLACEHOLDER."$$client$$" => :in_client , PLACEHOLDER."$$currency$$" => :in_currency );
END;
Example 2 - Using a Hierarchical View
The following example assumes that you have a hierarchical column view "H_PROC"(派生列视图?) and you want to use this view in a procedure. The procedure should return an extended expression that will be passed via a variable.
CREATEPROCEDURE"EXTEND_EXPRESSION"(IN in_expr nvarchar(20),OUT out_result "TTY_HIER_OUTPUT")
LANGUAGE SQLSCRIPT READS SQL DATA AS
BEGIN
DECLARE expr VARCHAR(256) := ‘leaves(nodes())‘;
IF :in_expr <> ‘‘THEN
expr := ‘leaves(‘ || :in_expr || ‘)‘;
ENDIF;
out_result = SELECT query_node, result_node FROM h_proc ("expression" => :expr ) as h orderby h.result_node;
END;
You call this procedure as follows.
CALL"EXTEND_EXPRESSION"(‘‘,?);
CALL"EXTEND_EXPRESSION"(‘subtree("B1")‘,?);
The SQLScript compiler combines(合并) statements to optimize code. Hints enable you to block or enforce the inlining of table variables.
Note:Using a HINT needs to be considered carefully. In some cases, using a HINT could end up being more expensive.
Block Statement-Inlining(阻止内联)
The overall optimization guideline in SQLScript states that dependent statements are combined if possible.
For example, you have two table variable assignments as follows:
tab = select A, B, C from T where A = 1;
tab2 = select C from :tab where C = 0;
The statements are combined to one statement(会合并成一条语句) and executed:
select C from (select A,B,C from T where A = 1) where C=0;
There can be situations, however, when the combined statements lead to a non-optimal plan and as a result, to less-than-optimal performance of the executed statement. In these situations it can help to block the combination of specific statements. Therefore SAP has introduced a HINT called NO_INLINE. By placing that HINT at the end of select statement, it blocks the combination (or inlining) of that statement into other statements. An example of using this follows:
tab = select A, B, C from T where A = 1 WITH HINT(NO_INLINE);
tab2 = select C from :tab where C = 0;
By adding WITH HINT (NO_INLINE) to the table variable tab, you can block the combination(阻止合并) of that statement and ensure that the two statements are executed separately.
Enforce Statement-Inlining(迫使内联)
Using the hint called INLINE helps in situations when you want to combine the statement of a nested procedure into the outer procedure.
Currently statements that belong to nested procedure are not combined into the statements of the calling procedures. In the following example, you have two procedures defined.
CREATEPROCEDURE procInner (OUT tab2 TABLE(I int))
LANGUAGE SQLSCRIPT READS SQL DATA
AS
BEGIN
tab2 = SELECT I FROM T;
END;
CREATEPROCEDURE procCaller (OUT table2 TABLE(I int))
LANGUAGE SQLSCRIPT READS SQL DATA
AS
BEGIN
call procInner (outTable);
tab = select I from :outTable where I > 10;
END;
By executing the procedure, ProcCaller, the two table assignments are executed separately. If you want to have both statements combined, you can do so by using WITH HINT (INLINE) at the statement of the output table variable. Using this example, it would be written as follows:
CREATEPROCEDURE procInner (OUT tab2 TABLE(I int))
LANGUAGE SQLSCRIPT READS SQL DATA
AS
BEGIN
tab2 = SELECT I FROM T WITH HINT (INLINE);
END;
Now, if the procedure, ProcCaller, is executed, then the statement of table variable tab2 in ProcInner is combined into the statement of the variable, tab, in the procedure, ProcCaller:
SELECT I FROM (SELECT I FROM T WITH HINT (INLINE)) where I > 10;
In this section we will
focus on imperative language constructs such as loops and conditionals. The use
of
imperative logic splits the logic among several dataflows.
Syntax
DECLARE <sql_identifier> [CONSTANT]
<type> [NOT NULL] [<proc_default>]
Syntax Elements
<proc_default> ::= (DEFAULT | ‘=‘ ) <value>|<expression>
Default value expression assignment.
<value> !!= An element of the type specified by <type>
The value to be assigned to the
variable.
Description
Local variables are declared using
DECLARE keyword and they can optionally be initialized with their declaration.
By default scalar variables are initialized with NULL. A scalar variable var can be referenced the
same way as described above using :var.
Tip
If you want to access(访问) the value of the variable, then use :var(注:如果是在Select…into 后面,则只能是var,因为into相当于赋值,而不是访问,所以不能在前加冒号)in your code. If you
want to assign a value to the variable, then use var in your code.
Assignment is possible
multiple times, overwriting the previous value stored in the scalar variable. Assignment(赋值) is performed using the=(注:这是错误的,基本变量赋值要使用:= 的方式来赋值,如果是赋值给表变量,则才只能使用= ) operator.
Recommendation
SAP recommends that you use only the = operator in defining
scalar variables. (The := operator is still available, however.)
Example
CREATEPROCEDURE proc (OUT z INT) LANGUAGE SQLSCRIPT READS
SQL DATA
AS
BEGIN
DECLARE a int;
DECLARE b int := 0;--定义时,如果需指定默认值,除了使用DEFAULT关键字外,可以使用等号,但前面需要加上冒号:=
DECLARE c intDEFAULT 0;
t = select * from dummy ;
selectcount(*) into a from :t;
b := :a + 1;
z := :b + :c;
end;
In the example you see the various
ways of making declarations and assignments.
Note
Before the SAP HANA SPS 08 release, scalar UDF(标量用户函数) assignment to the scalar variable was not supported. If you wanted to get the result value from a scalar UDF and consume
it in a procedure, the scalar UDF had to be used in a SELECT statement, even though this was expensive. Now
you can assign a scalar UDF to a scalar variable with 1 output or more than 1
output, as depicted in the following code examples.Consuming the result using
an SQL statement:
CREATEFUNCTION SUDF_ADD(input1
INT,input2 INT) RETURNS s INTLANGUAGE SQLSCRIPT AS
BEGIN
s := :input1 + :input2;
END;
CREATEPROCEDURE caller(input1 INT,input2 INT) LANGUAGE SQLSCRIPT AS
BEGIN
DECLARE i INTEGERDEFAULT 0;
SELECT SUDF_ADD(:input1, :input2) into ifrom dummy;--以前版本只能通过Select语句将标量函数返回值赋值给基本变量
select :i from dummy;
END;
call caller(1,2);
Assign the scalar UDF to the scalar
variable:
CREATEPROCEDURE caller(input1 INT,input2 INT) LANGUAGE SQLSCRIPT AS
BEGIN
DECLARE i INTEGERDEFAULT 0;
i := SUDF_ADD(:input1, :input2);--现在可以将标量用户函数的返回值通过等号直接赋值给基本变量
select :i from dummy;
END;
call caller(1,2);
Assign the scalar UDF with more than 1
output to scalar variables:
CREATEFUNCTION xy(input1 INT,input2 INT) RETURNS x INT,y INTLANGUAGE SQLSCRIPT AS
BEGIN
x := input1;
y := input2;
END;
CREATEPROCEDURE caller(input1 INT,input2 INT) LANGUAGE SQLSCRIPT AS
BEGIN
DECLARE i INTEGERDEFAULT 0;
DECLARE j NVARCHAR(5);
--(i,j) := xy(:input1,:input2); --好像不支持这种赋值方法
DECLARE a INTEGERDEFAULT 0;
--a := xy(:input1,:input2).x; -- 这样也不行
select xy(:input1,:input2).x into a from dummy; --这样才可啊,好像只能在Select语句中才能使用点号来取不现的返回值
select a from dummy;
END;
call caller(1,2);
SQLScript supports local variable
declaration in a nested block. Local variables are only
visible in the scope of the block in which they are defined. It is also possible to define local variables inside LOOP /
WHILE /FOR / IFELSE control structures.
Consider the following code:
CREATEPROCEDURE nested_block(OUT val INT) LANGUAGE SQLSCRIPT READS
SQL DATA AS
BEGIN
DECLARE a INT := 1;
BEGIN
DECLARE a INT := 2;
BEGIN
DECLARE a INT;
a := 3;
END;
val := a;
END;
END;
When you call this procedure the
result is:
call nested_block(?)-- 2
From this result you can see that the inner most nested block
value of 3 has not been passed to the val variable. Now let‘s redefine the procedure without the inner
most DECLARE statement:
CREATEPROCEDURE nested_block(OUT val INT) LANGUAGE SQLSCRIPT READS
SQL DATA AS
BEGIN
DECLARE a INT := 1;
BEGIN
DECLARE a INT := 2;
BEGIN
a := 3;
END;
val := a;
END;
END;
Now when you call this
modified procedure the result is:
call nested_block(?)--
3
From this result you can see that the
innermost nested block has used the variable declared in the second level nested
block.
CREATEPROCEDURE nested_block_if(IN inval INT, OUT val INT) LANGUAGE SQLSCRIPT
READS SQL DATA AS
BEGIN
DECLARE a INT := 1;
DECLARE v INT := 0;
--对当前(所在)BEGIN...END块中出现的异常进行捕获,如这里的除0,如不捕获取,则抛异常
--这会导致存储过程不能正常执行完成,得不到运行结果
DECLARE EXIT HANDLER FOR SQLEXCEPTION
BEGIN
val := :a;--赋 1
END;
v := 1 /(1-:inval);
IF :a = 1 THEN
DECLARE a INT := 2;
DECLARE EXIT HANDLER FOR SQLEXCEPTION
BEGIN
val := :a;--赋 2
END;
v := 1 /(2-:inval);
IF :a = 2 THEN
DECLARE a INT := 3;
DECLARE EXIT HANDLER FOR SQLEXCEPTION
BEGIN
val := :a;--赋 3
END;
v := 1 / (3-:inval);
ENDIF;
v := 1 / (4-:inval);--如果程序走到这里,则会为 val = 2,不会是3,因为a = 3所在的IF…END IF块已结束,所以使用外层IF里定义的 a = 2
ENDIF;
v := 1 / (5-:inval);--如果程序走到这里,则会为 val = 1
END;
call nested_block_if(1, ?);-- 1
call nested_block_if(2, ?);-- 2
call nested_block_if(3, ?);-- 3
call nested_block_if(4, ?);-- 2
call nested_block_if(5, ?);-- 1
CREATEPROCEDURE nested_block_while(OUT val INT) LANGUAGE SQLSCRIPT READS SQL
DATA AS
BEGIN
DECLARE v int := 2;
val := 0;
WHILE v > 0 DO
DECLARE a INT := 0;
a := :a + 1;
val := :val + :a;
v := :v - 1;
ENDWHILE;
END;
call nested_block_while(?) -- 2
CREATETABLE mytab1(a int);
CREATETABLE mytab2(a int);
CREATETABLE mytab3(a int);
INSERTINTO mytab1 VALUES(1);
INSERTINTO mytab2 VALUES(2);
INSERTINTO mytab3 VALUES(3);
CREATEPROCEDURE nested_block_for(IN inval INT, OUT val INT) LANGUAGE SQLSCRIPT
READS SQL DATA AS
BEGIN
DECLARE a1 intdefault 0;
DECLARE a2 intdefault 0;
DECLARE a3 intdefault 0;
DECLARE v1 intdefault 1;
DECLARE v2 intdefault 1;
DECLARE v3 intdefault 1;
DECLARECURSOR C FORSELECT * FROM mytab1;
FOR R as C DO
DECLARECURSOR C FORSELECT * FROM mytab2;
a1 := :a1 + R.a;
FOR R as C DO
DECLARECURSOR C FORSELECT * FROM mytab3;
a2 := :a2 + R.a;
FOR R as C DO
a3 := :a3 + R.a;
ENDFOR;
ENDFOR;
ENDFOR;
IF inval = 1 THEN
val := :a1;
ELSEIF inval = 2 THEN
val := :a2;
ELSEIF inval = 3 THEN
val := :a3;
ENDIF;
END;
call nested_block_for(1, ?);--1
call nested_block_for(2, ?);--2
call nested_block_for(3, ?);--3
Note
The example below uses tables and values created in the For Loop example above.
CREATETABLE mytab1(a int);
CREATETABLE mytab2(a int);
CREATETABLE mytab3(a int);
INSERTINTO mytab1 VALUES(1);
INSERTINTO mytab2 VALUES(2);
INSERTINTO mytab3 VALUES(3);
CREATEPROCEDURE nested_block_loop(IN inval INT, OUT val INT) LANGUAGE
SQLSCRIPT READS SQL DATA AS
BEGIN
DECLARE a1 int;
DECLARE a2 int;
DECLARE a3 int;
DECLARE v1 intdefault 1;
DECLARE v2 intdefault 1;
DECLARE v3 intdefault 1;
DECLARECURSOR C FORSELECT * FROM mytab1;
OPEN C;
FETCH C into a1;
CLOSE C;
LOOP
DECLARECURSOR C FORSELECT * FROM mytab2;
OPEN C;
FETCH C into a2;
CLOSE C;
LOOP
DECLARECURSOR C FORSELECT * FROM mytab3;
OPEN C;
FETCH C INTO a3;
CLOSE C;
IF :v2 = 1 THEN
BREAK;
ENDIF;
END LOOP;
IF :v1 = 1 THEN
BREAK;
ENDIF;
END LOOP;
IF :inval = 1 THEN
val := :a1;
ELSEIF :inval = 2 THEN
val := :a2;
ELSEIF :inval = 3 THEN
val := :a3;
ENDIF;
END;
call nested_block_loop(1, ?);--1
call nested_block_loop(2, ?);--2
call nested_block_loop(3, ?);--3
Syntax:
IF <bool_expr1> THEN
<then_stmts1>
[{ELSEIF <bool_expr2> THEN
<then_stmts2>}...]
[ELSE
<else_stmts3>]
ENDIF
Syntax elements:
<bool_expr1> ::= <condition>
<bool_expr2> ::= <condition>
<condition> ::= <comparison> | <null_check>
<comparison> ::= <comp_val> <comparator> <comp_val>
<comp_val> ::=
<scalar_expression>|<scalar_udf>
<scalar_expression>
::=<scalar_value>[{+|-|/|*}<scalar_value>…]
<scalar_value> ::= <numeric_literal> | <exact_numeric_literal>|<unsigned_numeric_literal>
<comparator>
::=< | > | = | <= | >= | !=
<null_check> ::= <comp_val> IS [NOT] NULL
Note:NULLis the default value for all local
variables.NULL是所有局部变量的默认值
CREATEPROCEDURE nullTest() LANGUAGE
SQLSCRIPT READS SQL DATA AS
BEGIN
DECLARE a1 int;--整型没赋值时,也可看作是NULL,只要赋值了,不管是否是0,则会看作是非空
if a1 isnullthen
select‘null‘from dummy;-- 经测试会输出这个
else
select‘not null‘from dummy;
endif;
END;
call nullTest();
Examples:
Example 1
You use the IF statement
to implementing the functionality of the SAP HANA database`s UPSERT statement.
CREATEPROCEDURE upsert_proc (IN v_isbn VARCHAR(20))
LANGUAGE SQLSCRIPT AS
BEGIN
DECLAREfoundINT = 1;
SELECTcount(*) INTOfoundFROM books WHERE isbn = :v_isbn;
IF :found = 0 THEN
INSERTINTO books VALUES (:v_isbn, ‘In-Memory Data Management‘, 1, 1, ‘2011‘, 42.75, ‘EUR‘);
ELSE
UPDATE books SET price = 42.75 WHERE isbn =:v_isbn;
ENDIF;
END;
Example 2
You use the IF statement
to check if variable :found is NULL.
SELECTcount(*) INTOfoundFROM books WHERE isbn = :v_isbn;
IF :found IS NULLTHEN
CALLins_msg_proc(‘result of count(*) cannot be NULL‘);
ELSE
CALLins_msg_proc(‘result of count(*) not NULL - as expected‘);
ENDIF;
Example 3
It is also possible to use a scalar UDF in the condition, as
shown in the following example.
CREATEPROCEDURE proc (in input1 INTEGER, out output1 TYPE1)
AS
BEGIN
DECLARE i INTEGERDEFAULT :input1;
IFSUDF(:i) = 1 THEN
output1 = SELECTvalueFROM T1;
ELSEIF SUDF(:i) = 2 THEN
output1 = SELECTvalueFROM T2;
ELSE
output1 = SELECTvalueFROM T3;
ENDIF;
END;
Syntax:
WHILE <condition>
DO
<proc_stmts>
ENDWHILE
Syntax elements:
<condition> ::= <comparison> | <null_check>
<comparison> ::= <comp_val> <comparator> <comp_val>
<comp_val> ::= <scalar_expression>|<scalar_udf>
<scalar_expression> ::=<scalar_value>[{+|-|/|*}<scalar_value>…]
<scalar_value> ::= <numeric_literal> |
<exact_numeric_literal>|<unsigned_numeric_literal>
<comparator> ::=< | > | = | <= | >= | !=
<null_check> ::= <comp_val> IS [NOT] NULL
Example 1
You use WHILE
to increment the :v_index1 and :v_index2 variables
using nested loops.
CREATEPROCEDURE procWHILE (OUT V_INDEX2 INTEGER) LANGUAGE SQLSCRIPT
READS SQL DATA
AS
BEGIN
DECLARE v_index1 INT := 0;
WHILE :v_index1 < 5 DO
v_index2 := 0;
WHILE :v_index2 < 5 DO
v_index2 := :v_index2 + 1;
ENDWHILE;
v_index1 := :v_index1 + 1;
ENDWHILE;
END;
Example 2
You can also use scalar UDF for the while condition as follows.
CREATEPROCEDURE proc (in input1 INTEGER, out output1 TYPE1)
AS
BEGIN
DECLARE i INTEGERDEFAULT :input1;
DECLARE cnt INTEGERDEFAULT 0;
WHILE SUDF(:i) > 0 DO
cnt := :cnt + 1;
i = :i - 1;
ENDWHILE;
output1 = SELECTvalueFROM T1 where id = :cnt ;
END;
FOR <loop-var> IN [REVERSE] <start_value> .. <end_value> DO
<proc_stmts>
ENDFOR
<loop-var> :用来接收当前循环值的变量
REVERSE:以降序方式循环(从end_value到start_value递减)
<start_value>:大于等于0的整数
<end_value>:大于等于<start_value>
每次循环时,步进值为1
Example 1
CREATEPROCEDURE proc() LANGUAGE SQLSCRIPT
READS SQL DATA
AS
BEGIN
DECLARE i INTEGER;
FOR i IN REVERSE 0..1 DO
select :i from dummy;-- 1 , 0
ENDFOR;
END;
Example 2
You can also use scalar UDF in the FOR loop, as shown in the following example.
CREATEPROCEDURE proc (out output1 TYPE1)LANGUAGE SQLSCRIPT
READS SQL DATA
AS
BEGIN
DECLARE pos INTEGERDEFAULT 0;
DECLARE i INTEGER;
FOR i IN 1..SUDF_ADD(1, 2) DO
pos = :pos + 1;
ENDFOR;
output1 = SELECTvalueFROM T1 whereposition = :i ;
END;
BREAK;
CONTINUE;
BREAK:跳出整个循环
CONTINUE:跳出当前循环,继续下次循环
Example:
You defined the following loop sequence. If the loop value :x is less than 3 the iterations will be
skipped. If :x is 5 then the loop will terminate.
CREATEPROCEDURE proc() LANGUAGE SQLSCRIPT
READS SQL DATA
AS
BEGIN
DECLARE x integer;
FOR x IN 0 .. 10 DO
IF :x < 3 THEN
CONTINUE;
ENDIF;
IF :x = 5 THEN
BREAK;
ENDIF;
ENDFOR;
END;
Cursors are used to fetch single rows from the result set returned by a query. When the cursor is declared it is bound to a query. It is possible to parameterize the cursor query.
Syntax:
CURSOR
<cursor_name> [({<param_def>{,<param_def>} ...)] FOR
<select_stmt>
Syntax elements:
<param_def> = <param_name> <param_type>
Defines an optional SELECT parameter.
<param_type> ::= DATE | TIME | SECONDDATE | TIMESTAMP |
TINYINT| SMALLINT | INTEGER | BIGINT | SMALLDECIMAL | DECIMAL| REAL | DOUBLE |
VARCHAR | NVARCHAR | ALPHANUM| VARBINARY | BLOB | CLOB | NCLOB
Defines the datatype of the parameter.
<select_stmt> !!= SQL SELECT statement.
Defines an SQL select statement. See SELECT.
Description:
Cursors can be defined either after the signature of the
procedure and before the procedure’s body or at the beginning of a block with
the DECLARE token. The cursor is
defined with a name, optionally a list of parameters,and an SQL SELECT statement. The cursor
provides the functionality to iterate through a query result row-byrow.
Updating cursors is not supported.
Note:
Avoid using cursors when it is possible to express the same
logic with SQL. You should do this as cursors cannot be optimized the same way
SQL can.
Example:
You create a cursor c_cursor1 to iterate over results from a SELECT
on the books table. The cursor passes one parameter v_isbn
to the SELECT statement.
DECLARECURSOR c_cursor1
(v_isbn VARCHAR(20)) FOR
SELECT isbn, title, price, crcy FROM books WHERE isbn = :v_isbn ORDERBY isbn;
Syntax:
OPEN
<cursor_name>[(<argument_list>)]
Syntax elements:
<argument_list> ::= <arg>[,{<arg>}...]
Specifies one or more arguments to be passed to the select
statement of the cursor.
<arg> ::= <scalar_value>
Specifies a scalar value to be passed to the cursor.
Description:
Evaluates the query bound to a cursor and opens the cursor so
that the result can be retrieved. When the cursor definition contains
parameters then the actual values for each of these parameters must be provided
when the cursor is opened.
Example:
You open the cursor c_cursor1 and pass a string ‘978-3-86894-012-1‘ as a parameter.
OPEN c_cursor1(‘978-3-86894-012-1‘);
Syntax:
CLOSE
<cursor_name>
Description:
Closes a previously opened cursor and releases all associated
state and resources. It is important to close all cursors that were previously
opened.
Example:
You close the cursor c_cursor1.
CLOSE c_cursor1;
Syntax:
FETCH
<cursor_name> INTO <variable_list>
Syntax elements:
<variable_list> ::= <var>[,{<var>}...]
Specifies the variables where the row result from the cursor
will be stored.
<var> ::= <identifier>
Specifies the identifier of a variable.
Description:
Fetches a single row in the result set of a query and advances(使前进) the cursor to the next row. This assumes(前提)
that the cursor was declared and opened before. One can use the cursor
attributes to check if the cursor points to a valid row. See Attributes of a Cursor
Example:
You fetch a row from the cursor c_cursor1
and store the results in the variables shown.
FETCH c_cursor1 INTO v_isbn, v_title,
v_price, v_crcy;
A cursor provides a number of methods to examine its current state. For a cursor bound to variable c_cursor1, the attributes summarized in the table below are available.

Example:
The example below shows a complete procedure using the
attributes of the cursor c_cursor1 to check if fetching a set of results is possible.
CREATEPROCEDURE cursor_proc LANGUAGE SQLSCRIPT AS
BEGIN
DECLARE v_isbn VARCHAR(20);
DECLARE CURSOR c_cursor1 (v_isbn VARCHAR(20)) FOR
SELECT isbn, title, price, crcy FROM books WHERE isbn = :v_isbn ORDERBY isbn;
OPEN c_cursor1(‘978-3-86894-012-1‘);
IF c_cursor1::ISCLOSEDTHEN
CALLins_msg_proc(‘WRONG: cursor not open‘);
ELSE
CALLins_msg_proc(‘OK: cursor open‘);
ENDIF;
FETCH c_cursor1 INTO v_isbn, v_title, v_price, v_crcy;
IF c_cursor1::NOTFOUNDTHEN
CALLins_msg_proc(‘WRONG: cursor contains no valid data‘);
ELSE
CALLins_msg_proc(‘OK: cursor contains valid data‘);
ENDIF;
CLOSE c_cursor1;
END
Syntax:
FOR <row_var>
AS
<cursor_name>[(<argument_list>)] DO
<proc_stmts> | {<row_var>.<column>}
ENDFOR
该语句会自动打开(Open)光标、读取(Fetch)光标、并且循环完后关闭(Close)光标
Syntax elements:
<row_var> ::= <identifier>
Defines an identifier to contain the row result.
<cursor_name> ::= <identifier>
Specifies the name of the cursor to be opened.
<argument_list> ::= <arg>[,{<arg>}...]
Specifies one or more arguments to be passed to the select
statement of the cursor.
<arg> ::= <scalar_value>
Specifies a scalar value to be passed to the cursor.
<proc_stmts> ::= !! SQLScript procedural statements
Defines the procedural statements that will be looped over.
<row_var>.<column> ::= !! Provides attribute access
To access the row result attributes in the body of the loop you
use the syntax shown.
Description:
Opens a previously declared cursor and iterates over each row in the result set of
the query bound to the cursor. For each row in the result set the statements in
the body of the procedure are executed. After the last row from the cursor has
been processed, the loop is exited and the cursor is closed.
Tip
As this loop method takes care of opening and closing cursors,
resource leaks(资源泄漏) can be avoided. Consequently(因此) this loop is
preferred(首先) to opening and closing a cursor explicitly and using other
loop-variants. Within the loop body, the attributes of the row that the cursor
currently iterates over can be accessed like an attribute of the cursor.
Assuming假设<row_var> is a_row and the iterated data contains a
column test, then the value of this column can be
accessed using a_row.test.
Example:
The example below demonstrates using a FOR-loop to loop over the results from c_cursor1
.
CREATEPROCEDURE foreach_proc() LANGUAGE SQLSCRIPT AS
BEGIN
DECLARE v_isbn VARCHAR(20) := ‘‘;
DECLARECURSOR c_cursor1 (v_isbn VARCHAR(20)) FOR
SELECT isbn, title, price, crcy FROM books ORDERBY isbn;
FOR cur_row as c_cursor1 DO
CALLins_msg_proc(‘book title is: ‘ || cur_row.title);
ENDFOR;
END;
Syntax:
BEGIN AUTONOMOUS TRANSACTION
[<proc_decl_list>]
[<proc_handler_list>]
[<proc_stmt_list>]
END;
Description:
The autonomous transaction(独立事务) is independent(不依赖) from the main procedure(主存储过程块). Changes made and
committed by an autonomous transaction can be stored in persistency regardless
of commit/rollback of the main procedure transaction(不管主存储过程是否提交或回滚,独立事务块都会受其影响,而是按自己内存). The end of the autonomous transaction block has an implicit
commit.
BEGIN AUTONOMOUS TRANSACTION
…(some updates) –(1)
COMMIT;
…(some updates) –(2)
ROLLBACK;
…(some updates) –(3)
END;
The examples show how commit and rollback work inside the autonomous transaction block. The first updates (1) are committed, whereby the updates made in step (2) are completely rolled back. And the last updates (3)are committed by the implicit commit at the end of the autonomous block.
createtable
ERR_TABLE(PARAMETER int,SQL_ERROR_CODE int,SQL_ERROR_MESSAGE
VARCHAR(5000));
CREATEPROCEDURE PROC1( IN p INT,OUT outtab TABLE (A DECIMAL) ) LANGUAGE SQLSCRIPT
AS
BEGIN
DECLARE errCode INT;
DECLARE errMsg VARCHAR(5000);
DECLARE EXIT HANDLER FOR SQLEXCEPTION --外层BEGIN…END块的异常处理块,即如果外层中的脚本语句执行出异常后,就会走这段(内层BEGIN…END块处理逻辑),如果传进来的是0,则会抛被0除的异常,该异常处理块会捕获到并处理(将异常信息存储到ERR_TABLE表中)
BEGIN AUTONOMOUS TRANSACTION -- 异常处理块
errCode := ::SQL_ERROR_CODE; --这个好像是全局的变量,但只能是 AUTONOMOUS TRANSACTION 块里使用,用来捕获异常号
errMsg := ::SQL_ERROR_MESSAGE;
INSERTINTO ERR_TABLE (PARAMETER,SQL_ERROR_CODE, SQL_ERROR_MESSAGE) VALUES ( :p, :errCode, :errMsg);
END;
outtab = SELECT 1/:p as A FROM DUMMY; -- DIVIDE BY ZERO Error if p=0
END;
call PROC1(0,?);
In the example above, an autonomous transaction is used to keep
the error code in the ERR_TABLE stored in persistency.
If the exception handler block were not an autonomous transaction, then every
insert would be rolled back because they were all made in the main transaction.
In this case the result of the ERR_TABLE is as shown in the following example.

It is also possible to have nested autonomous transactions.
CREATEPROCEDURE P2()
ASBEGIN
BEGIN AUTONOMOUS TRANSACTION
INSERTINTO LOG_TABLE VALUES (‘MESSAGE‘);
BEGIN AUTONOMOUS TRANSACTION
ROLLBACK;
END;
END;
END;
The LOG_TABLE
table contains ‘MESSAGE‘, even though the inner autonomous transaction rolled back.
Supported statements inside the
block独立事务块里支持的语句
● SELECT, INSERT, DELETE, UPDATE, UPSERT, REPLACE
● IF, WHILE, FOR, BEGIN/END
● COMMIT, ROLLBACK, RESIGNAL, SIGNAL
● Scalar variable assignment
Unsupported statements inside the block不支持的语句
● DDL
● Cursor
● Table assignments
The COMMIT
and ROLLBACK commands
are supported natively in SQLScript.
The COMMIT command commits the
current transaction and all changes before the COMMIT
command is written to persistence.
The ROLLBACK command rolls back the
current transaction and undoes all changes since
the last COMMIT.
在COMMIT、ROLLBACK执行的一,都会重新开启一个新的事务
Example 1:
CREATEPROCEDURE PROC1() AS
BEGIN
UPDATE B_TAB SET V = 3 WHERE ID = 1;
COMMIT; --上一更新语句会生效
UPDATE B_TAB SET V = 4 WHERE ID = 1;
ROLLBACK; --上一更新语句不会生效
END;
Example 2:
CREATEPROCEDURE PROC2() AS
BEGIN
UPDATE B_TAB SET V = 3 WHERE ID = 1;
COMMIT;
END;
CREATEPROCEDURE PROC1() AS
BEGIN
UPDATE A_TAB SET V = 2 WHERE ID = 1;
CALL PROC2();--PROC2存储过程里的更新一并会被提交
UPDATE A_TAB SET V = 3 WHERE ID = 1;
ROLLBACK;
END;
Dynamic SQL allows you to construct an
SQL statement during the execution time of a procedure. While dynamic SQL
allows you to use variables where they might not be supported in SQLScript and
also provides more flexibility in creating SQL statements, it does have the
disadvantage缺点 of an additional cost at runtime:
● Opportunities for optimizations are
limited.性能优化受到限制
● The statement is potentially
recompiled every time the statement is executed.每次执行时需要重新编译
● You cannot use SQLScript variables in
the SQL statement.不能使用SQL脚本变量
● You cannot bind the result of a
dynamic SQL statement to a SQLScript variable.不能将动态SQL的结果赋值给SQL脚本变量
● You must be very careful to avoid SQL
injection bugs that might harm the integrity or security of the database.有SQL注入漏洞风险
Note
You should avoid dynamic SQL wherever possible as it can have a
negative impact on security or performance.因为性能与安全,尽量少使用动态SQL
Syntax:
EXEC
‘<sql-statement>‘
Description:
EXEC executes the SQL statement passed in a
string argument.
Example:
You use dynamic SQL to insert a string into the message_box table.
v_sql1
= ‘Third
message from Dynamic SQL‘;
EXEC ‘INSERT INTO message_box VALUES (‘‘‘ || :v_sql1 || ‘‘‘)‘;
Syntax:
EXECUTEIMMEDIATE‘<sql-statement>‘
Description:
EXECUTE IMMEDIATE executes the SQL statement
passed in a string argument. The results of queries executed with EXECUTE IMMEDIATE are appended to the
procedures result iterator.
EXECUTE IMMEDIATE一般用来执行动态查询,让结果附加到存储过程迭代器中
Example:
You use dynamic SQL to delete the contents of table tab, insert a value and finally to
retrieve all results in the table.
CREATETABLE tab (i int);
CREATEPROCEDURE proc_dynamic_result2(i int) AS
BEGIN
EXEC ‘DELETE from tab‘;
EXEC ‘INSERT INTO tab VALUES (‘ || :i || ‘)‘;
EXECUTEIMMEDIATE‘SELECT * FROM tab ORDER BY i‘;
END;
该函数可以动态查询某个表(物理表或表变量),条件是动态的
Syntax
<variable_name>
= APPLY_FILTER(<table_or_table_variable>,<filter_variable_name>);
Syntax Elements
<variable_name> ::= <identifier>
The variable where the result of the APPLY_FILTER function will
be stored. <variable_name>应该是一个表变量,用来接收APPLY_FILTER函数返回的结果
<table_or_table_variable> ::= <table_name> |
<table_variable>
You can use APPLY_FILTER with persistent tables(物理表) and table variables.
<table_name> :: = <identifier>
The name of the table(物理表) that is to be filtered.
<table_variable> ::= :<identifier>
The name of the table variable(表变量)
to be filtered.
<filter_variable_name> ::= <string_literal>
The filter command to be applied.
Description
The APPLY_FILTER function applies a dynamic filter on a table or
table variable. Logically it can be considered a partial dynamic sql statement.
The advantage of the function is that you can assign it to a table variable and
will not block sql – inlining. Despite this all other disadvantages of a full
dynamic sql yields also for the APPLY_FILTER.
Examples
Example 1 - Apply a filter on a persistent table(在物理表上应用过滤器)
You create the following procedure
CREATEPROCEDURE
GET_PROCEDURE_NAME (IN filter NVARCHAR(100),
OUT procedures table(SCHEMA_NAME NVARCHAR(256), PROCEDURE_NAME NVARCHAR(256))) AS
BEGIN
temp_procedures = APPLY_FILTER(SYS.PROCEDURES,:filter);-- SYS.PROCEDURES为物理表,APPLY_FILTER函数返回的是结果集。由于接收的表结果,所以temp_procedures可以不定义直接使用。Filter是传进来的条件串
procedures = SELECT SCHEMA_NAME, PROCEDURE_NAME FROM :temp_procedures;
END;
You call the procedure with two
different filter variables.
CALL
GET_PROCEDURE_NAME(‘ PROCEDURE_NAME like ‘‘TREX%‘‘‘, ?);
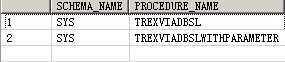
CALL GET_PROCEDURE_NAME(‘ SCHEMA_NAME = ‘‘SYS‘‘‘, ?);

Example 2 - Using a table variable(在表变量上应用过滤器)
CREATEPROCEDURE
GET_PROCEDURE_NAME (IN filter NVARCHAR(100),
OUT procedures table(SCHEMA_NAME NVARCHAR(256), PROCEDURE_NAME NVARCHAR(256))) AS
BEGIN
temp_procedures = SELECT SCHEMA_NAME, PROCEDURE_NAME FROM SYS.PROCEDURES;
procedures = APPLY_FILTER(:temp_procedures,:filter);-- temp_procedures为表变量,这里即从表变量查询,查询条件为传进来的filter查询串
END;
CALL GET_PROCEDURE_NAME(‘ PROCEDURE_NAME like ‘‘TREX%‘‘‘, ?);
CALL GET_PROCEDURE_NAME(‘ SCHEMA_NAME = ‘‘SYS‘‘‘, ?);
结果与前面例子是一样的
Note
The following constructs are not supported in the filter string
<filter_variable_name>:
● •
sub-queries, for example: CALL GET_PROCEDURE_NAME(‘PROCEDURE_NAME
in (SELECT object_name
FROM SYS.OBJECTS)‘, ?); 过滤器中不支持子查询
● • fully-qualified column names, for
example:CALL GET_PROCEDURE_NAME(‘PROCEDURE.PROCEDURE_NAME
= ‘‘DSO‘‘‘, ?); 过滤器中不能使用full-qualified column names全限定的列名称(带表名的前缀列名)
Exception handling is a method for handling exception and completion结束 conditions in an SQLScript procedure.
Syntax
<proc_handler>::=
DECLARE EXIT HANDLER FOR
<proc_condition_value_list> <proc_stmt>
Note
This is a syntax fragment from the CREATE PROCEDURE statement.
For the full syntax see, CREATE PROCEDURE.
Description
The DECLARE EXIT HANDLER parameter allows you to define
exception handlers to process exception conditions in your procedures. You can
explicitly signal an exception and completion condition within your code using
SIGNAL and RESIGNAL.
Syntax
DECLARE <condition
name> CONDITION [ FOR <sqlstatevalue> ]
Note
This is a syntax fragment from the CREATE PROCEDURE statement.
For the full syntax see, CREATE PROCEDURE.
Description
You use the DECLARE CONDITION parameter(参数化) to name exception conditions, and optionally, their associated
SQL state values.
Syntax
SIGNAL <signal value> [<set signal
information>]
RESIGNAL [<signal value>] [<set signal information>]
Note
This is a syntax fragment from the CREATE PROCEDURE statement.
For the full syntax see, CREATE PROCEDURE.
Description
You use the SIGNAL and RESIGNAL directives in your code to
trigger exception states.
You can use SIGNAL or RESIGNAL with specified error code in user-defined error
code range. A user-defined exception can be handled by the handler declared in
the procedure. Also it can be also handled by the caller which can be another
procedure or client.
General exception handling通用异常捕获
General exception can be handled with exception handler declared
at the beginning of statements which make an explicit or implicit signal
exception.
CREATETABLE MYTAB (I INTEGERPRIMARYKEY);
CREATEPROCEDURE MYPROC AS
BEGIN
DECLARE EXIT HANDLER FOR SQLEXCEPTION -- 处理异常,SQLEXCEPTION能捕获所有异常,相当于Java中的Excepton?
SELECT ::SQL_ERROR_CODE, ::SQL_ERROR_MESSAGE FROM DUMMY;
INSERTINTO MYTAB VALUES (1);
INSERTINTO MYTAB VALUES (1); -- expected unique violation error: 301
-- will not be reached
END;
CALL MYPROC();
Error code exception handling通过异常码
An exception handler can be declared that catches exceptions
with a specific error code numbers.
CREATETABLE MYTAB (I INTEGERPRIMARYKEY);
CREATEPROCEDURE MYPROC AS
BEGIN
--具体指定要抓取哪一种异常代码
DECLARE EXIT HANDLER FOR SQL_ERROR_CODE 301 --301:违返唯一约束异常。如果要具体捕获某一种异常,则使用SQL_ERROR_CODE+异常码
SELECT ::SQL_ERROR_CODE, ::SQL_ERROR_MESSAGE FROM DUMMY;
INSERTINTO MYTAB VALUES (1);
INSERTINTO MYTAB VALUES (1); -- expected unique violation error: 301
END;
CREATETABLE MYTAB (I INTEGERPRIMARYKEY);
CREATEPROCEDURE MYPROC AS
BEGIN
DECLARE myVar INT;
DECLARE EXIT HANDLER FOR SQL_ERROR_CODE 1299 --使用SELECT I INTO为某个量赋值时,如果没有值,则会抛出异常
BEGIN
SELECT 0 INTO myVar FROM DUMMY;
SELECT ::SQL_ERROR_CODE, ::SQL_ERROR_MESSAGE FROM DUMMY;
SELECT :myVar FROM DUMMY;
END;
SELECT I INTO myVar FROM MYTAB; --如果没有数据,这里会抛出 NO_DATA_FOUND exception
SELECT‘NeverReached_noContinueOnErrorSemantics‘FROM DUMMY;
END;
Conditional Exception Handling根据异常条件变量捕获
Exceptions can be declared using a CONDITION
variable. The CONDITION can optionally be specified with an error code number.
CREATETABLE MYTAB (I INTEGERPRIMARYKEY);
CREATEPROCEDURE MYPROC AS
BEGIN
DECLARE MYCOND CONDITION FOR SQL_ERROR_CODE 301;--将异常代码定义成条件变量
DECLARE EXIT HANDLER FOR MYCOND --直接使用上面定义的异常条件变量
SELECT ::SQL_ERROR_CODE, ::SQL_ERROR_MESSAGE FROM DUMMY;
INSERTINTO MYTAB VALUES (1);
INSERTINTO MYTAB VALUES (1); -- expected unique violation error: 301
-- will not be reached
END;
Signal an exception手动抛出自定义异常
The SIGNAL statement
can be used to explicitly raise an exception from within your procedures.
Note
The error code used must be within the
user-defined range of 10000 to 19999.
CREATETABLE MYTAB (I INTEGERPRIMARYKEY);
CREATEPROCEDURE MYPROC AS
BEGIN
DECLARE MYCOND CONDITION FOR SQL_ERROR_CODE 10001;
--DECLARE EXIT HANDLER FOR MYCOND SELECT ::SQL_ERROR_CODE, ::SQL_ERROR_MESSAGE FROM DUMMY;
INSERTINTO MYTAB VALUES (1);
SIGNAL MYCOND SET MESSAGE_TEXT = ‘my error‘;--手动抛出异常,如果去掉上面定义的异常处理块,则数据不会插入到表中,因为产生了异常并未捕获
-- will not be reached
END;
CALL MYPROC();
![]()
Resignal an exception重新抛出异常
The RESIGNAL statement raises an exception on the action
statement in exception handler. If error code is not specified, RESIGNAL will
throw the caught exception.
CREATETABLE MYTAB (I INTEGERPRIMARYKEY);
CREATEPROCEDURE MYPROC AS
BEGIN
DECLARE MYCOND CONDITION FOR SQL_ERROR_CODE 10001;
DECLARE EXIT HANDLER FOR MYCOND RESIGNAL;--捕获但不处理异常,捕获到后重新抛出,注:最后数据还是没有插入,因为异常未被处理
INSERTINTO MYTAB VALUES (1);
SIGNAL MYCOND SET MESSAGE_TEXT = ‘my error‘;--抛异常
-- will not be reached
END;
CALL MYPROC();
Nested block exceptions.嵌套块异常
You can declare exception handlers for nested blocks.
CREATETABLE MYTAB (I INTEGERPRIMARYKEY);
CREATEPROCEDURE MYPROC AS
BEGIN
--内嵌异常层层向上抛出,最后从这里(最上层)抛出,重抛前设置错误消息。最终因为异常未被处理,所以数据最终还是没有被插入到表中
DECLARE EXIT HANDLER FOR SQLEXCEPTION RESIGNAL SET MESSAGE_TEXT = ‘level 1‘;
BEGIN
DECLARE EXIT HANDLER FOR SQLEXCEPTION RESIGNAL SET MESSAGE_TEXT = ‘level 2‘;
INSERTINTO MYTAB VALUES (1);
BEGIN
DECLARE EXIT HANDLER FOR SQLEXCEPTION RESIGNAL SET MESSAGE_TEXT = ‘level 3‘;
INSERTINTO MYTAB VALUES (1); -- expected unique violation error: 301
-- will not be reached
END;
END;
END;
CALL MYPROC();
上面实例最终因为异常抛到最上层也没有处理,导致数据最终没有插入到表中,但如果MYPROC在另一过程中调用,并且处理重抛出的异常,则数据能插入到表中,如:
CREATEPROCEDURE MYPROC2 AS
BEGIN
DECLARE EXIT HANDLER FOR SQLEXCEPTION SELECT ::SQL_ERROR_CODE, ::SQL_ERROR_MESSAGE FROM DUMMY;
CALL MYPROC();
END;
call MYPROC2();
Syntax
ARRAY(<value_expression>
[{, <value_expression>}...])
Syntax Elements
<value_expression> ::= <string_literal> |
<number>
The array can contain strings or numbers.
Description
The ARRAY function returns an array whose elements are specified
in the list of value expressions.
Examples
You define an integer array that contains the numbers 1,2 and 3.
DECLARE array_id INTEGER ARRAY :=
ARRAY(1, 2, 3);
Syntax
<array_name>
<type> ARRAY [=
<array_constructor>]
Syntax Elements
<array_variable> ::= <identifier>
The variable that will contain the array.
<type> ::= DATE | TIME| TIMESTAMP | SECONDDATE | TINYINT |
SMALLINT | INTEGER | BIGINT | DECIMAL | SMALLDECIMAL | REAL | DOUBLE| VARCHAR |
NVARCHAR | ALPHANUM | VARBINARY | CLOB | NCLOB |BLOB
The data type for the array elements.
<array_constructor> ::= ARRAY(<value_expression> [{, <value_expression>}...])
Defines the array elements. For more information, see ARRAY CONSTRUCTOR
Description
Declare an array variable whose element type is <type>,
which represents one of the SQL types.
Currently only an unbounded ARRAY is supported with a maximum cardinality of 2^31. You cannot
define a static-size for an array.
Examples
Example 1
You define an empty array of type INTEGER.
DECLARE array_int INTEGER ARRAY;--定义一个空的数组
Example 2
You define an INTEGER array with values 1,2 and 3.
DECLARE array_int INTEGER ARRAY :=
ARRAY(1, 2, 3);
Syntax
:<array_variable>
[ <array_index> ] := <value_expression> 注:这里的中括号是数组的一部分,而非语法中的可选项
Syntax Elements
<array_variable> ::= <identifier>
The array to be operated upon.
<array_index> ::= <unsigned_integer>
The index of the element in the array to be modified. <array_index> can be any value
from 1 to 2^31.
Note:The array index starts with the index 1。注:数组索引是从1开始的
<value_expression> ::= <string_literal> | <number>
The value to which the array element should be set.
Description
The array element specified by <array_index>
can be set to <value_expression>.
Examples
You create an array with the values 1,2,3. You add 10 to
the first element in the array.
DECLARE id Integer ARRAY :=
ARRAY(1, 2, 3);
id[1] := :id[1] + 10;
Syntax
<scalar_variable>
:= <array_variable> [ <array_index>]
Syntax Elements
<scalar_variable> :: = <identifier>
The variable where the array element will be assigned.
<array_variable> ::= <identifier>
The target array where the element is to be obtained from.
<array_index> ::= <unsigned_integer>
The index of the element to be returned. <array_index> can
be any value from 1 to 2,147,483,646.
Description
The value of the array element specified by <array_index
given_index> can be returned. The array element can be referenced in SQL
expressions.
Example
You create and call the following procedure.
CREATEPROCEDURE ReturnElement (OUToutputINT) AS
BEGIN
DECLARE id INTEGER ARRAY := ARRAY(1, 2, 3);
DECLARE n INTEGER := 1;
output := :id[:n];
END;
call ReturnElement(?);
![]()
将某个(多个)数组转换为Table
Syntax
UNNEST(:<array_variable>
[ {, :array_variable} ...] )[WITH ORDINALITY] [AS
<return_table_specification>)]
Syntax Elements
<array_variable> ::= <identifier>
The array to be operated upon.
WITH ORDINALITY
Specifies that an ordinal column will be appended to the
returned table(在合并结果表格中加一列序列表用来在存储元素在数组中的顺序,即索引?). When you use this, you must explicitly specify an alias for
the ordinal column(如果指定了这个选项,则必须明确指定这个序列列名).
For more information, see Example 2 where "SEQ" is specified as the alias.
<return_table_specification> ::= (<column_name> [ {,
column_name}… ])
The column names of the returned table 指定返回的结果表格每列的列名.
<column_name> ::= <identifier>
The name of a column in the returned table.
Description
The UNNEST function
converts an array into a table.UNNEST returns a table including
a row for each element of the array specified. If there are multiple arrays
given, the number of rows will be equal to the largest cardinality among the cardinalities
of the arrays. In the returned table, the cells that are not corresponding to
the elements of the arrays are filled with NULL
values.
Note
The UNNEST function
cannot be referenced directly in FROM clause of a SELECT statement.
Examples
Example 1
You use UNNEST to obtain the values of an ARRAY
id and name in which the cardinality differs.
CREATEPROCEDURE
ARRAY_UNNEST_SIMPLE()
LANGUAGE SQLSCRIPT SQL SECURITY INVOKER AS
BEGIN
DECLARE id INTEGER ARRAY;
DECLARE name VARCHAR(10) ARRAY;
id[1] := 1;
id[2] := 2;
name[1] := ‘name1‘;
name[2] := ‘name2‘;
name[3] := ‘name3‘;
name[5] := ‘name5‘;
rst = UNNEST(:id, :name) AS ("ID", "NAME");
SELECT * FROM :rst;
END;
CALL ARRAY_UNNEST_SIMPLE();
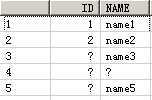
如果不指定返回表格中的列名:
rst = UNNEST(:id, :name) ;
结果为:
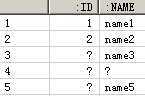
Example 2
You use UNNEST with the WITH ORDINALITY directive to generate a
sequence column along with the results set .
CREATEPROCEDURE ARRAY_UNNEST()
LANGUAGE SQLSCRIPT SQL SECURITY INVOKER AS
BEGIN
DECLARE amount INTEGER ARRAY := ARRAY(10, 20);
rst = UNNEST( :amount) WITH ORDINALITY AS ( "AMOUNT", "SEQ");
select SEQ, AMOUNT from :rst;
END;
![]()
将表中的列转换为数组
Syntax
ARRAY_AGG
(:<table_variable>.<column_name> [<order_by_clause>])
Syntax Elements
<table_variable> ::= <identifier>
The name of the table variable to be converted.
<column_name>::= <identifier>
The name of the column, within the table variable, to be
converted.
<order_by_clause> ::= ORDER BY {
<order_by_expression>, ... }
The ORDER BY clause
is used to sort records by expressions or positions.
<order_by_expression> ::= <expression> [ ASC | DESC
] [ NULLS FIRST | NULLS LAST ]
Specifies the ordering of data.
ASC | DESC
ASC sorts records in ascending order. DESC
sorts records in descending order. The default is ASC.
NULLS FIRST | NULLS LAST
Specifies where in the results set NULL
values should appear(设定NULL如何参与排序). By default for ascending ordering NULL
values are returned first, and for descending they are returned
last. You can override this behavior using NULLS
FIRST or NULLS LAST to
explicitly specify NULL value
ordering.
Description
The ARRAY_AGG function
converts a column of a table into an array.
Note
ARRAY_AGG function does not support
using value expressions instead of table variables.
Examples
You create the following table and procedure.
CREATETABLE tab1 (a INT, b INT, c INT);
INSERTINTO tab1 VALUES (1, 4, 1);
INSERTINTO tab1 VALUES (2, 3, 2);
CREATEPROCEDURE ARRAY_AGG_TEST()
LANGUAGE SQLSCRIPT SQL SECURITY INVOKER AS
BEGIN
DECLARE id Integer ARRAY;
tab = SELECT * FROM tab1;
id := ARRAY_AGG(:tab.a ORDERBY c asc , b DESC);--将表中的列转换为数组
rst = UNNEST(:id);--将数组转换为表格
SELECT * FROM :rst;
END;
CALL ARRAY_AGG_TEST();
![]()
从尾部删除指定个数的数组元素,并返回删除过的新数组
Syntax
TRIM_ARRAY(:<array_variable>,
<trim_quantity>)
Syntax Elements
<array_variable> ::= <identifier>
The array to be operated upon.
<trim_quantity> ::= <unsigned_integer>
The number of elements to be removed.要删除多少个(从尾部删)
Description
The TRIM_ARRAY function
removes elements from the end of an array. TRIM_ARRAY
returns a new array with a <trim_quantity> number of
elements removed from the end of the array, <array_variable>.
Examples
You create the following procedure.
CREATEPROCEDURE ARRAY_TRIM()
LANGUAGE SQLSCRIPT SQL SECURITY INVOKER AS
BEGIN
DECLARE array_id Integer ARRAY := ARRAY(0, 1, 2);
array_id := TRIM_ARRAY(:array_id, 1);
rst1 = UNNEST(:array_id) as ("ID");
select * from :rst1 orderby"ID";
END;
![]()
返回数组的长度
Syntax
CARDINALITY(:<array_variable>)
Syntax Elements
<array_variable> ::= <identifier>
The array to be operated upon.
Description
The CARDINALITY function returns the number of elements in the
array <array_variable>. It returns N (>= 0) if the index of the N-th
element is the largest among the indices.
Example
Example 1
CREATEPROCEDURE CARDINALITY_1()
AS
BEGIN
DECLARE array_id Integer ARRAY := ARRAY(1, 2, 3);
DECLARE n Integer;
n := CARDINALITY(:array_id);
select :n as card from dummy;
END;
CALL CARDINALITY_1(); -- 3
Example 2
CREATEPROCEDURE CARDINALITY_2()
AS
BEGIN
DECLARE array_id Integer ARRAY;
DECLARE n Integer;
n := CARDINALITY(:array_id);
select :n as card from dummy;
END;
CALL CARDINALITY_2();-- 0
Example 3
CREATEPROCEDURE CARDINALITY_3()
AS
BEGIN
DECLARE array_id Integer ARRAY;
DECLARE n Integer;
array_id[20] := NULL;
n := CARDINALITY(:array_id);
select :n as card from dummy;
END;
CALL CARDINALITY_3();-- 20
合并数组,将两个数组合并起来
Syntax
:<array_variable_left>
|| :<array_variable_right>
or
CONCAT(<array_variable_left>
, <array_variable_right> )
Syntax Elements
<array_variable_left> ::= <identifier>
The first array to be concatenated.
<array_variable_right> ::= <identifier>
The second array to be concatenated.
Description
The concat function concatenates two arrays. It returns the new
array that contains a concatenation of <array_variable_left> and
<array_variable_right>.
Examples
CREATEPROCEDURE
ARRAY_COMPLEX_CONCAT3()
LANGUAGE SQLSCRIPT SQL SECURITY INVOKER AS
BEGIN
DECLARE id1 INTEGER ARRAY;
DECLARE id2 INTEGER ARRAY;
DECLARE id3 INTEGER ARRAY;
DECLARE id4 INTEGER ARRAY;
DECLARE id5 INTEGER ARRAY;
DECLARE card INTEGER ARRAY;
id1[1] := 0;
id2[1] := 1;
id3 := CONCAT(:id1, :id2);-- 0,1
id4 := :id1 || :id2;-- 0,1
rst = UNNEST(:id3) WITH ORDINALITY AS ("id", "seq");-- 0,1
id5 := :id4 || ARRAY_AGG(:rst."id"ORDERBY"seq");-- 0,1,0,1
rst1 = UNNEST(:id5 || CONCAT(:id1, :id2) || CONCAT(CONCAT(:id1, :id2),CONCAT(:id1, :id2))) WITH ORDINALITY AS ("id", "seq");
SELECT"seq", "id"FROM :rst1 ORDERBY"seq";
END;
CALL ARRAY_COMPLEX_CONCAT3();
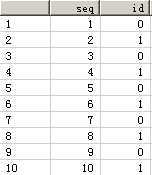
Recommendation建议
SAP recommends that you use SQL rather than Calculation Engine
Plan Operators with SQLScript(推荐使用SQL方式,而不是SQLScript,如CE Founction).The
execution of Calculation Engine Plan Operators currently is bound to processing
within the calculation engine and does not allow a possibility to use
alternative execution engines, such as L native execution. As most Calculation
Engine Plan Operators are converted internally and treated as SQL operations,
the conversion requires multiple layers of optimizations. This can be avoided
by direct SQL use. Depending on your system configuration and the version you
use, mixing Calculation Engine Plan Operators and SQL can lead to significant
performance penalties when compared to to plain SQL implementation.
Table 18: Overview: Mapping between CE_* Operators and SQL
|
|
CE Operator CE函数 |
CE Syntax 用法 |
SQL Equivalent等效SQL |
|
数据访问 Data Source Access operators |
CE_COLUMN_TABLE |
CE_COLUMN_TABLE(<table_name>[,<attributes>]) <attributes> ::=
‘[’ <attrib_name>[{, <attrib_name> }…] ‘]’
|
SELECT [<attributes>] FROM<table_name> |
|
CE_JOIN_VIEW |
CE_JOIN_VIEW(<column_view_name>[,<attributes>]) <attributes> ::=
[<attrib_name>[{, <attrib_name> }…] ]
|
SELECT [<attributes>] FROM <column_view_name>
|
|
|
CE_OLAP_VIEW |
CE_OLAP_VIEW (<olap_view_name>[,<attributes>]) <attributes> ::= <aggregate_exp> [{, <dimension>}…] [{, <aggregate_exp>}…] <aggregate_exp> ::= <aggregate_func>(<aggregate_column> [AS <column_alias>]) <aggregate_func> ::= COUNT | SUM | MIN | MAX Note you must have at least one <aggregation_exp> in the attributes. Supported aggregation
functions are:
|
SELECT [<attributes>] FROM <olap_view_name>
|
|
|
CE_CALC_VIEW |
CE_CALC_VIEW(<calc_view_name>,[<attributes>]) <attributes> ::=
‘[’ <attrib_name>[{, <attrib_name> }…] ‘]’
|
SELECT [<attributes>] FROM <calc_view_name>
|
|
|
Relational operators 关联操作 |
CE_JOIN |
CE_JOIN(<left_table>,<right_table>,<join_attributes>[<projection_list>]) <join_attributes>
::= ‘[‘ <join_attrib>[{, <join_attrib> }…] ‘]‘ Note
|
SELECT [<projection_list>] FROM <left_table>,<right_table> WHERE <join_attributes>
|
|
CE_LEFT_OUTER_JOIN |
CE_LEFT_OUTER_JOIN(<left_table>,<right_table>,<join_attributes>[<projection_list>]) |
SELECT [<projection_list>] FROM <left_table> LEFT OUTER JOIN <right_table> ON <join_attributes> |
|
|
CE_RIGHT_OUTER_JOIN |
CE_RIGHT_OUTER_JOIN(<left_table>,<right_table>,<join_attributes>[<projection_list>]) |
SELECT [<projection_list>] FROM <left_table> RIGHT OUTER JOIN <right_table> ON <join_attributes> |
|
|
CE_PROJECTION |
CE_PROJECTION(<table_variable>,<projection_list>[,<filter>]) <projection_list>
::= [ <attrib_name>[{, <attrib_name> }…] ]
|
SELECT <projection_list> FROM <table_variable> where [<filter>]
ot_book2= SELECT title, price, crcy AS currency FROM :it_b ooks WHERE price > 50; |
|
|
CE_UNION_ALL |
CE_UNION_ALL(<table_variable1>,<table_variable2>)
|
SELECT * FROM <table_variable1> UNION ALL SELECT * FROM <table_variable2>
|
|
|
CE_AGGREGATION |
CE_AGGREGATION(<table_variable>,<aggregate_list>[,<group_columns>])
The result schema is
derived from the list of aggregates(结果集的结构来源于aggregate_list), followed by the group-by attributes. The order of the returned
columns is defined by the order of columns defined in these lists. The
attribute names are:
|
SELECT <aggregate_list> FROM <table_variable>[GROUP BY <group_columns>]
|
|
|
CE_CALC |
CE_CALC(‘<expr>’,<result_type>) |
SQL Function |
|
|
Special operators 特定操作 |
CE_CONVERSION |
CE_CONVERSION(<table_variable>,<conversion_params>,[<rename_clause>]) |
SQL-Function |
|
CE_VERTICAL_UNION |
CE_VERTICAL_UNION(<var_table>, <projection_list> [{,<var_table>,<projection_list>}...]) <var_table> ::=
:<identifier> Description: |
|
|
|
TRACE |
TRACE(<var_input>)
Description:
|
|
Calculation engine plan operators
encapsulate data-transformation functions and can be used in the definition of
a procedure or a table user-defined function. They constitute a no longer
recommended alternative to using SQL statements. Their logic is directly
implemented in the calculation engine, which is the execution environments of
SQLScript.
There are different categories of operators.CE
Function分三种
● Data Source Access operators that bind
a column table or a column view to a table variable.数据访问
● Relational operators that allow a user
to bypass the SQL processor during evaluation
and to directly interact with the calculation engine.关联操作
● Special extensions that implement
functions.特定扩展函数
Syntax:
CE_CALC (‘<expr>‘, <result_type>)
Syntax elements:
<expr> ::= <expression>
Specifies the expression to be evaluated. Expressions are
analyzed using the following grammar:
● b --> b1 (‘or‘ b1)*
● b1 --> b2 (‘and‘ b2)*
● b2 --> ‘not‘ b2 | e ((‘<‘ |
‘>‘ | ‘=‘ | ‘<=‘ | ‘>=‘ | ‘!=‘) e)*
● e --> ‘-‘? e1 (‘+‘ e1 | ‘-‘ e1)*
● e1 --> e2 (‘*‘ e2 | ‘/‘ e2 | ‘%‘
e2)*
● e2 --> e3 (‘**‘ e2)*
● e3 --> ‘-‘ e2 | id (‘(‘ (b (‘,‘
b)*)? ‘)‘)? | const | ‘(‘ b ‘)‘
Where terminals in the grammar are enclosed, for example ‘token‘ (denoted with
id in the grammar), they are like SQL identifiers. An exception to this is that
unquoted identifiers are converted into lower-case. Numeric constants are
basically written in the same way as in the C programming language, and string
constants are enclosed in single quotes, for example, ‘a string‘. Inside
string, single quotes are escaped by another single quote.
An example expression valid in this grammar is: "col1"
< ("col2" + "col3").
For a full list of expression functions, see the following table.
<result_type> ::= DATE | TIME | SECONDDATE | TIMESTAMP |
TINYINT | SMALLINT | INTEGER | BIGINT | SMALLDECIMAL | DECIMAL | REAL | DOUBLE
| VARCHAR | NVARCHAR | ALPHANUM | SHORTTEXT | VARBINARY | BLOB | CLOB | NCLOB |
TEXT
Specifies the result type of the expression as an SQL type
Description:
CE_CALC is used inside other
relational operators. It evaluates an expression and is usually then bound to a
new column. An important use case is evaluating expressions in the CE_PROJECTION operator. The CE_CALC function takes two
arguments:
The following expression functions are supported:
Table 19: Expression Functions
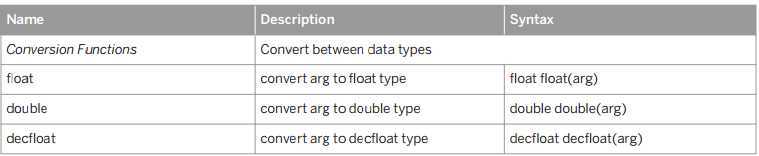
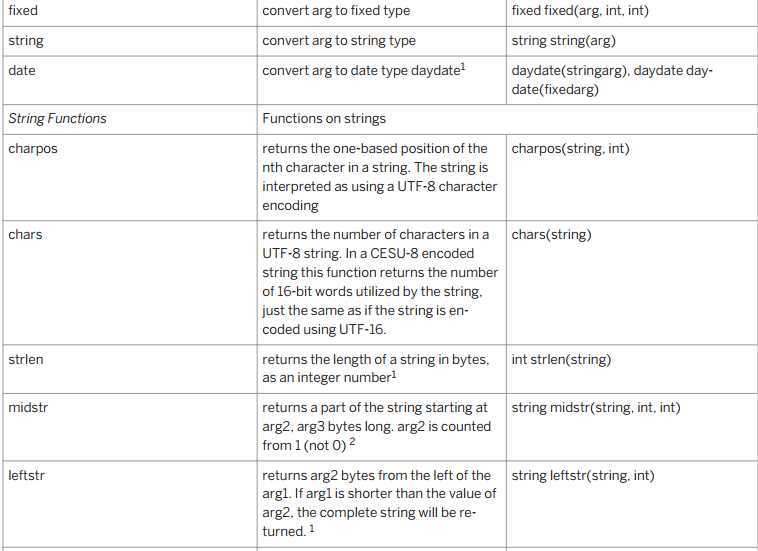
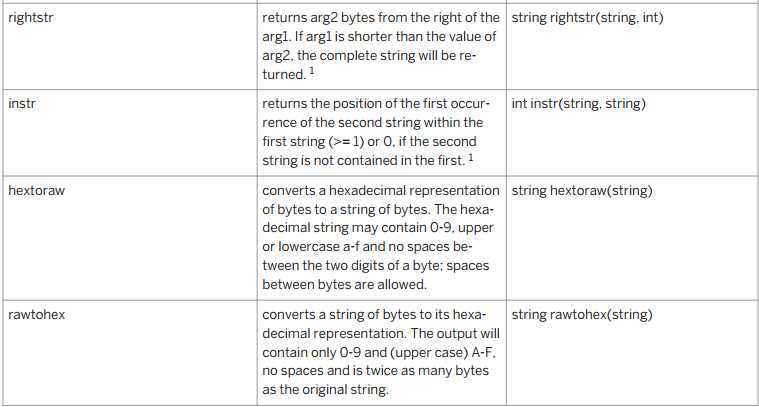
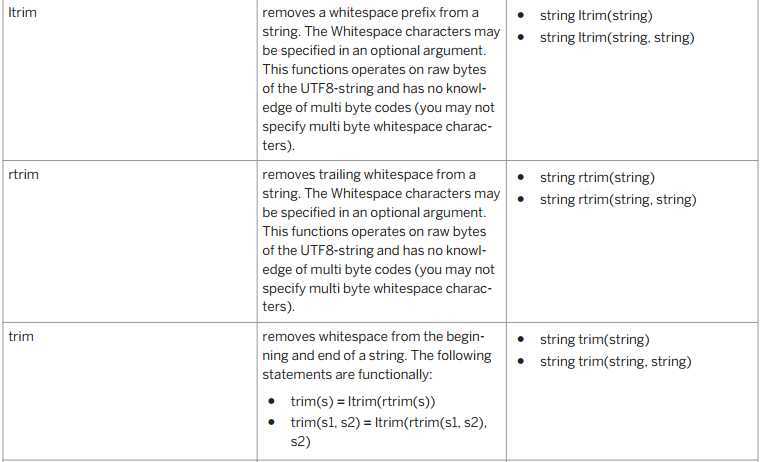

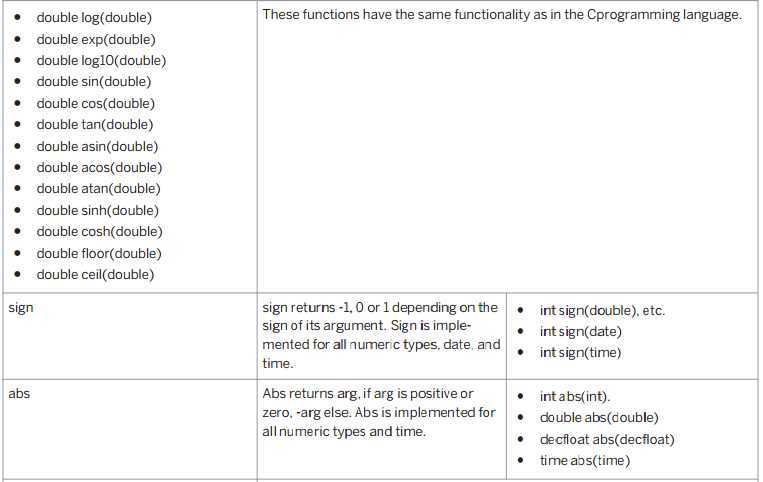
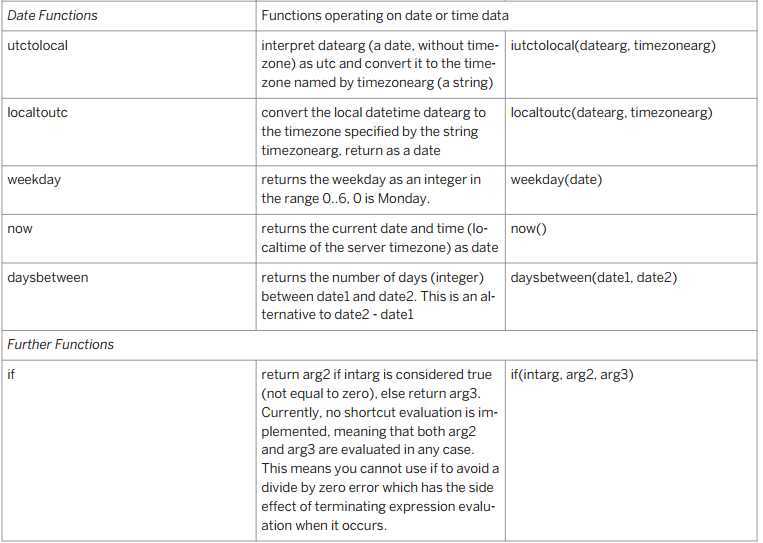

1 Due
to calendar variations with dates earlier that 1582, the use of the date data type is deprecated; youshould use
the daydate data type instead.
Note: date
is based on the proleptic Gregorian calendar. daydate is based on the Gregorian
calendar which is also the calendar used by SAP HANA SQL.
2 These Calculation Engine string
functions operate using single byte characters标注2的函数只能用于单字节字符. To use these functions with multi-byte character strings
please see section: Using String Functions with Multi-byte Character Encoding below.
Note, this limitation限制 does not exist for the SQL functions
of the SAP HANA database which support Unicode encoded strings natively.
Using String Functions with Multi-byte Character Encoding
To allow the use of the string functions of Calculation Engine
with multi-byte character encoding you can use the charpos
and chars (see
table above for syntax of these commands) functions. An example of this usage for
the single byte character function midstr follows below:-
midstr(<input_string>,
charpos(<input_string>, 32), 1)
Syntax:
CE_CONVERSION(<var_table>,
<conversion_params>, [<rename_clause>])
Syntax elements:
<var_table> ::= :<identifier>
Specifies a table variable to be used for the conversion转换.
<conversion_params> ::=
‘[‘<key_val_pair>[{,<key_val_pair>}...]‘]‘
Specifies the parameters for the conversion. The CE_CONVERSION operator is highly configurable
via a list of key-value pairs. For the exact conversion parameters permissible,
see the Conversion parameters table.
<key_val_pair> ::= <key> = <value>
Specify the key and value pair for the
parameter setting.
<key> ::= <identifier>
Specifies the parameter key name.
<value> ::= <string_literal>
Specifies the parameter value.
<rename_clause> ::=
<rename_att>[{,<rename_att>}]
Specifies new names for the result columns.
<rename_att> ::= <convert_att> AS
<new_param_name>
<convert_att> ::= <identifier>
<new_param_name> ::= <identifier>
Specifies the new name for a result column.
Description:
Applies a unit conversion to input table <var_table> and returns the converted
values. Result columns can optionally be renamed. The following syntax depicts
valid combinations. Supported keys with their allowed domain of values are:
Table 20: Conversion parameters
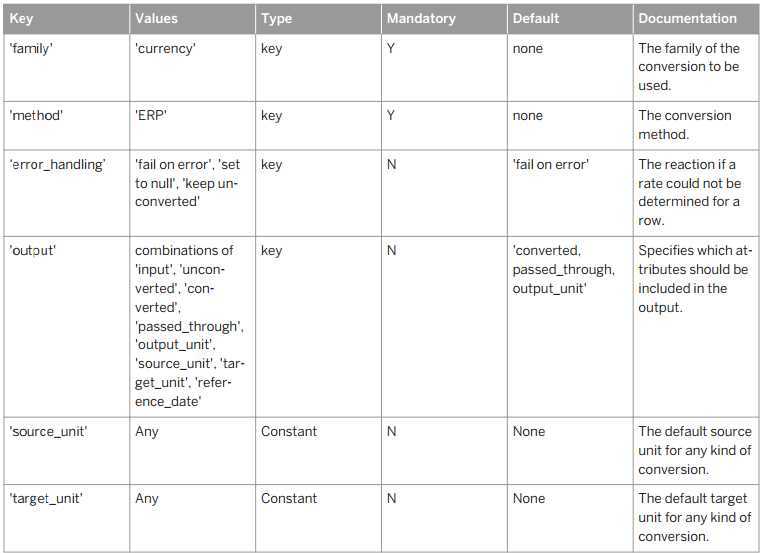
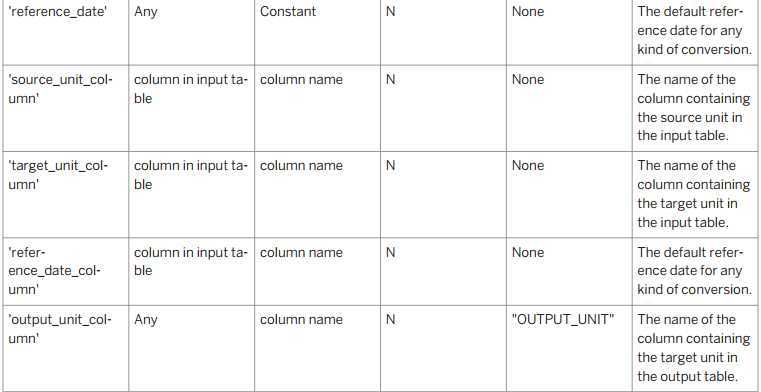
For ERP conversion specifically:
Table 21:
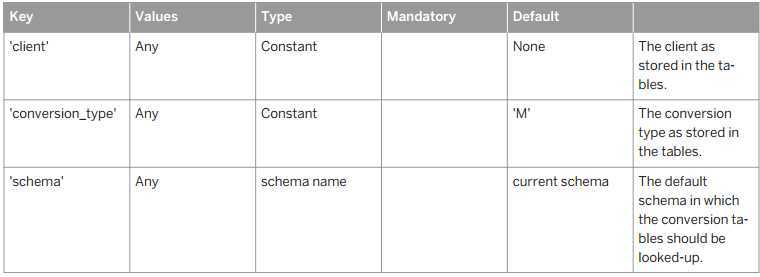
Using CALL DATBASE PROCEDURE
The best way to call
SQLScript from ABAP is to create a procedure proxy which can be natively called
from ABAP by using the built in command CALL DATABASE PROCEDURE.
The SQLScript procedure has to be created normally in the SAP HANA Studio with
the HANA Modeler. After this a procedure proxy can be creating using the ABAP
Development Tools for Eclipse. In the procedure proxy the type mapping between
ABAP and HANA data types can be adjusted. The procedure proxy is transported normally
with the ABAP transport system while the HANA procedure may be transported
within a delivery unit as a TLOGO object.
Calling the procedure in ABAP is very simple. The example below shows calling a procedure with two inputs (one scalar, one table) and one (table) output parameter:
CALL DATABASE PROCEDURE
z_proxy
EXPORTING iv_scalar = lv_scalar
it_table = lt_table
IMPORTING et_table1 = lt_table_res.
Using the connection
clause of the CALL DATABASE PROCEDURE command, it is also possible to call a database procedure using
a secondary database connection. Please consult参考 the ABAP help for detailed instructions of how to use the CALL DATABASE PROCEDURE command and for the exceptions may be raised.
It is also possible to create procedure proxies with an ABAP API
programmatically. Please consult the documentation of the class CL_DBPROC_PROXY_FACTORY for more information on this topic.
Using ADBC(原生SQL接口API)
ABAP 三种操作数据库的方法 OPEN SQL, EXEC SQL, ADBC
OPEN SQL这里就不多说了,可以执行大部分DML语句,但是却不支持DDL,DCL,UNIT,也没办法执行数据内嵌的函数。EXEC SQL 和 ADBC 是所谓的Native SQL,这种方式直接进入指定数据库,不涉及到DBI,这样就没有table buffer。相对EXEC SQL来说,更推荐ADBC的方式执行native sql,这种方式的好处是更加容易追踪错误。
REPORT zrs_native_sqlscript_call.
PARAMETERS:
con_name TYPE dbcon-con_name DEFAULT ‘DEFAULT‘.
TYPES:
BEGIN OF result_t,
key TYPE i,
value TYPE string,
END OF result_t.
DATA:
sqlerr_ref TYPE REF TO cx_sql_exception,
con_ref TYPE REF TO cl_sql_connection,
stmt_ref TYPE REF TO cl_sql_statement,
res_ref TYPE REF TO cl_sql_result_set,
d_ref TYPE REF TO data,
result_tab TYPE TABLE OF result_t,
row_cnt TYPE i.
START-OF-SELECTION.
TRY.
con_ref = cl_sql_connection=>get_connection( con_name ).
stmt_ref = con_ref->create_statement( ).
*************************************
** Setup test and procedure
*************************************
* Create test table
TRY.
stmt_ref->execute_ddl( ‘CREATE TABLE zrs_testproc_tab( key INT PRIMARY KEY, value NVARCHAR(255) )‘ ).
stmt_ref->execute_update( ‘INSERT INTO zrs_testproc_tab VALUES(1, ‘‘test value‘‘ )‘ ).
CATCH cx_sql_exception.
ENDTRY.
* Create test procedure
TRY.
stmt_ref->execute_ddl( ‘DROP PROCEDURE zrs_testproc‘ ).
CATCH cx_sql_exception.
ENDTRY.
TRY.
stmt_ref->execute_ddl( ‘DROP VIEW zrs_testproc_view‘ ).
CATCH cx_sql_exception.
ENDTRY.
stmt_ref->execute_ddl( ‘CREATE PROCEDURE zrs_testproc( OUT t1 zrs_testproc_tab ) ‘
&‘READS SQL DATA WITH RESULT VIEW zrs_testproc_view AS BEGIN t1 = select * from zrs_testproc_tab; end‘ ).
* Create transfer table for output parameter
* this table is used to transfer data for parameter 1 of proc zrs_testproc
* for each procedure a new transfer table has to be created when the procedure is executed via result view, this table is not needed
* If the procedure has more than one table type parameter, a transfer table is needed for each parameter
* Transfer tables for input parameters have to be filled first before the call is executed
TRY.
stmt_ref->execute_ddl( ‘DROP TABLE zrs_testproc_p1‘ ).
stmt_ref->execute_ddl( ‘CREATE GLOBAL TEMPORARY COLUMN TABLE zrs_testproc_p1( key int, value NVARCHAR(255) )‘ ).
CATCH cx_sql_exception.
ENDTRY.
*************************************
** Execution time
*************************************
PERFORM execute_with_transfer_table.
PERFORM execute_with_result_view.
con_ref->close( ).
CATCH cx_sql_exception INTO sqlerr_ref.
PERFORM handle_sql_exception USING sqlerr_ref.
ENDTRY.
FORM execute_with_result_view.
CLEAR result_tab.
* execute procedure call by selecting from the result view
* additional input parameters have to be passed in via the WITH PARAMETERS clause
res_ref = stmt_ref->execute_query( ‘SELECT * FROM zrs_testproc_view‘ ).
* set output table
GET REFERENCE OF result_tab INTO d_ref.
res_ref->set_param_table( d_ref ).
* get the complete result set in the internal table
row_cnt = res_ref->next_package( ).
WRITE: / ‘EXECUTE WITH RESULT VIEW: row count: ‘, row_cnt.
ENDFORM.
FORM execute_with_transfer_table.
CLEAR result_tab.
* clear output table in session
* should be done each time before the procedure is called
stmt_ref->execute_ddl( ‘TRUNCATE TABLE zrs_testproc_p1‘ ).
* execute procedure call
res_ref = stmt_ref->execute_query( ‘CALL zrs_testproc( zrs_testproc_p1 ) WITH OVERVIEW‘ ).
res_ref->close( ).
* read result for output parameter from output transfer table
res_ref = stmt_ref->execute_query( ‘SELECT * FROM zrs_testproc_p1‘ ).
* set output table
GET REFERENCE OF result_tab INTO d_ref.
res_ref->set_param_table( d_ref ).
* get the complete result set in the internal table
row_cnt = res_ref->next_package( ).
WRITE: / ‘EXECUTE WITH TRANSFER TABLE: row count: ‘, row_cnt.
ENDFORM.
FORM handle_sql_exception
USING p_sqlerr_ref TYPE REF TO cx_sql_exception.
FORMAT COLOR COL_NEGATIVE.
IF p_sqlerr_ref->db_error = ‘X‘.
WRITE: / ‘SQL error occured:‘, p_sqlerr_ref->sql_code, "#EC NOTEXT
/ p_sqlerr_ref->sql_message.
ELSE.
WRITE:
/ ‘Error from DBI (details in dev-trace):‘, "#EC NOTEXT
p_sqlerr_ref->internal_error.
ENDIF.
ENDFORM.
package tes;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.CallableStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
publicclass TT {
publicstaticvoid main(String[] args) {
CallableStatement cSt = null;
String sql = "call SqlScriptDocumentation.getSalesBooks(?,?,?,?)";
ResultSet rs = null;
Connection conn = getDBConnection(); // establish connection to database
// using jdbc
try {
cSt = conn.prepareCall(sql);
if (cSt == null) {
System.out.println("error preparing call: " + sql);
return;
}
cSt.setFloat(1, 1.5f);
cSt.setString(2, "‘EUR‘");
cSt.setString(3, "books");
int res = cSt.executeUpdate();
System.out.println("result: " + res);
do {
rs = cSt.getResultSet();
while (rs != null && rs.next()) {
System.out.println("row: " + rs.getString(1) + ", "
+ rs.getDouble(2) + ", " + rs.getString(3));
}
} while (cSt.getMoreResults());
} catch (Exception se) {
se.printStackTrace();
} finally {
if (rs != null)
rs.close();
if (cSt != null)
cSt.close();
}
}
}
该代码片段前面某些实例用到过
CREATETABLE message_box (p_msg VARCHAR(200), tstamp TIMESTAMP);
CREATEPROCEDURE ins_msg_proc (p_msg VARCHAR(200)) LANGUAGE SQLSCRIPT AS
BEGIN
INSERTINTO message_box VALUES (:p_msg, CURRENT_TIMESTAMP);
END;
原文:http://www.cnblogs.com/jiangzhengjun/p/5040531.html