你可以给你的 SQL 语句添加注释来增加可读性和可维护性。 SQL 语句中注释的分隔如下:
l 双连字符“--”。所有在双连字符之后直到行尾的内容都被 SQL 解析器认为是注释。
l “/*”和“*/”。这种类型的注释用来注释多行内容。所有在引号符“/*”和关闭符“*/”之间 的文字都会被 SQL 解析器忽略。
标识符用来表示 SQL 语句中的名字,包括表名、视图名、同义字、列名、索引名、函数名、存储过程名、用户名、角色名等等。有两种类型的标识符:未分隔标识符和分隔标识符(指用空间分开字符串)。
l 未分隔的表名和列名必须以字母开头,不能包含除数字或者下划线以外的符号。
l 分隔标识符用分隔符、双引号关闭,然后标识符可以包含任何字符包括特殊字符。例如,"AB$%CD" 是一个有效的标识符。
l 限制:
o "_SYS_"专门为数据库引擎保留,因此不允许出现在集合对象的名字开头。
o 角色名和用户名必须以未分隔符指定。
o 标识符最大长度为 127 字母。
单引号是用来分隔字符串,使用两个单引号就可以代表单引号本身。
用双引号分隔标识符,使用两个双引号可以代表双引号本身。
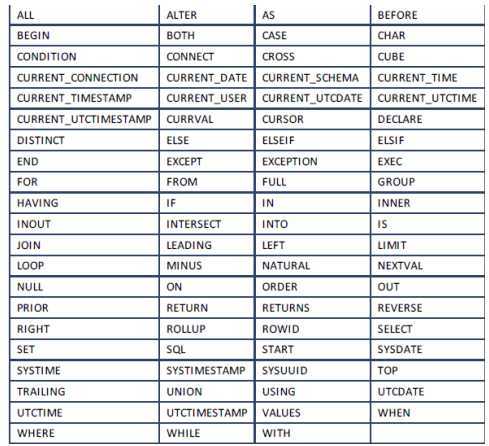
保留字对于 SAP HANA 数据库的 SQL 解析器有着特殊含义,不能成为用户自定义的名字。保留字不能在 SQL 语句中使用为集合对象名。如果有必要,你可以使用双引号限定表或列名绕过这个限制。
下表列出了所有现在和未来 SAP HANA 数据库的保留字:
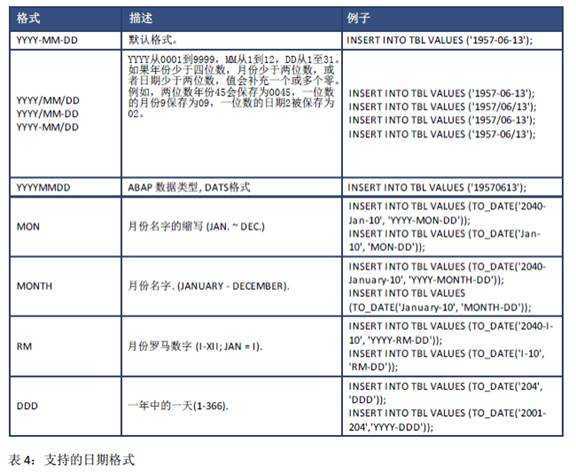
DATE 数据类型由年、月、日信息组成,表示一个日期值。 DATA 类型的默认格式为‘YYYY-MM-DD’。 YYYY 表示年, MM 表示月而 DD 表示日。时间值的范围从 0001-01-01 至 9999-12-31。
select to_date(‘365‘,‘DDD‘) from dummy;
![]()
select to_date(‘2015/365‘,‘YYYY/ddd‘) from dummy;
![]()
select to_date(‘2015-january‘,‘YYYY-month‘) from dummy;
![]()
select to_date(‘2015-February/28‘,‘yyyy-moNth/dd‘) from dummy;
![]()
select to_date(‘2015-Jan/31‘,‘yyyy-mon/dd‘) from dummy;
![]()
select to_date(‘2015/2-1‘,‘yyyy/mM-dd‘) from dummy;
![]()
select to_date(‘2015/02-01‘,‘yyyy/mM-dd‘) from dummy;
![]()
select to_date(‘2015+02=01‘,‘yyyy+mM=dd‘) from dummy;
![]()
select to_date(‘20150201‘,‘yyyymmdd‘) from dummy;
![]()
TIME 数据类型由小时、分钟、秒信息组成,表示一个时间值。 TIME 类型的默认格式为‘HH24:MI:SS’。 HH24 表示从 0 至 24 的小时数, MI 代表 0 至 59 的分钟值而 SS 表示 0 至 59的秒。

select to_time(‘1:1:1 PM‘,‘HH:MI:SS PM‘) from dummy;
![]()
select to_time(‘1:1:1‘,‘HH:MI:SS‘) from dummy;
![]()
select to_time(‘1:1:1‘,‘HH24:MI:SS‘) from dummy;
![]()
SECONDDATE 数据类型由年、月、日、小时、分钟和秒来表示一个日期和时间值。
SECONDDATE 类型的默认格式为‘YYYY-MM-DD HH24:MI:SS’。 YYYY 代表年, MM 代表月份,DD 代表日, HH24 表示小时, MI 表示分钟, SS 表示秒。日期值的范围从 0001-01-01 00:00:01 至 9999-12-31 24:00:00。
TIMESTAMP 数据类型由日期和时间信息组成时戳。默认格式为‘YYYY-MM-DD HH24:MI:SS.FF7’。 FFn 代表含有小数的秒,其中 n 表示小数部分的数字位数。时间戳的范围从 0001-01-01 00:00:00.0000000 至 9999-12-31 23:59:59.9999999。

select to_timestamp(‘2015/1/2 1:1:1‘,‘YYYY/MM/DD HH:MI:SS‘) from dummy;
![]()
select to_timestamp(‘2015/1/2 1:1:1.999‘,‘YYYY/MM/DD HH:MI:SS.FF3‘) from dummy;
![]()
select to_timestamp(‘2015/1/2 1:1:1.9999999‘,‘YYYY/MM/DD HH:MI:SS.FF7‘) from dummy;
![]()
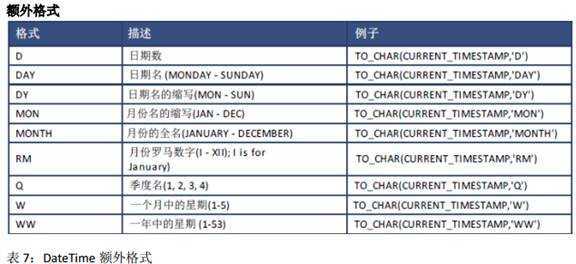
selectcurrent_timestampfrom dummy;--2015-6-12 16:50:26.349
select to_char(current_timestamp,‘D‘) from dummy;--5 注:这个应该是星期几
select to_char(current_timestamp,‘DD‘) from dummy;--12
select to_char(current_timestamp,‘DDD‘) from dummy;--163
select to_char(current_timestamp,‘Day‘) from dummy;--Friday
select to_char(current_timestamp,‘Dy‘) from dummy;--Fri
select to_char(current_timestamp,‘mon‘) from dummy;--jun
select to_char(current_timestamp,‘month‘) from dummy;--june
select to_char(current_timestamp,‘rm‘) from dummy;--vi
select to_char(current_timestamp,‘q‘) from dummy;--2
select to_char(current_timestamp,‘w‘) from dummy;--2
select to_char(current_timestamp,‘ww‘) from dummy;--24
select to_char(current_timestamp,‘FF7‘) from dummy;--1260000
select to_char(current_timestamp,‘YY‘) from dummy;--15
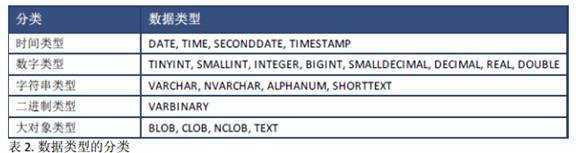
TINYINT 数据类型存储一个 8 位(1个字节)无符号整数。 TINYINT 的最小值是 0,最大值是 255。
SMALLINT 数据类型存储一个 16 (2个字节)位无符号整数。 SMALLINT 的最小值为-32,768 ,最大值为32, 767。
INTEGER 数据类型存储一个 32 (4个字节)位有符号整数。 INTEGER 的最小值为-2,147,483,648 ,最大值为 2,147,483,647。
BIGINT 数据类型存储一个 64 (8个字节)位有符号整数。 INTEGER 的最小值为-9,223,372,036,854,775,808,最大值为 9, 223,372,036,854,775,807。
DECIMAL (p, s) 数据类型指定了一个精度为 p 小数位数为 s 的定点小数。精度是有效位数的总数,范围从 1 至 34。
小数位数是从小数点到最小有效数字的数字个数,范围从-6,111 到 6,176,这表示位数指定了十进制小数的指数范围从 10-6111 至 106176。如果没有指定小数位数,则默认值为 0。
当数字的有效数字在小数点的右侧(后面)时,小数位数为正;有效数字在小数点左侧(前面)时,小数位数为负。
例子:
0.0000001234 (1234 x 10-10) 精度为 4,小数位数 10。
1.0000001234(10000001234 x 10-10) 精度为 11,小数位数为 10。
1234000000 (1234x106) 精度为 4,小数位数为-6。
当未指定精度和小数位数, DECIMAL 成为浮点小数。这种情况下,精度和小数位数可以在上文描述的范围内不同,根据存储的数值, 1-34 的精度和 6111-6176 的小数位数。
SMALLDECIMAL 是一个浮点十进制数。精度和小数位数可以在范围有所不同,根据存储的数值, 1-16 的精度以及-369-368的小数位数。 SMALLDECIMAL 只支持列式存储。
DECIMAL 和 SMALLDECIMAL 都是浮点十进制数。举例来说,一个十进制列可以存储 3.14,3.1415, 3.141592 同时保持它们的精度。
DECIMAL(p, s) 是 SQL 对于定点十进制数的标准标记。例如, 3.14, 3.1415,3.141592 存储在 decimal(5, 4)列中为 3.1400, 3.1415, 3.1416,各自保持其精度( 5)和小数位数( 4)。
REAL 数据类型定义一个 32 位(4个字节)单精度浮点数。
DOUBLE 数据类型定义一个 64 位(8个字节)的双精度浮点数,最小值为-1.79769 x 10308,最大值为
1.79769x10308, DOUBLE 最小的正数为 2.2207x10-308,最大的负数为-2.2207x10-308。
FLOAT 数据类型定义一个 32 位或 64 位的实数, n 指定有效数字的个数,范围可以从 1 至53。
当你使用 FLOAT( n )数据类型时,如果 n 比 25 小,其会变成 32 位的实数类型;如果 n 大于等于 25,则会成为 64 的 DOUBLE 数据类型。如果 n 没有声明,默认变成 64 位的double 数据类型。
字符类型用来存储包含字符串的值。 VARCHAR类型包含 ASCII字符串,而 NVARCHAR用来存储 Unicode字符串。
VARCHAR (n) 数据类型定义了一个可变长度的 ASCII 字符串, n 表示最大长度,是一个 1 至5000的整数值。
NVARCHAR (n) 数据类型定义了一个可变长度的 Unicode 字符串, n 表示最大长度,是一个1 至 5000的整数值。
ALPHANUM (n) 数据类型定义了一个可变长度的包含字母数字的字符串, n 表示最大长度,是一个 1 至 127的整数值。
SHORTTEXT (n) 数据类型定义了一个可变长度的字符串,支持文本搜索和字符搜索功能。
这不是一个标准的 SQL 类型。选择一列 SHORTTEXT (n) 列会生成一个 NVARCHAR (n)类型的列。
二进制类型用来存储二进制数据的字节。
VARBINARY 数据类型用来存储指定最大长度的二进制数据,以字节为单位, n 代表最大长度,是一个 1 至 5000的整数。
LOB(大对象)数据类型, CLOB, NCLOB 和 BLOB,用来存储大量的数据例如文本文件和图像。 一个 LOB 的最大大小为 2GB。
BLOB 数据类型用来存储大二进制数据。
CLOB 数据类型用来存储大 ASCII 字符数据。
NCLOB 数据类型用来存储大 Unicode 字符对象。
TEXT 数据类型指定支持文本搜索功能,这不是一个独立的 SQL 类型。 选择一列 TEXT 列会
生成一个 NCLOB 类型的列。
LOB 类型用于存储和检索大量的数据。 LOB 类型支持以下操作:
lLength(n)以字节形式返回 LOB 的长度。
lLIKE 可以用来搜索 LOB 列。
LOB 类型有如下限制:
lLOB 列不能出现在 ORDER BY 或 GROUP BY 子句中。
lLOB 列不能出现在 FROM 子句作为联接谓词。
l不能作为谓词出现在 WHERE 子句中,除了 LIKE, CONTAINS, =或<>。
lLOB 列不能出现在 SELECT 子句作为一个聚合函数的参数。
lLOB 列不能出现在 SELECT DISTINCT 语句中。
lLOB 列不能用于集合操作,除了 EXCEPT, UNION ALL 是个例外。
lLOB 列不能作为主键。
lLOB 列不能使用 CREATE INDEX 语句。
lLOB 列不能使用统计信息更新语句。
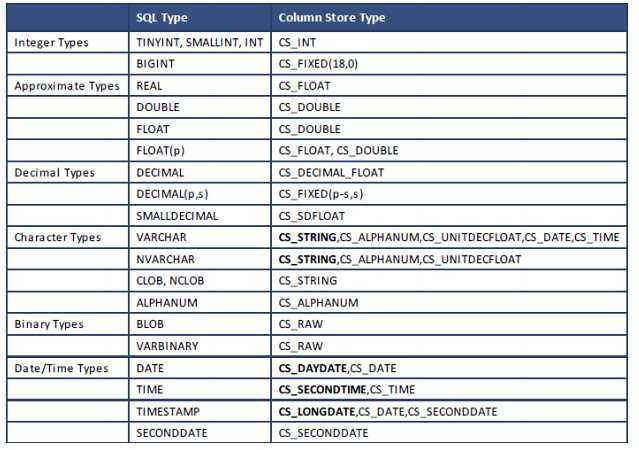
本节描述 SAP HANA 数据库中允许的类型转换。
表达式结果的类型,例如一个字段索引,一个字段函数或者文字可以使用如下函数进行转换: CAST, TO_ALPHANUM, TO_BIGINT, TO_VARBINARY,TO_BLOB, TO_CLOB, TO_DATE, TO_DATS, TO_DECIMAL, TO_DOUBLE, TO_INTEGER, TO_INT,TO_NCLOB, TO_NVARCHAR, TO_REAL, TO_SECONDDATE, TO_SMALLINT, TO_TINYINT, TO_TIME,TO_TIMESTAMP, TO_VARCHAR。
当给定的一系列运算符/参数类型不符合其所期望的类型, SAP HANA 数据库就会执行类型转换。这种转换仅仅发生在相关的转换可供使用,并且使得运算符/参数类型可执行。
举例来说, BIGINT 和 VARCHAR 之间的比较是通过把 VARCHAR 隐式转换成 BIGINT 进行的。
显式转换可以全部用于隐式转换,除了 TIME 和 TIMESTAMP 数据类型。 TIME 和TIMESTAMP 可以使用 TO_TIME(TIMESTAMP)以及 TO_TIMESTAMP(TIME)相互转换。
例子

在下表中:
? 方框中“OK”表示允许的数据类型转换,没有任何检查。
? 方框中”CHK”表示数据类型转换只有在数据是有效的目标类型时才执行。
? 方框中”-”表示不允许该数据类型转换。
如下显示的规则同时适用于隐式和显示转换,除了 TIME 至 TIMESTAMP 的转换。 TIME 类型只能通过显示转换 TO_TIMESTAMP 或者 CAST 函数执行。
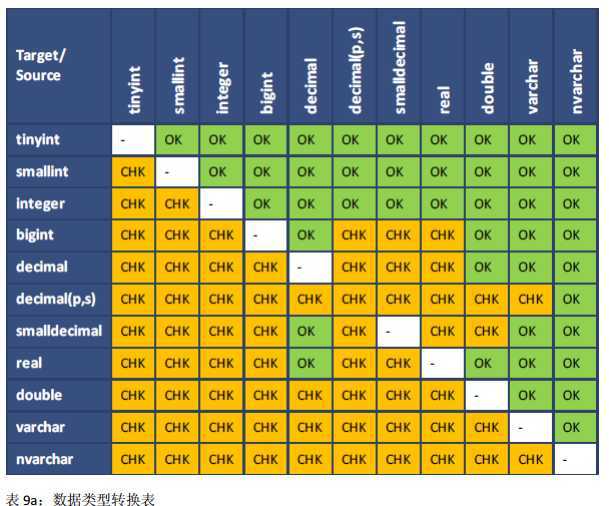
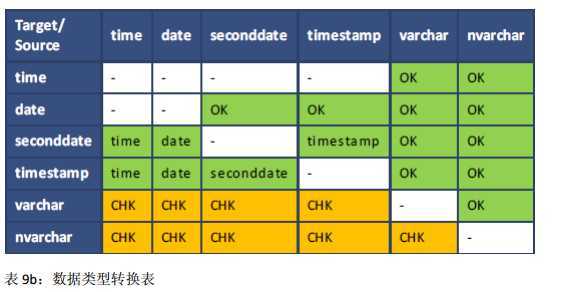
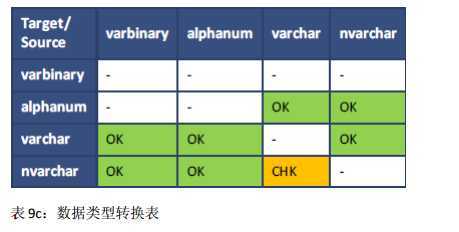
本节介绍 SAP HANA 数据库实施的数据类型的优先级。数据类型优先级指定较低优先级的类型转换为较高优先级的类型。
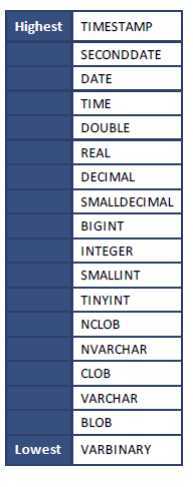
常量是表示一个特定的固定数值的符号。
字符串常量括在单引号中。
o ‘Brian‘
o ‘100‘
Unicode 字符串的格式与字符串相似,但前面有一个 N 标识符( N 代表 SQL-92 标准中的国际语言)。 N 字母前缀必须是大写。
o N‘abc‘
SELECT‘Brian‘"character string 1", ‘100‘"character string 2", N‘abc‘"unicode string"FROM DUMMY;
![]()
数字常量用没有括在单引号中的数字字符串表示。数字可能包含小数点或者科学计数。
o 123
o 123.4
o 1.234e2
十六进制数字常量是十六进制数的字符串,含有前缀 0x。
o 0x0abc
SELECT 123 "integer", 123.4 "decimal1", 1.234e2 "decimal2", 0x0abc "hexadecimal"FROM DUMMY;
![]()
二进制字符串有前缀 X,是一个括在单引号中的十六进制数字字符串。
o X‘00abcd‘
o x‘dcba00‘
SELECT X‘00abcd‘"binary string 1", x‘dcba00‘"binary string 2"FROM DUMMY;
![]()
日期、时间、时间戳各自有如下前缀:
o date‘2010-01-01‘
o time‘11:00:00.001‘
o timestamp‘2011-12-31 23:59:59‘
SELECT date‘2010-01-01‘ "date", time‘11:00:00.001‘ "time", timestamp‘2011-12-31 23:59:59‘ "timestamp" FROM DUMMY;
SELECTdate‘2010-01-01‘"date", time‘11:00:00.001‘"time", timestamp‘2011-12-31 23:59:59‘"timestamp"FROM DUMMY;
![]()
谓词由组合的一个或多个表达式,或者逻辑运算符指定,并返回以下逻辑 /真值中的一个:
TRUE、 FALSE、或者 UNKNOW。
两个值使用比较谓词进行比较,并返回 TRUE, FALSE 或 UNKNOW。
语法:
<comparison_predicate> ::=<expression> { = | != | <> | > | < | >= | <= } [ ANY | SOME| ALL ] { <expression_list> | <subquery> }
<expression_list> ::= <expression>, ...
表达式可以是简单的表达式如字符、日期或者数字,也可以是标量(只有一条结果)子查询,这种子查询的SELECT从句中只有一个表字段或者是一个统计列
如果子查询的结果只有一条数据时,可以省略[ALL|ANY|SOME]选项
如果子查询返回的是多条,则可需要带上[ALL|ANY|SOME]选项
² ? ALL:如果子查询返回的所有行都满足比较条件时,才为真
² ? ANY|SOME:如果子查询返回的所有行中只要有一条满足比较条件时,就会为真
² ? =等号与ANY|SOME一起使用时,与IN操作符具有一样的效果
值将在给定范围中进行比较。
语法:
<range_predicate> ::= <expression1> [NOT] BETWEEN <expression2> AND <expression3>
BETWEEN …AND … - 当指定了范围谓词时,如果 expression1 在 expression2 和 expression3 指定的范围内时,结果返回真;如果 expression2 比 expression3 小,则只返回真。
一个值与一组指定的值比较。如果 expression1 的值在 expression_list(或子查询)中,结果返回真。
语法:
<in_predicate> ::= <expression> [NOT] IN { <expression_list> | <subquery> }
... WHERE CITY IN (‘BERLIN‘, ‘NEW YORK‘, ‘LONDON‘).
如果CITY为IN后面列表中的任何一个时返回true
IN后面也可以根子查询:
SELECT SINGLE city latitude longitude
INTO (city, lati, longi)
FROM sgeocity
WHERE city IN ( SELECT cityfrom FROM spfli
WHERE carrid = carr_id
AND connid = conn_id ).
如果子查询返回非空结果集,结果为真;返回空结果集,结果则为假。
这类子查询没有返回值,也不要求SELECT从句中只有一个选择列,选择列可以任意个数,WHERE or HAVING从句来根据该子查询的是否查询到数据来决定外层主查询语句来选择相应数据
DATA: name_tab TYPE TABLE OF scarr-carrname,
name LIKE LINE OF name_tab.
SELECT carrname INTO TABLE name_tab FROM scarr
WHERE EXISTS ( SELECT * FROM spfli
WHERE carrid = scarr~carrid
AND cityfrom = ‘NEW YORK‘ ).
LOOP AT name_tab INTO name.
WRITE: / name.
ENDLOOP.
此子查询又为相关子查询:
如果某个子查的WHERE条件中引用了外层查询语句的列,则称此子查询为相关子查询。相关子查询对外层查询结果集中的每条记录都会执行一次,所以尽量少用相关子查询
Like 用来比较字符串, Expression1 与包含在 expression2 中的模式比较。通配符( %)和( _)可以用在比较字符串 expression2 中。
“_”用于替代单个字符,“%”用于替代任意字符串,包括空字符串。
可以使用ESCAPE选项指定一个忽略符号h,如果通配符“_”、“%”前面有符号<h>,那么通配符失去了它在模式中的功能,而指字符本身了:
... WHERE FUNCNAME LIKE‘EDIT#_%‘ESCAPE‘#‘;
以“EDIT_”开头的字符串
当指定了谓词 IS NULL,值可以与 NULL 比较。如果表达式值为 NULL, 则 IS NULL 返回值为真;如果指定了谓词 IS NOT NULL,值不为 NULL 时返回值为真。
语法:
null_predicate> ::= <expression> IS [NOT] NULL
CONTAINS 谓词用来搜索子查询中文本匹配的字符串。
语法:
<contains_function> ::= CONTAINS ‘(‘ <contains_columns> ‘,‘ <search_string>‘)‘| CONTAINS ‘(‘ <contains_columns> ‘,‘ <search_string> ‘,‘ <search_specifier> ‘)‘
<contains_columns> ::= ‘*‘ | <column_name> | ‘(‘ <columnlist> ‘)‘
<search_string> ::= <string_const>
<search_specifier> ::= <search_type> <opt_search_specifier2_list>| <search_specifier2_list>
<opt_search_specifier2_list> ::= empty| <search_specifier2_list>
<search_type> ::= <exact_search> | <fuzzy_search> | <linguistic_search>
<search_specifier2_list> ::= <search_specifier2>| <search_specifier2_list> ‘,‘ <search_specifier2>
<search_specifier2> := <weights> | <language>
<exact_search> ::= EXACT
<fuzzy_search> ::= FUZZY| FUZZY ‘(‘ <float_const> ‘)‘ | FUZZY ‘(‘ <float_const> ‘,‘ <additional_params> ‘)‘
<linguistic_search> ::= LINGUISTIC
<weights> ::= WEIGHT ‘(‘ <float_const_list> ‘)‘
<language> :: LANGUAGE ‘(‘ <string_const> ‘)‘
<additional_params> ::= <string_const>
search_string:使用自由式字符串搜索格式(例如, Peter "Palo Alto"或 Berlin -"SAP LABS")。
search_specifier:如果没有指定 search_specifier, EXACT 为默认值。
EXACT:对于那些在 search_attributes 中精确匹配 searchterms 的记录, EXACT 返回真。
FUZZY:对于那些在 search_attributes 相似匹配 searchterms 的记录, FUZZY 返回真(例如,以某种程度忽略拼写错误)。
Float_const:如果省略 float_const,则默认值为 0.8。可以通过定义列式存储联接视图支持的参数FUZZINESSTHRESHOLD 来覆盖默认值。
WEIGHT:如果定义了 weights 列表,则必须与<contains_columns>中的列数量一样。
LANGUAGE:LANGUAGE 在搜索字符串的预处理中使用,并且作为搜索前的过滤。只返回匹配搜索字符串的文档和定义的语言。
LINGUISTIC:对于那些在 searchattribute 中出现的 searchterms 字符变量, LINGUISTIC 返回真。
限制:如果在 where 条件中定义了多个 CONTAINS,那么只有其中的一个由<contains_columns>列表中的不止一列组成。
CONTAINS 只对列式存储表适用(简单表和联接视图)。
例子:
精确搜索:
select * from T where contains(column1, ‘dog OR cat‘) -- EXACT is implicit
select * from T where contains(column1, ‘dog OR cat‘, EXACT)
select * from T where contains(column1, ‘"cats and dogs"‘) -- phrase search
模糊搜索:
select * from T where contains(column1, ‘catz‘, FUZZY(0.8))
语言搜索:
select * from T where contains(column1, ‘catz‘, LINGUISTIC)
自由式搜索:自由式搜索是对于多列的搜索。
select * from T where CONTAINS( (column1,column2,column3), ‘cats OR dogz‘, FUZZY(0.7))
select * from T where CONTAINS( (column1,column2,column3), ‘cats OR dogz‘, FUZZY(0.7))
你可以在表达式中使用操作符进行算术运算。操作符可以用来计算、比较值或者赋值。
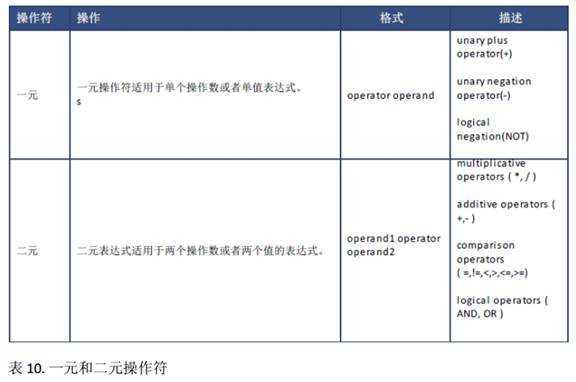
一个表达式可以使用多个操作符。如果操作符大于一个,则 SAP HANA 数据库会根据操作符优先级评估它们。你可以通过使用括号改变顺序,因为在括号内的表达式会第一个评估。
如果没有使用括号,则操作符优先级将根据下表。请注意, SAP HANA 数据库对于优先级相同的操作符将从左至右评估操作符。
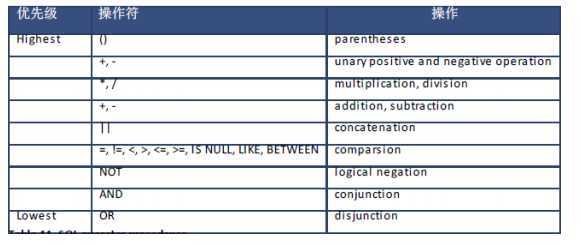
你可以使用算术操作符来执行数学运算,如加法、减法、乘法和除法,以及负数。
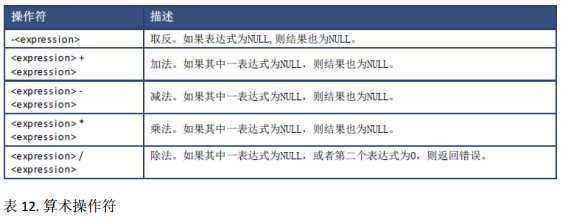

对于 VARCHAR 或者 NVARCHAR 类型字符串,前导或者后置空格将保留。如果其中一字符串类型为 NVARCHAR,则结果也为 NVARCHAR 并且限制在 5000 个字母, VARCHAR 联接的最大长度也限制在 5000 个字母。
语法:
<comparison_operation> ::= <expression1> <comparison_operator> <expression2>
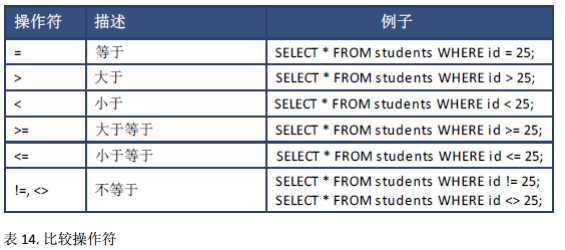
搜索条件可以使用 AND 或者 OR 操作符结合,你也可以使用 NOT 操作符否定条件。

对两个或更多个查询的结果执行合并操作

UNION:并集,去重
UNION ALL:并集,包括重复
INTERSECT:交集
EXCEPT:差集
表达式是可以用来计算并返回值的子句。
语法:
<expression>
::=<case_expression>
| <function_expression>
| <aggregate_expression>
| (<expression> )
| ( <subquery> )
| - <expression>
| <expression> <operator> <expression>
| <variable_name>
| <constant>
| [<correlation_name>.]<column_name>
Case 表达式允许用户使用 IF ... THEN ... ELSE逻辑,而不用在 SQL 语句中调用存储过程。
语法:
<case_expression> ::=
CASE <expression>
WHEN <expression> THEN <expression>, ...
[ ELSE <expression>]
{ END | END CASE }
如果位于 CASE 语句后面的表达式和 WHEN 后面的表达式相等,则 THEN 之后的表达式将作为返回值;否则返回 ELSE 语句之后的表达式,如果存在的话。
SQL 内置的函数可以作为表达式使用。
语法:
<function_expression> ::= <function_name> ( <expression>, ... )
Aggregate 表达式利用 aggregate 函数计算同一列中多行值。
语法:
<aggregate_expression> ::= COUNT(*) | <agg_name> ( [ ALL | DISTINCT ] <expression>)
<agg_name> ::= COUNT | MIN | MAX | SUM | AVG | STDDEV | VAR
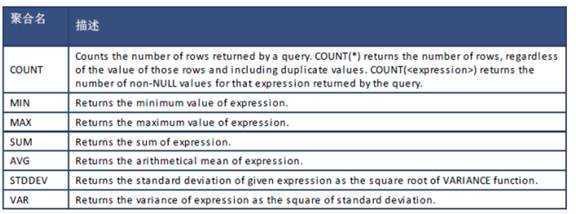
子查询是在括号中的 SELECT 语句。 SELECT 语句可以包含一个,有且仅有一个选择项。当作为表达式使用时,标量(只有一条结果)子查询允许返回零个或一个值。
语法:
<scalar_subquery_expression> ::= (<subquery>)
在最高级别的 SELECT 中的 SELECT 列表,或者 UPDATE 语句中的 SET 条件中,你可以在任何能使用列名的地方使用标量子查询。不过, scalar_subquery 不可以在 GROUP BY 条件中使用。
例子:
以下语句返回每个部门中的员工数,根据部门名字分组:
SELECT DepartmentName, COUNT(*), ‘out of‘,(SELECTCOUNT(*) FROM Employees)
FROM Departments AS D, Employees AS E WHERE D.DepartmentID = E.DepartmentID
GROUPBY DepartmentName;
数据类型转换函数用来把参数从一个数据类型转换为另一个数据类型,或者测试转换是否可行。
语法:
CAST (expression AS data_type)
语法元素:
Expression – 被转换的表达式。
Data type – 目标数据类型。 TINYINT | SMALLINT |INTEGER | BIGINT | DECIMAL | SMALLDECIMAL | REAL | DOUBLE | ALPHANUM | VARCHAR |NVARCHAR | DAYDATE | DATE | TIME | SECONDDATE | TIMESTAMP。
例子:
SELECTCAST (7 ASVARCHAR) "cast"FROM DUMMY;--7
语法:
TO_ALPHANUM (value)
描述:
将给定的 value 转换为 ALPHANUM 数据类型。
例子:
SELECT TO_ALPHANUM (‘10‘) "to alphanum"FROM DUMMY;--10
语法:
TO_BIGINT (value)
描述:
将 value 转换为 BIGINT 类型。
例子:
SELECT TO_BIGINT (‘10‘) "to bigint"FROM DUMMY;--10
语法:
TO_BINARY (value)
描述:
将 value 转换为 BINARY 类型。
例子:
SELECT TO_BINARY (‘abc‘) "to binary"FROM DUMMY;--616263 显示时却是以十六进制显示,而不是二进制?
语法:
TO_BLOB (value)
描述:
将 value 转换为 BLOB 类型。参数值必须是二进制字符串。
例子:
SELECT TO_BLOB (TO_BINARY(‘abcde‘)) "to blob"FROM DUMMY;--abcde
语法:
TO_CHAR (value [, format])
描述:
将 value 转换为 CHAR 类型。如果省略 format 关键字,转换将会使用 Date Formats 中说明的日期格式模型。
例子:
SELECT TO_CHAR (TO_DATE(‘2009-12-31‘), ‘YYYY/MM/DD‘) "to char"FROM DUMMY;--2009/12/31
SELECT TO_CHAR (TO_DATE(‘2009-12-31‘)) "to char"FROM DUMMY;--2009-12-31
语法:
TO_CLOB (value)
描述:
将 value 转换为 CLOB 类型。
例子:
SELECT TO_CLOB (‘TO_CLOB converts the value to a CLOB data type‘) "to clob"FROM DUMMY;--TO_CLOB converts the value to a CLOB data type
语法:
TO_DATE (d [, format])
描述:
将日期字符串 d 转换为 DATE 数据类型。如果省略 format 关键字,转换将会使用 Date Formats 中说明的日期格式模型。
例子:
SELECT TO_DATE(‘2010-01-12‘, ‘YYYY-MM-DD‘) "to date"FROM DUMMY;--2010-1-12
语法:
TO_DATS (d)
描述:
将字符串 d 转换为 ABAP 日期字符串,格式为”YYYYMMDD”。
例子:
SELECT TO_DATS (‘2010-01-12‘) "abap date"FROM DUMMY;--20100112
语法:
TO_DECIMAL (value [, precision, scale])
描述:
将 value 转换为 DECIMAL 类型。
精度是有效数字的总数,范围为 1 至 34。小数位数是从小数点到最小有效数字的数字个数,范围从-6,111 到 6,176,这表示位数指定了十进制小数的指数范围从 10-6111 至 106176。如果没有指定小数位数,则默认值为 0。
当数字的有效数字在小数点的右侧时,小数位数为正;有效数字在小数点左侧时,小数位数为负。
当未指定精度和小数位数, DECIMAL 成为浮点小数。这种情况下,精度和小数位数可以在上文描述的范围内不同,根据存储的数值,精度为 1-34 以及小数位数为 6111-6176。
例子:
SELECTTO_DECIMAL(7654321.888888, 10, 3) "to decimal"FROM DUMMY--7,654,321.888
语法:
TO_DOUBLE (value)
描述:
将 value 转换为 DOUBLE(双精度)数据类型。
例子:
SELECT 3*TO_DOUBLE (‘15.12‘) "to double"FROM DUMMY;--45.36
语法:
TO_INT (value)
描述:
将 value 转换为 INTEGER 类型。
例子:
SELECT TO_INT(‘10‘) "to int"FROM DUMMY;--10
语法:
TO_INTEGER (value)
描述:
将 value 转换为 INTEGER 类型。
例子:
SELECT TO_INTEGER (‘10‘) "to int"FROM DUMMY;--10
语法:
TO_NCHAR (value [, format])
描述:
将 value 转换为 NCHAR Unicode 字符类型。如果省略 format 关键字,转换将会使用 Date Formats中说明的日期格式模型。
例子:
SELECT TO_NCHAR (TO_DATE(‘2009-12-31‘), ‘YYYY/MM/DD‘) "to nchar"FROM DUMMY;--2009/12/31
语法:
TO_NCLOB (value)
描述:
将 value 转换为 NCLOB 数据类型。
例子:
SELECT TO_NCLOB (‘TO_NCLOB converts the value to a NCLOB data type‘) "to nclob"FROM DUMMY;--TO_NCLOB converts the value to a NCLOB data type
语法:
TO_NVARCHAR (value [,format])
描述:
将 value 转换为 NVARCHAR Unicode 字符类型。如果省略 format 关键字,转换将会使用 DateFormats 中说明的日期格式模型。
例子:
SELECT TO_NVARCHAR(TO_DATE(‘2009/12/31‘), ‘YY-MM-DD‘) "to nchar"FROM DUMMY;--09-12-31
语法:
TO_REAL (value)
描述:
将 value 转换为实数(单精度)数据类型。
例子:
SELECT 3*TO_REAL (‘15.12‘) "to real"FROM DUMMY;--45.36000061035156
语法:
TO_SECONDDATE (d [, format])
描述:
将 value 转换为 SECONDDATE 类型。如果省略 format 关键字,转换将会使用 Date Formats 中说明的日期格式模型。
例子:
SELECT TO_SECONDDATE (‘2010-01-11 13:30:00‘, ‘YYYY-MM-DD HH24:MI:SS‘) "to seconddate"FROM DUMMY;--2010-1-11 13:30:00.0
语法:
TO_SMALLDECIMAL (value)
描述:
将 value 转换为 SMALLDECIMAL 类型。
例子:
SELECT TO_SMALLDECIMAL(7654321.89) "to smalldecimal"FROM DUMMY;--7,654,321.89
语法:
TO_SMALLINT (value)
描述:
将 value 转换为 SMALLINT 类型。
例子:
SELECT TO_SMALLINT (‘10‘) "to smallint"FROM DUMMY;--10
语法:
TO_TIME (t [, format])
描述:
将时间字符串 t 转换为 TIME 类型。如果省略 format 关键字,转换将会使用 Date Formats 中说明的日期格式模型。
例子:
SELECT TO_TIME (‘08:30 AM‘, ‘HH:MI AM‘) "to time"FROM DUMMY;--8:30:00
语法:
TO_TIMESTAMP (d [, format])
描述:
将时间字符串 t 转换为 TIMESTAMP 类型。如果省略 format 关键字,转换将会使用 Date Formats中说明的日期格式模型。
例子:
SELECT TO_TIMESTAMP (‘2010-01-11 13:30:00‘, ‘YYYY-MM-DD HH24:MI:SS‘) "to timestamp"FROM DUMMY;--2010-1-11 13:30:00.0
语法:
TO_TINYINT (value)
描述:
将 value 转换为 TINYINT 类型。
例子:
SELECT TO_TINYINT (‘10‘) "to tinyint"FROM DUMMY;--10
语法:
TO_VARCHAR (value [, format])
描述:
将给定 value 转换为 VARCHAR 字符串类型。如果省略 format 关键字,转换将会使用 Date Formats中说明的日期格式模型。
例子:
SELECT TO_VARCHAR (TO_DATE(‘2009-12-31‘), ‘YYYY/MM/DD‘) "to char"FROM DUMMY;--2009/12/31
语法:
ADD_DAYS (d, n)
描述:
计算日期 d 后 n 天的值。
例子:
SELECT ADD_DAYS (TO_DATE (‘2009-12-05‘, ‘YYYY-MM-DD‘), 30) "add days"FROM DUMMY;--2010-1-4
语法:
ADD_MONTHS (d, n)
描述:
计算日期 d 后 n 月的值。
例子:
SELECT ADD_MONTHS (TO_DATE (‘2009-12-05‘, ‘YYYY-MM-DD‘), 1) "add months"FROM DUMMY--2010-1-5
语法:
ADD_SECONDS (t, n)
描述:
计算时间 t 后 n 秒的值。
例子:
SELECT ADD_SECONDS (TO_TIMESTAMP (‘2012-01-01 23:30:45‘), 15) "add seconds"FROM DUMMY;--2012-1-1 23:31:00.0
语法:
ADD_YEARS (d, n)
描述:
计算日期 d 后 n 年的值。
例子:
SELECT ADD_YEARS (TO_DATE (‘2009-12-05‘, ‘YYYY-MM-DD‘), 1) "add years"FROM DUMMY;--2010-12-5
语法:
CURRENT_DATE
描述:
返回当前本地系统日期。
例子:
selectcurrent_date from dummy;--2015-6-12
语法:
CURRENT_TIME
描述:
返回当前本地系统时间。
例子:
select current_time from dummy;--16:58:11
语法:
CURRENT_TIMESTAMP
描述:
返回当前本地系统的时间戳信息。
例子:
selectcurrent_timestamp from dummy;--2015-6-12 16:58:11.471
语法:
CURRENT_UTCDATE
描述:
返回当前 UTC 日期。 UTC 代表协调世界时,也被称为格林尼治标准时间( GMT)。
例子:
SELECT CURRENT_UTCDATE "Coordinated Universal Date"FROM DUMMY;--2015-6-12
语法:
CURRENT_UTCTIME
描述:
返回当前 UTC 时间。
例子:
SELECTCURRENT_TIMESTAMP,CURRENT_UTCTIME "Coordinated Universal Time"FROM DUMMY;--2015-6-12 23:25:49.721;15:25:49
语法:
CURRENT_UTCTIMESTAMP
描述:
返回当前 UTC 时间戳。
例子:
SELECTCURRENT_TIMESTAMP,CURRENT_UTCTIMESTAMP "Coordinated Universal Timestamp"FROM DUMMY;-2015-6-12 23:28:07.62;2015-6-12 15:28:07.62
语法:
DAYNAME (d)
描述:
返回一周中日期 d 的英文名。
例子:
SELECTDAYNAME (‘2011-05-30‘) "dayname"FROM DUMMY;--MONDAY
语法:
DAYOFMONTH (d)
描述:
返回一个月中日期 d 的整数数字(即一个月中的几号)。
例子:
SELECT DAYOFMONTH (‘2011-05-30‘) "dayofmonth"FROM DUMMY;--30
语法:
DAYOFYEAR (d)
描述:
返回一年中代表日期 d 的整数数字(即一年中的第几天)。
例子:
SELECTDAYOFYEAR (‘2011-02-01‘) "dayofyear"FROM DUMMY;--32
语法:
DAYS_BETWEEN (d1, d2)
描述:
计算 d1 和 d2 之间的天数(只包括一端:[d1,d2)或者(d1,d2])。
例子:
SELECTDAYS_BETWEEN (TO_DATE (‘2015-01-01‘, ‘YYYY-MM-DD‘), TO_DATE(‘2015-02-02‘, ‘YYYY-MM-DD‘)) "days between"FROM DUMMY;--32
SELECTDAYS_BETWEEN (‘2015-01-01‘,‘2015-02-02‘) "days between"FROM DUMMY;--32 类型隐式转换(字符转日期)
SELECTDAYS_BETWEEN (‘2015-02-01‘,‘2015-03-01‘) "days between"FROM DUMMY;--28
语法:
EXTRACT ({YEAR | MONTH | DAY | HOUR | MINUTE | SECOND} FROM d)
描述:
返回日期 d 中指定的时间日期字段的值(年、月、日、时、分、秒)。
例子:
SELECTEXTRACT(YEARFROM TO_DATE(‘2010-01-04‘, ‘YYYY-MM-DD‘)) "年",EXTRACT(MONTHFROM‘2010-01-04‘) "月" ,EXTRACT(DAYFROM‘2010-01-04‘) "日" ,EXTRACT(HOURFROM‘2010-01-04 05‘) "时",EXTRACT(MINUTEFROM‘2010-01-04 05‘) "分",EXTRACT(SECONDFROM‘2010-01-04 05:06:07‘) "秒"FROM DUMMY;
![]()
语法:
HOUR (t)
描述:
返回时间 t 中表示小时的整数。
例子:
SELECTHOUR (‘12:34:56‘) "hour"FROM DUMMY;--12
语法:
ISOWEEK (d)
描述:
返回日期 d 的 ISO 年份和星期数。星期数前缀为字母 W。另请阅 WEEK。
例子:
SELECT ISOWEEK (TO_DATE(‘2011-05-30‘, ‘YYYY-MM-DD‘)) "isoweek"FROM DUMMY;--2011-W22
语法:
LAST_DAY (d)
描述:
返回包含日期 d 的月的最后一天日期。
例子:
SELECT LAST_DAY (TO_DATE(‘2010-01-04‘, ‘YYYY-MM-DD‘)) "last day"FROM DUMMY;--2010-1-31
语法:
LOCALTOUTC (t, timezone)
描述:
将 timezone 下的本地时间 t 转换为 UTC 时间(UTC:通用协调时, Universal Time Coordinated。北京时区是东八区,领先UTC 8个小时,UTC + 时区差=本地时间)。
例子:
SELECT LOCALTOUTC (TO_TIMESTAMP(‘2012-01-01 01:00:00‘, ‘YYYY-MM-DD HH24:MI:SS‘), ‘EST‘) "localtoutc"FROM DUMMY;--2012-1-1 6:00:00.0
语法:
MINUTE(t)
描述:
返回时间 t 中表示分钟的数字。
例子:
SELECTMINUTE (‘12:34:56‘) "minute"FROM DUMMY;--34
语法:
MONTH(d)
描述:
返回日期 d 所在月份的数字。
例子:
SELECTMONTH (‘2011-05-30‘) "month"FROM DUMMY;--5
语法:
MONTHNAME(d)
描述:
返回日期 d 所在月份的英文名。
例子:
SELECTMONTHNAME (‘2011-05-30‘) "monthname"FROM DUMMY;--MAY
语法:
NEXT_DAY (d)
描述:
返回日期 d 的第二天。
例子:
SELECT NEXT_DAY (TO_DATE (‘2009-12-31‘, ‘YYYY-MM-DD‘)) "next day"FROM DUMMY;--2010-1-1
语法:
NOW ()
描述:
返回当前时间戳。
例子:
SELECT NOW () "now"FROM DUMMY;--2015-6-12 17:23:01.773
语法:
QUARTER (d, [, start_month ])
描述:
返回日期 d 的年份,季度。第一季度由 start_month 定义的月份开始,如果没有定义start_month,第一季度假设为从一月开始。
例子:
SELECTQUARTER (TO_DATE(‘2012-01-01‘, ‘YYYY-MM-DD‘), 2) "quarter"FROM DUMMY;--2011-Q4
语法:
SECOND (t)
描述:
返回时间 t 表示的秒数。
例子:
SELECTSECOND (‘12:34:56‘) "second"FROM DUMMY;--56
语法:
SECONDS_BETWEEN (d1, d2)
描述:
计算日期参数 d1 和 d2 之间的秒数,语义上等同于 d2-d1。
例子:
SELECT SECONDS_BETWEEN (‘2015-01-01 01:01:01‘, ‘2015-01-01 02:01:01‘) "seconds between"FROM DUMMY;--3600
SELECT SECONDS_BETWEEN (‘2015-01-01 01:01:01‘, ‘2015-01-01 01:02:02‘) "seconds between"FROM DUMMY;--61
SELECT SECONDS_BETWEEN (‘2015-01-01 01:01:01‘, ‘2015-01-01 01:01:02‘) "seconds between"FROM DUMMY;--1
语法:
UTCTOLOCAL (t, timezone)
描述:
将 UTC 时间值转换为时区 timezone 下的本地时间。
例子:
SELECT UTCTOLOCAL(TO_TIMESTAMP(‘2012-01-01 01:00:00‘, ‘YYYY-MM-DD HH24:MI:SS‘), ‘EST‘) "utctolocal"FROM DUMMY;--2011-12-31 20:00:00.0
语法:
WEEK (d)
描述:
返回日期 d 所在星期的整数数字。另请参阅 ISOWEEK。
例子:
SELECTWEEK(TO_DATE(‘2011-05-30‘, ‘YYYY-MM-DD‘)) "week"FROM DUMMY;--23
语法:
WEEKDAY (d)
描述:
返回代表日期 d 所在星期的日期数字(星期几)。返回值范围为 0 至 6,表示 Monday(0)至 Sunday(6)。
例子:
SELECTWEEKDAY (TO_DATE (‘2011-01-02‘, ‘YYYY-MM-DD‘)) "week day"FROM DUMMY;--6
SELECTWEEKDAY (TO_DATE (‘2011-01-03‘, ‘YYYY-MM-DD‘)) "week day"FROM DUMMY;--0
语法:
YEAR (d)
描述:
返回日期 d 所在的年份数。
例子:
SELECTYEAR (TO_DATE (‘2011-05-30‘, ‘YYYY-MM-DD‘)) "year"FROM DUMMY;--2011
数字函数接受数字或者带有数字的字符串作为输入,返回数值。 当数字字符的字符串作为输入时,在计算结果前,自动执行字符串到数字的隐式转换。
语法:
ABS (n)
描述:
返回数字参数 n 的绝对值。
例子:
SELECTABS (-1) "absolute"FROM DUMMY;--1
语法:
ACOS (n)
描述:
返回参数 n 的反余弦,以弧度为单位,值为-1 至 1。
例子:
SELECTACOS (0.5) "acos"FROM DUMMY;--1.0471975511965979
语法:
ASIN (n)
描述:
返回参数 n 的反正弦值,以弧度为单位,值为-1 至 1。
例子:
SELECTASIN (0.5) "asin"FROM DUMMY;--0.5235987755982989
语法:
ATAN (n)
描述:
返回参数 n 的反正切值,以弧度为单位, n 的范围为无限。
例子:
SELECTATAN (0.5) "atan"FROM DUMMY;--0.4636476090008061
语法:
ATAN2 (n, m)
描述:
返回两数 n 和 m 比率的反正切值,以弧度为单位。这和 ATAN(n/m)的结果一致。
例子:
SELECTATAN2 (1.0, 2.0) "atan2"FROM DUMMY;--0.4636476090008061
语法:
BINTOHEX (expression)
描述:
将二进制值转换为十六进制。
例子:
SELECT BINTOHEX(‘AB‘) "bintohex"FROM DUMMY;--4142 先会将“AB”字符串隐式转换为二进制??
SELECT TO_BINARY (‘AB‘) "to binary"FROM DUMMY;--4142 显示时却是以十六进制显示,而不是二进制?
语法:
BITAND (n, m)
描述:
对参数 n 和 m 的位执行 AND 操作(即按位与)。 n 和 m 都必须是非负整数。 BITAND 函数返回 BIGINT 类型的结果。
例子:
SELECT BITAND (255, 123) "bitand"FROM DUMMY;--123
语法:
CEIL(n)
描述:
返回大于或者等于 n 的第一个整数(大小它的最小整数)
例子:
SELECT CEIL (14.5) "ceiling"FROM DUMMY;--15
语法:
COS (n)
描述:
返回参数 n 的余弦值,以弧度为单位。
例子:
SELECTCOS (0.0) "cos"FROM DUMMY;--1
语法:
COSH (n)
描述:
返回参数 n 的双曲余弦值。
例子:
SELECT COSH (0.5) "cosh"FROM DUMMY;--1.1276259652063807
语法:
COT (n)
描述:
计算参数 n 的余切值,其中 n 以弧度表示。
例子:
SELECTCOT (40) "cot"FROM DUMMY;-- -0.8950829176379128
语法:
EXP (n)
描述:
返回以 e 为底, n 为指数的计算结果。
例子:
SELECTEXP (1.0) "exp"FROM DUMMY;--2.718281828459045
语法:
FLOOR (n)
描述:
返回不大于参数 n 的最大整数。
例子:
SELECTFLOOR (14.5) "floor"FROM DUMMY;--14
语法:
GREATEST (n1 [, n2]...)
描述:
返回参数 n1,n2,…最大数。
例子:
SELECT GREATEST (‘aa‘, ‘ab‘, ‘bb‘, ‘ba‘) "greatest"FROM DUMMY;--bb
语法:
HEXTOBIN (value)
描述:
将十六进制数转换为二进制数。
例子:
SELECTHEXTOBIN (‘1a‘) "hextobin"FROM DUMMY;--1A 还是以十六进制来显示?
语法:
LEAST (n1 [, n2]...)
描述:
返回参数 n1,n2,…最小数。
例子:
SELECT LEAST(‘aa‘, ‘ab‘, ‘ba‘, ‘bb‘) "least"FROM DUMMY;--aa
语法:
LN (n)
描述:
返回参数 n 的自然对数。
例子:
SELECTLN (9) "ln"FROM DUMMY;--2.1972245773362196
语法:
LOG (b, n)
描述:
返回以 b 为底, n 的自然对数值。底 b 必须是大于 1 的正数,且 n 必须是正数。
例子:
SELECTLOG (10, 2) "log"FROM DUMMY;--0.30102999566398114
语法:
MOD (n, d)
描述:
返回 n 整除 b 的余数值。
当 n 为负时,该函数行为不同于标准的模运算。
以下列举了 MOD 函数返回结果的例子
如果 d 为零,返回 n。
如果 n 大于零,且 n 小于 d,则返回 n。
如果 n 小于零,且 n 大于 d,则返回 n。
在上文提到的其他情况中,利用 n 的绝对值除以 d 的绝对值来计算余数。如果 n 小于 0,则 MOD返回的余数为负数;如果 n 大于零, MOD 返回的余数为正数。
例子:
SELECTMOD (15, 4) "modulus"FROM DUMMY;--3
SELECTMOD (-15, 4) "modulus"FROM DUMMY;-- -3
语法:
POWER (b, e)
描述:
计算以 b 为底, e 为指数的值。
例子:
SELECTPOWER (2, 10) "power"FROM DUMMY;--1024
语法:
ROUND (n [, pos])
描述:
返回参数 n 小数点后 pos 位置的值(四舍五入)。
例子:
SELECTROUND (16.16, 1) "round"FROM DUMMY;--16.2
SELECTROUND (16.16, -1) "round"FROM DUMMY;--20
语法:
SIGN (n)
描述:
返回 n 的符号(正或负)。如果 n 为正,则返回 1; n 为负,返回-1, n 为 0 返回 0。
例子:
SELECTSIGN (-15) "sign"FROM DUMMY;-- -1
语法:
SIN (n)
描述:
返回参数 n 的正弦值,以弧度为单位。
例子:
SELECTSIN(3.141592653589793/2) "sine"FROM DUMMY;--1
语法:
SINH (n)
描述:
返回 n 的双曲正弦值,以弧度为单位。
例子:
SELECT SINH (0.0) "sinh"FROM DUMMY;--0
语法:
SQRT (n)
描述:
返回 n 的平方根。
例子:
SELECTSQRT (2) "sqrt"FROM DUMMY;--1.4142135623730951
语法:
TAN (n)
描述:
返回 n 的正切值,以弧度为单位。
例子:
SELECTTAN (0.0) "tan"FROM DUMMY;--0
语法:
TANH (n)
描述:
返回 n 的双曲正切值,以弧度为单位。
例子:
SELECT TANH (1.0) "tanh"FROM DUMMY;--0.7615941559557649
语法:
UMINUS (n)
描述:
返回 n 的负值。
例子:
SELECT UMINUS(-765) "uminus"FROM DUMMY;--756
SELECT UMINUS(765) "uminus"FROM DUMMY;-- -756
语法:
ASCII(c)
描述:
返回字符串 c 中第一个字节的 ASCII 值。
SELECTASCII(‘Ant‘) "ascii"FROM DUMMY;--65
语法:
CHAR (n)
描述:
返回 ASCII 值为数字 n 的字符。
例子:
SELECTCHAR (65) || CHAR (110) || CHAR (116) "character"FROM DUMMY;--Ant
语法:
CONCAT (str1, str2)
描述:
返回位于 str1 后的 str2 联合组成的字符串。级联操作符(||)与该函数作用相同。
例子:
SELECTCONCAT (‘C‘, ‘at‘) "concat"FROM DUMMY;--Cat
语法:
LCASE(str)
描述:
将字符串 str 中所有字符转换为小写。
注意: LCASE 函数作用与 LOWER 函数相同。
例子:
SELECTLCASE (‘TesT‘) "lcase"FROM DUMMY;--test
语法:
LEFT (str, n)
描述:
返回字符串 str 开头 n 个字符/位的字符。
例子:
SELECTLEFT (‘Hello‘, 3) "left"FROM DUMMY;--Hel
语法:
LENGTH(str)
描述:
返回字符串 str 中的字符数。对于大对象(LOB)类型,该函数返回对象的字节长度。
例子:
SELECTLENGTH (‘length in char‘) "length"FROM DUMMY;--14
语法:
LOCATE (haystack, needle)
描述:
返回字符串 haystack 中子字符串 needle 所在的位置。如果未找到,则返回 0。
例子:
SELECTLOCATE (‘length in char‘, ‘char‘) "locate"FROM DUMMY;--11
SELECTLOCATE (‘length in char‘, ‘length‘) "locate"FROM DUMMY;--1
SELECTLOCATE (‘length in char‘, ‘zchar‘) "locate"FROM DUMMY;--0
语法:
LOWER (str)
描述:
将字符串 str 中所有字符转换为小写。
注意: LOWER 函数作用与 LCASE 相同。
例子:
SELECTLOWER (‘AnT‘) "lower"FROM DUMMY;--ant
语法:
LPAD (str, n [, pattern])
描述:
从左边开始对字符串 str 使用空格进行填充,达到 n 指定的长度。如果指定了 pattern 参数,字符串 str 将按顺序填充直到满足 n 指定的长度。
例子:
SELECT LPAD (‘end‘, 15, ‘12345‘) "lpad"FROM DUMMY;--123451234512end
语法:
LTRIM (str [, remove_set])
描述:
返回字符串 str 截取所有前导空格后的值。如果定义了 remove_set, LTRIM 从起始位置移除字符串str 包含该集合中的字符,该过程持续至到达不在 remove_set 中的字符。
注意: remove_set 被视为字符集合,而非搜索字符。
例子:
SELECTLTRIM (‘babababAabend‘,‘ab‘) "ltrim"FROM DUMMY;--Aabend
语法:
NCHAR (n)
描述:
返回整数 n 表示的 Unicode 字符。
例子:
SELECT UNICODE (‘江‘) "unicode"FROM DUMMY;--27743
SELECTNCHAR (27743) "nchar"FROM DUMMY;--江
语法:
REPLACE (original_string, search_string, replace_string)
描述:
搜索 original_string 所有出现的 search_string,并用 replace_string 替换。
如果 original_string 为空, 则返回值也为空。
如果 original_string 中两个重叠的子字符串与 search_string 匹配,只有第一个会被替换:
SELECTREPLACE (‘abcbcb‘,‘bcb‘, ‘‘) "replace"FROM DUMMY;--acb
如果 original_string 未出现 search_string,则返回未修改的 original_string。
如果 original_string, search_string 或者 replace_string 为 NULL,则返回值也为 NULL。
例子:
SELECTREPLACE (‘DOWNGRADE DOWNWARD‘,‘DOWN‘, ‘UP‘) "replace"FROM DUMMY;--UPGRADE UPWARD
语法:
RIGHT(str, n)
描述:
返回字符串 str 中最右边的 n 字符/字节。
例子:
SELECTRIGHT(‘HI0123456789‘, 3) "right"FROM DUMMY;--789
语法:
RPAD (str, n [, pattern])
描述:
从尾部开始对字符串 str 使用空格进行填充,达到 n 指定的长度。如果指定了 pattern 参数,字符串 str 将按顺序填充直到满足 n 指定的长度。
例子:
SELECT RPAD (‘end‘, 15, ‘12345‘) "right padded"FROM DUMMY;--end123451234512
语法:
RTRIM (str [,remove_set ])
描述:
返回字符串 str 截取所有后置空格后的值。如果定义了 remove_set, RTRIM 从尾部位置移除字符串 str 包含该集合中的字符,该过程持续至到达不在 remove_set 中的字符。
注意: remove_set 被视为字符集合,而非搜索字符。
例子:
SELECTRTRIM (‘endabAabbabab‘,‘ab‘) "rtrim"FROM DUMMY;--endabA
语法:
SUBSTR_AFTER (str, pattern)
描述:
返回 str 中位于 pattern 第一次出现位置后的子字符串。
如果 str 不包含 pattern 子字符串,则返回空字符串。
如果 pattern 为空字符串,则返回 str。
如果 str 或者 pattern 为 NULL,则返回 NULL。
例子:
SELECT SUBSTR_AFTER (‘Hello My Friend‘,‘My‘) "substr after"FROM DUMMY;-- ‘ Friend‘
语法:
SUBSTR_BEFORE (str, pattern)
描述:
返回 str 中位于 pattern 第一次出现位置前的子字符串。
如果 str 不包含 pattern 子字符串,则返回空字符串。
如果 pattern 为空字符串,则返回 str。
如果 str 或者 pattern 为 NULL,则返回 NULL。
例子:
SELECT SUBSTR_BEFORE (‘Hello My Friend‘,‘My‘) "substr before"FROM DUMMY;--‘Hello ‘
语法:
SUBSTRING (str, start_position [, string_length])
描述:
返回字符串 str 从 start_position 开始的子字符串。 SUBSTRING 可以返回 start_position 起的剩余部分字符或者作为可选,返回由 string_length 参数设置的字符数。
如果 start_position 小于 0,则被视为 1。
如果 string_length 小于 1,则返回空字符串。
例子:
SELECTSUBSTRING (‘1234567890‘,4,2) "substring"FROM DUMMY;--45
语法:
TRIM ([[LEADING | TRAILING | BOTH] trim_char FROM] str )
描述:
返回移除前导和后置空格后的字符串 str。截断操作从起始(LEADING)、结尾(TRAILING)或者两端(BOTH)执行。
如果 str 或者 trim_char 为空,则返回 NULL。
如果没有指定可选项, TRIM 移除字符串 str 中两端的子字符串 trim_char。
如果没有指定 trim_char,则使用单个空格(就是去空格)。
例子:
SELECTTRIM (‘a‘FROM‘aaa123456789aa‘) "trim both"FROM DUMMY;--123456789
SELECTTRIM (LEADING‘a‘FROM‘aaa123456789aa‘) "trim leading"FROM DUMMY;--123456789aa
语法:
UCASE (str)
描述:
将字符串 str 中所有字符转换为大写。
注意: UCASE 函数作用与 UPPER 函数相同。
例子:
SELECTUCASE (‘Ant‘) "ucase"FROM DUMMY;--ANT
语法:
UNICODE(c)
描述:
返回字符串中首字母的 UnIcode 字符码数字;如果首字母不是有效编码,则返回 NULL。
例子:
SELECT UNICODE (‘江‘) "unicode"FROM DUMMY;--27743
SELECTNCHAR (27743) "nchar"FROM DUMMY;--江
语法:
UPPER (str)
描述:
将字符串 str 中所有字符转换为大写。
注意: UPPER 函数作用与 UCASE 相同。
例子:
SELECTUPPER (‘Ant‘) "uppercase"FROM DUMMY;--ANT
语法:
COALESCE (expression_list)
描述:
返回 list 中非 NULL 的表达式。 Expression_list 中必须包含至少两个表达式,并且所有表达式都是可比较的。如果所有的参数都为 NULL,则结果也为 NULL。
例子:
CREATETABLE coalesce_example (ID INTPRIMARYKEY, A REAL, B REAL);
INSERTINTO coalesce_example VALUES(1, 100, 80);
INSERTINTO coalesce_example VALUES(2, NULL, 63);
INSERTINTO coalesce_example VALUES(3, NULL, NULL);
SELECT id, a, b, COALESCE (a, b*1.1, 50.0) "coalesce"FROM coalesce_example
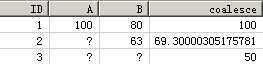
语法:
CURRENT_CONNECTION
描述:
返回当前连接 ID。
例子:
SELECT CURRENT_CONNECTION "current connection"FROM DUMMY;--400,038
语法:
CURRENT_SCHEMA
描述:
返回当前Schema名。
例子:
SELECT CURRENT_SCHEMA "current schema"FROM DUMMY;--SYSTEM
语法:
CURRENT_USER
描述:
返回当前语句上下文的用户名,即当前授权堆栈顶部的用户名。
例子:
--使用SYSTEM用户执行基础SQL
SELECT CURRENT_USER "current user"FROM DUMMY;--SYSTEM
-- USER_A用户创建存储过程
CREATEPROCEDUREUSER_A.PROC1 LANGUAGE SQLSCRIPT SQL SECURITY DEFINER AS
BEGIN
SELECT CURRENT_USER "current user"FROM DUMMY;
END;
-- USER_A用户调用
CALL USER_A.PROC1;--USER_A
--授权予USER_B执行USER_A.PROC1的权限后调用
CALL USER_A.PROC1;--USER_A
--将Schema USER_A授权予USER_B用户后,通过USER_B用户创建存储过程
CREATEPROCEDUREUSER_A.PROC2 LANGUAGE SQLSCRIPT SQL SECURITY INVOKER AS
BEGIN
SELECT CURRENT_USER "current user"FROM DUMMY;
END;
-- USER_A用户调用
CALL USER_A.PROC2;-- USER_A
-- USER_B用户调用
CALL USER_A.PROC2;-- USER_B
语法:
GROUPING_ID(column_name_list)
描述:
GROUPING_ID 函数可以使用 GROUPING SETS 返回单个结果集中的多级聚集。 GROUPING_ID 返回一个整数识别每行所在的组集合。 GROUPING_ID 每一列必须是 GROUPING SETS 中的元素。
通过把生成的位矢量从 GROUPING SETS 转换为十进制数,将位矢量视作二进制数,分配GROUPING_ID。组成位矢量后,0 分配给 GROUPING SETS 指定的每一列,否则根据 GROUPING SETS 出现的顺序分配 1。通过将位矢量作为二进制数处理,该函数返回一个整型值作为输出。
例子:
SELECT customer, year, product, SUM(sales),GROUPING_ID(customer, year, product)
FROM guided_navi_tab
GROUPBYGROUPING SETS ((customer, year, product),(customer, year),(customer, product),(year, product),(customer),(year),(product));
CUSTOMER YEAR PRODUCT SUM(SALES) GROUPING_ID(CUSTOMER,YEAR,PRODUCT)
1 C1 2009 P1 100 0
2 C1 2010 P1 50 0
3 C2 2009 P1 200 0
4 C2 2010 P1 100 0
5 C1 2009 P2 200 0
6 C1 2010 P2 150 0
7 C2 2009 P2 300 0
8 C2 2010 P2 150 0
9 C1 2009 a 300 1
10 C1 2010 a 200 1
11 C2 2009 a 500 1
12 C2 2010 a 250 1
13 C1 a P1 150 2
14 C2 a P1 300 2
15 C1 a P2 350 2
16 C2 a P2 450 2
17 a 2009 P1 300 4
18 a 2010 P1 150 4
19 a 2009 P2 500 4
20 a 2010 P2 300 4
21 C1 a a 500 3
22 C2 a a 750 3
23 a 2009 a 800 5
24 a 2010 a 450 5
25 a a P1 450 6
26 a a P2 800 6
语法:
IFNULL (expression1, expression2)
描述:
返回输入中第一个不为 NULL 的表达式。
如果 expression1 不为 NULL,则返回 expression1。
如果 expression2 不为 NULL,则返回 expression2。
如果输入表达式都为 NULL,则返回 NULL。
例子:
SELECTIFNULL (‘diff‘, ‘same‘) "ifnull"FROM DUMMY;--diff
SELECTIFNULL (NULL, ‘same‘) "ifnull"FROM DUMMY;--same
SELECTIFNULL (NULL, NULL) "ifnull"FROM DUMMY;--null
语法:
MAP (expression, search1, result1 [, search2, result2] ... [, default_result])
描述:
在搜索集合中搜索 expression,并返回相应的结果。
如果未找到 expression 值,并且定义了 default_result,则 MAP 返回 default_result。
如果未找到 expression 值,并且未定义 default_result,MAP 返回 NULL。
注意:
搜索值和相应的结果总是以搜索-结果方式提供。
例子:
SELECTMAP(2, 0, ‘Zero‘, 1, ‘One‘, 2, ‘Two‘, 3, ‘Three‘, ‘Default‘) "map"FROM DUMMY;--Two
SELECTMAP(99, 0, ‘Zero‘, 1, ‘One‘, 2, ‘Two‘, 3, ‘Three‘, ‘Default‘) "map"FROM DUMMY;--Default
SELECTMAP(99, 0, ‘Zero‘, 1, ‘One‘, 2, ‘Two‘, 3, ‘Three‘) "map"FROM DUMMY;--null
语法:
NULLIF (expression1, expression2)
描述:
NULLIF 比较两个输入表达式的值,如果第一个表达式等于第二个,NULLIF 返回 NULL。
如果 expression1 不等于 expression2,NULLIF 返回 expression1。
如果 expression2 为 NULL,NULLIF 返回 expression1。
第一个参数不能是NULL
例子:
SELECTNULLIF (‘diff‘, ‘same‘) "nullif"FROM DUMMY;--diff
SELECTNULLIF(‘same‘, ‘same‘) "nullif"FROM DUMMY;--null
SELECTNULLIF(‘same‘, null) "nullif"FROM DUMMY;--same
语法:
SESSION_CONTEXT(session_variable)
描述:
返回分配给当前用户的 session_variable 值。
访问的 session_variable ,可以是预定义或者用户自定义。预定义的会话变量可以通过客户端设置的有‘APPLICATION‘, ‘APPLICATIONUSER‘以及‘TRACEPROFILE‘。
会话变量可以定义或者修改通过使用命令 SET [SESSION] <variable_name> = <value>,使用 UNSET [SESSION] <variable_name>取消设置。
SESSION_CONTEXT 返回最大长度为 512 字符的 NVARCHAR 类型。
例子:
读取会话变量:
SELECT SESSION_CONTEXT(‘APPLICATION‘) "session context"FROM DUMMY;--HDBStudio
语法:
SESSION_USER
描述:
返回当前会话的用户名。
例子:
-- example showing basic function operation using SYSTEM user
SELECT SESSION_USER "session user"FROM DUMMY;--SYSTEM
SYSUUID
语法:
描述:
返回 SAP HANA 连接实例的 SYSUUID。
例子:
SELECT SYSUUID FROM DUMMY;--557A323598FE12F4E20036775F49B32D
本章描述 SAP HANA 数据库支持的 SQL 语句。
? Schema Definition and Manipulation Statements Schema操纵语句
? Data Manipulation Statements 数据操纵语句
? System Management Statements 系统管理语句
? Session Management Statements 会话管理语句
? Transaction Management Statements 事务管理语句
? Access Control Statements 访问控制语句
? Data Import Export Statements 数据导入导出语句
语法:
ALTER AUDIT POLICY <policy_name> <audit_mode>
语法元素:
<policy_name> ::= <identifier>
被改变的审计策略名:
<audit_mode> ::= ENABLE | DISABLE
Audit_mode 启用或禁用审计策略。
ENABLE:启用审计策略。
DISABLE:禁用审计策略。
描述:
ALTER AUDIT POLICY 语句启用或禁用审计策略。 <policy_name>必须定义一个已存在的审计策略名。
只有拥有系统权限 AUDIT ADMIN 的数据库用户允许改变审计策略。每个拥有该权限的数据库用户可以修改任意的审计策略,无论是否由该用户创建。
新建的审计策略默认为禁用,并且不会发生任何审计。因此,必须启动该审计策略来执行审计。
审计策略可以视需要禁用和启用。
配置参数:
以下审计的配置参数存储在文件 global.ini,在审计配置部分:
global_auditing_state ( ‘true‘ / ‘false‘ )
无论启动的审计策略数量多少,审计只会在配置参数 global_auditing_state 设置为 true 时启用,默认值 false。
default_audit_trail_type ( ‘SYSLOGPROTOCOL‘ / ‘CSVTEXTFILE‘ ) 指定如何存储审计结果。
SYSLOGPROTOCOL:使用系统 syslog。
CSVTEXTFILE:审计信息值以逗号分隔存储在一个文本文件中。
default_audit_trail_path
指定 CSVTEXTFILE 存储的文件路径。
如果用户拥有需要的系统权限,参数可以在监控视图 M_INIFILE_CONTENTS 中选择。这些只有在显示设置的情况下才可见。
系统表和监控视图:
AUDIT_POLICY:显示所有审计策略和状态。
M_INIFILE_CONTENTS:显示数据库系统配置参数。
只有拥有系统权限 CATALOG READ, DATA ADMIN 或 INIFILE ADMIN 的用户可以查看
M_INIFILE_CONTENTS 视图中的内容,对于其他用户则为空。
例子:
该例子中你需要先利用如下语句创建名为 priv_audit 的审计权限:
CREATE AUDIT POLICY priv_audit AUDITING SUCCESSFUL GRANT PRIVILEGE, REVOKE PRIVILEGE, GRANT ROLE, REVOKE ROLE LEVEL CRITICAL;
现在你可以启用审计策略:
ALTER AUDIT POLICY priv_audit ENABLE;
你也可以禁用该审计策略:
ALTER AUDIT POLICY priv_audit DISABLE;
语法:
ALTER FULLTEXT INDEX <index_name> <alter_fulltext_index_option>
语法元素:
<index_name> ::= <identifier>
被修改的全文索引标识符:
<alter_fulltext_index_option> ::= <fulltext_parameter_list> | <queue_command> QUEUE
定义了全文索引的参数或者全文索引队列的状态是否应该修改。后者只对异步显式全文索引可见。
<fulltext_parameter_list> ::= <fulltext_parameter> [, ...]
修改的全文索引参数列表:
<fulltext_parameter> ::= FUZZY SEARCH INDEX <on_off>
| PHRASE INDEX RATIO <index_ratio>
| <change_tracking_elem>
<on_off> ::= ON | OFF
FUZZY SEARCH INDEX
使用模糊搜索索引。
PHRASE INDEX RATIO
定义短语索引比率。
<index_ratio> ::= <float_literal>
定义短语索引比率的百分比,值必须为 0.0 与 1.0 之间。
SYNC[HRONOUS]
改变全文索引至同步模式。
ASYNC[HRONOUS]
改变全文索引至异步模式。
<flush_queue_elem> ::= EVERY <integer_literal> MINUTES
| AFTER <integer_literal> DOCUMENTS
| EVERY <integer_literal> MINUTES OR AFTER <integer_literal>
DOCUMENTS
当使用异步索引时,你可以利用 flush_queue_elem 定义更新全文索引的时间。
<queue_command> ::= FLUSH | SUSPEND | ACTIVATE
FLUSH
利用正在处理队列的文件更新全文索引。
SUSPEND
暂停全文索引处理队列。
ACTIVATE
激活全文索引处理队列。
描述:
使用该命令,你可以修改全文索引的参数或者索引处理队列的状态。队列是用来激活全文索引以
异步方式工作的机制,例如插入操作被阻塞,直到文件处理完。
ALTER FULLTEXT INDEX <index_name> <fulltext_elem_list>语句修改全文索引的参数。
ALTER FULLTEXT INDEX <index_name> <queue_parameters>语句修改异步全文索引的处理队列状
态。
例子:
ALTER FULLTEXT INDEX i1 PHRASE INDEX RATIO 0.3 FUZZY SEARCH INDEX ON
在上述例子中,对于全文索引’i1’,短文索引比率设为 30,,并且启用了模糊搜索索引。
ALTER FULLTEXT INDEX i2 SUSPEND QUEUE
暂停全文索引’i2’的队列
ALTER FULLTEXT INDEX i2 FLUSH QUEUE
利用队列中已处理的文件更新全文索引’i2’。
ALTER INDEX <index_name> REBUILD
语法元素:
<index_name>::= <identifier>
定义重建的索引名。
描述:
ALTER INDEX 语句重建索引。
例子:
以下例子重建索引 idx。
ALTER INDEX idx REBUILD;
语法:
ALTER SEQUENCE <sequence_name> [<alter_sequence_parameter_list>]
[RESET BY <reset_by_subquery>]
语法元素:
<sequence_name> ::= <identifier>
被修改的序列名。
<alter_sequence_parameter_list> ::= <alter_sequence_parameter>, ...
<alter_sequence_parameter> ::= <sequence_parameter_restart_with>
| <basic_sequence_parameter>
<sequence_parameter_restart_with> ::= RESTART WITH <restart_value>
<basic_sequence_parameter> ::= INCREMENT BY <increment_value>
| MAXVALUE <maximum_value>
| NO MAXVALUE
| MINVALUE <minimum_value>
| NO MINVALUE
| CYCLE
| NO CYCLE
RESTART WITH
序列的起始值。如果你没有指定 RESTART WITH 子句的值,将使用当前序列值。
<restart_value> ::= <integer_literal>
由序列生成器提供的第一个值为 0 至 4611686018427387903 之间的整数。
INCREMENT BY
序列增量值。
<increment_value> ::= <integer_literal>
利用一个整数增加或者减少序列的值。
MAXVALUE
定义序列生成的最大值。
<maximum_value> ::= <integer_literal>
一个正整数定义序列可生成的最大数值,必须为 0 至 4611686018427387903 之间。
NO MAXVALUE
使用 NO MAXVALUE 指令,递增序列的最大值将为 4611686018427387903,递减序列的最大值为-1。
MINVALUE
定义序列生成的最小值。
<minimum_value> ::= <integer_literal>
一个正整数定义序列可生成的最小数值,必须为 0 至 4611686018427387903 之间。
NO MINVALUE
使用 NO MINVALUE 指令,递增序列的最小值将为 1,递减序列的最小值为-
4611686018427387903。
CYCLE
使用 CYCLE 指令,序列在到达最大值或最小值后将会重新开始。
NO CYCLE
使用 NO CYCLE 指令,序列在到达最大值或最小值后将不会重新开始。
<reset_by_subquery> ::= <subquery>
系统重启期间,系统自动执行 RESET BY 语句,并且将用 RESET BY 子查询确定的值重启序列。
关于子查询的详情,请参阅 Subquery。
描述:
ALTER SEQUENCE 语句用来修改序列生成器的参数。
例子:
在下面的例子中,你把序列 seq 的起始序列值改为 2。
ALTER SEQUENCE seq RESTART WITH 2;
在下面的例子中,你把序列 seq 的最大值改为 100,并且没有最小值。
ALTER SEQUENCE seq MAXVALUE 100 NO MINVALUE;
在下面的例子中,你把序列 seq 的增量改为 2,并且限制为"no cycle"。
ALTER SEQUENCE seq INCREMENT BY 2 NO CYCLE;
在下面的例子中,你首先创建表 r,有一列 a。然后你将序列 seq 的 reset-by 子查询修改为列 a 包
含的最大值。
CREATE TABLE r (a INT);
ALTER SEQUENCE seq RESET BY SELECT MAX(a) FROM r;
语法:
ALTER TABLE [<schema_name>.]<table_name>{
<add_column_clause>
| <drop_column_clause>
| <alter_column_clause>
| <add_primary_key_clause>
| <drop_primary_key_clause>
| <preload_clause>
| <table_conversion_clause>
| <move_clause>
| <add_range_partition_clause>
| <move_partition_clause>
| <drop_range_partition_clause>
| <partition_by_clause>
| <disable_persistent_merge_clause>
| <enable_persistent_merge_clause>
| <enable_delta_log>
| <disable_delta_log>
| <enable_automerge>
| <disable_automerge>
}
语法元素:
<add_column_clause> ::= ADD ( <column_definition> [<column_constraint>], ...)
<drop_column_clause> ::= DROP ( <column_name>, ... )
<alter_column_clause> ::= ALTER ( <column_definition> [<column_constraint>], ... )
<column_definition> ::= <column_name> <data_type> [<column_store_data_type>][<ddic_data_type>] [DEFAULT <default_value>] [GENERATED ALWAYS AS <expression>]
<column_constraint> ::= NULL| NOT NULL| UNIQUE [BTREE | CPBTREE]| PRIMARY KEY [BTREE | CPBTREE]
<data_type> ::= DATE | TIME | SECONDDATE | TIMESTAMP | TINYINT | SMALLINT | INTEGER | BIGINT |SMALLDECIMAL | DECIMAL | REAL | DOUBLE| VARCHAR |
NVARCHAR | ALPHANUM | SHORTTEXT |VARBINARY | BLOB| CLOB | NCLOB | TEXT
<column_store_data_type> ::= CS_ALPHANUM | CS_INT | CS_FIXED | CS_FLOAT | CS_DOUBLE |CS_DECIMAL_FLOAT | CS_FIXED(p-s, s) | CS_SDFLOAT| CS_STRING |
CS_UNITEDECFLOAT | CS_DATE | CS_TIME| CS_FIXEDSTRING | CS_RAW | CS_DAYDATE | CS_SECONDTIME | CS_LONGDATE | CS_SECONDDATE
<ddic_data_type> ::= DDIC_ACCP | DDIC_ALNM | DDIC_CHAR | DDIC_CDAY | DDIC_CLNT | DDIC_CUKY| DDIC_CURR | DDIC_D16D | DDIC_D34D | DDIC_D16R |
DDIC_D34R | DDIC_D16S | DDIC_D34S| DDIC_DATS | DDIC_DAY | DDIC_DEC | DDIC_FLTP | DDIC_GUID| DDIC_INT1 | DDIC_INT2 | DDIC_INT4 | DDIC_INT8 | DDIC_LANG | DDIC_LCHR | DDIC_MIN|DDIC_MON| DDIC_LRAW | DDIC_NUMC | DDIC_PREC | DDIC_QUAN | DDIC_RAW| DDIC_RSTR | DDIC_SEC | DDIC_SRST | DDIC_SSTR | DDIC_STRG | DDIC_STXT | DDIC_TIMS| DDIC_UNIT| DDIC_UTCM | DDIC_UTCL | DDIC_UTCS | DDIC_TEXT | DDIC_VARC | DDIC_WEEK
<default_value> ::= NULL | <string_literal> | <signed_numeric_literal> | <unsigned_numeric_literal>
DEFAULT:DEFAULT 定义了 INSERT 语句没有为列提供值情况下,默认分配的值。
GENERATED ALWAYS AS:指定在运行时生成的列值的表达式。
<column_constraint> ::= NULL| NOT NULL| UNIQUE [BTREE | CPBTREE]| PRIMARY KEY [BTREE | CPBTREE]
NULL | NOT NULL:NOT NULL 禁止列的值为 NULL。如果指定了 NULL,将不被认为是常量,其表示一列可能含有空值,默认为 NULL。
UNIQUE:指定为唯一键的列。一个唯一的复合键指定多个列作为唯一键。有了 unique 约束,多行不能在同一列中具有相同的值。
PRIMARY KEY:主键约束是 NOT NULL 约束和 UNIQUE 约束的组合,其禁止多行在同一列中具有相同的值。
BTREE | CPBTREE:指定索引类型。当列的数据类型为字符串、二进制字符串、十进制数或者约束是一个组合键,或非唯一键,默认的索引类型为 CPBTREE,否则
使用 BTREE。
为了使用 B+-树索引,必须使用 BTREE 关键字;对于 CPB+-树索引,需使用 CPBTREE 关键字。
B+-树是维护排序后的数据进行高效的插入、删除和搜索记录的树。
CPB+-树表示压缩前缀 B+-树,是基于 pkB-tree 树。 CPB+树是一个非常小的索引,因为它使用“部分键”,只是索引节点全部键的一部分。对于更大的键,
CPB+-树展现出比 B+-树更好的性能。
如果省略了索引类型, SAP HANA 数据库将考虑列的数据类型选择合适的索引。
ALTER时,增加一列的长度是可以做到的。当在列式存储中尝试修改列的定义,不会返回错误,因为在数据库中没有做任何的检查。错误可能发生在选择列时,数据不符合新定义的数据类型。 ALTER 仍未遵照数据类型转换规则。
将 NOT NULL 约束添加到已存在的列是可以的,如果表为空或者表有数据时定义了默认值
<add_primary_key_clause> ::= ADD [CONSTRAINT <constraint_name>] PRIMARY KEY( <column_name>, ... )
ADD PRIMARY KEY:增加一列主键。
PRIMARY KEY:主键约束是 NOT NULL 约束和 UNIQUE 约束的组合,其禁止多行在同一列中具有相同的值。
CONSTRAINT:指定约束名。
<drop_primary_key_clause> ::= DROP PRIMARY KEY
DROP PRIMARY KEY:删除主键约束。
<preload_clause> ::= PRELOAD ALL | PRELOAD ( <column_name> ) | PRELOAD NONE
PRELOAD:设置/移除给定表或列的预载标记。 PRELOAD ALL 为表中所有列设置预载标记, PRELOAD( <column_name> )为指定的列设置标记, PRELOAD NONE 移除
所有列的标记。其结果是这些表在索引服务器启动后自动加载至内存中。预载标记的当前状态在系统表 TABLES,列 PRELOAD 中可见, 可能值为(‘FULL‘, ‘PARTIALLY‘,
‘NO‘);在系统表 TABLE_COLUMNS,列 PRELOAD,可能值为(‘TRUE‘,‘FALSE‘)。
<table_conversion_clause> ::= [ALTER TYPE] {ROW [THREADS <number_of_threads>] | COLUMN[THREADS <number_of_threads> [BATCH <batch_size>]]}
ALTER TYPE ROW | COLUMN:该命令用于将表存储类型从行转换为列或从列转换为行。
THREADS <number_of_threads>:指定进行表转换的并行线程数。线程数目的最佳值应设置为可用的 CPU 内核的数量。
Default:默认值为 param_sql_table_conversion_parallelism,即在 ndexserver.ini 文件中定义的 CPU内核数。
BATCH <batch_size>:指定批插入的行数,默认值为最佳值 2,000,000。插入表操作在每个<batch_size>记录插入后立即提交,可以减少内存消耗。 BATCH 可选项只
可以在表 从行转换为列时使用。然而,大于 2,000,000的批大小可能导致高内存消耗,因此不建议修改该值。通过复制现有的表中的列和数据,可以从现有的表
创建一个不同存储类型的新表。该命令用来把表从行转换为列或从列转换为行。如果源表是行式存储,则新建的表为列式存储。
<move_clause> ::= MOVE [PARTITION <partition_number>] TO [LOCATION ]<host_port> [PHYSICAL] |MOVE [PARTITION <partition_number>] PHYSICAL
MOVE 将表移动至分布式环境中的另一个位置。 端口号是内部索引服务器的端口号, 3xx03。如果你有一个分区表,你可以通过指定可选的分区号只移动个别部
分,移动分区表时,没有指定分区号会导致错误。
PHYSICAL 关键字只适用列式存储表。行式存储表总是物理移动。如果指定了可选关键字 PHYSICAL,持久存储立即移动至目标主机。否则,此举将创建一个新主机
里面的持久层链接指向旧主机持久层。该链接如果没有 TO<host_port>部分,将在下次合并或者移 动中删除。PHYSICAL 移动操作没有指定 TO <host_port>时,将移
除从上次移动中仍然存在的持久层链接。
LOCATION 仅支持向后兼容
<add_range_partition_clause> ::= ADD PARTITION <lower_value> <= VALUES < <upper_value>| PARTITION <value_or_values> = <target_value>| PARTITION OTHERS
ADD PARTITION:为一个分区表添加分区,使用 RANGE, HASH RANGE, ROUNDROBIN RANGE 关键字。当添加分区至一张按范围分区的表时,如果需要的话,可以对
其余分区进行重新分区。
<drop_range_partition_clause> ::= DROP PARTITION <lower_value> <= VALUES < <upper_value>| PARTITION <value_or_values> = <target_value>| PARTITION OTHERS
DROP PARTITION:删除根据 RANGE, HASH RANGE, ROUNDROBIN RANGE 分区的表的分区。
<partition_clause> ::= PARTITION BY <hash_partition> [,<range_partition> | ,<hash_partition>]| PARTITION BY <range_partition>| PARTITION BY <roundrobin_partition>
[,<range_partition>]
<hash_partition> ::=HASH (<partition_expression>[, ...]) PARTITIONS { <num_partitions> |GET_NUM_SERVERS() }
<range_partition> ::= RANGE ( <partition_expression> ) ( <range_spec> )
<roundrobin_partition> ::= ROUNDROBIN PARTITIONS {<num_partitions> |GET_NUM_SERVERS()}
<range_spec> ::= {<from_to_spec> | <single_spec>[,...] } [, PARTITION OTHERS]
<from_to_spec> ::= PARTITION <lower_value> <= VALUES < <upper_value>
<single_spec> ::= PARTITION VALUE <single_value>
<partition_expression> ::= <column_name>| YEAR(<column_name>) | MONTH(<column_name>)
PARTITION BY:使用 RANGE, HASH RANGE, ROUNDROBIN RANGE 对表进行分区。关于表分区自居,请参见 CREATE TABLE。
<merge_partition_clause> ::= MERGE PARTITIONS
MERGE PARTITIONS:合并分区表的所有部分至非分区表。
<disable_persistent_merge_clause> ::= DISABLE PERSISTENT MERGE
DISABLE PERSISTENT MERGE:指导合并管理器对于给定表,使用内存进行合并而非持久合并。
<enable_persistent_merge_clause> ::= ENABLE PERSISTENT MERGE
ENABLE PERSISTENT MERGE:指导合并管理器对于给定表使用持久合并。
<enable_delta_log> ::= ENABLE DELTA LOG
启动表日志记录。启用之后,你必须执行一个保存点以确保所有的数据都保存,并且你必须执行数据备份,否则你不能恢复这些数据。
<enable_delta_log> ::= DISABLE DELTA LOG
DISABLE DELTA LOG:禁用表日志记录。如果禁用,不会记录该表的日志。当完成一个保存点对于该表的修改只会写到数据域,这会导致当索引服务器终止时,提
交的事务丢失。
仅在初次加载中使用该命令!
<enable_delta_log> ::= ENABLE AUTOMERGE
指导合并管理器处理表。
<enable_delta_log> ::= DISABLE AUTOMERGE
DISABLE AUTOMERGE:指导合并管理器忽略该表。
例子:
表 t 已创建,列 b 的默认值设为 10。
CREATETABLE t (a INT, b INT);
ALTERTABLE t ALTER (b INTDEFAULT 10);
列 c 添加至表 t。
ALTERTABLE t ADD (c NVARCHAR(10) DEFAULT‘NCHAR‘);
创建表 t 的主键约束 prim_key。
ALTERTABLE t ADDCONSTRAINT prim_key PRIMARYKEY (a, b);
表 t 类型转换为列式 (COLUMN)。
ALTERTABLE t COLUMN;
设置列 b 和 c 的预载标记
ALTERTABLE t PRELOAD (b, c);
表 t 使用 RANGE 分区,并且添加另一分区。
ALTERTABLE t PARTITIONBY RANGE (a) (PARTITIONVALUE = 1, PARTITION OTHERS);
ALTERTABLE t ADDPARTITION 2 <= VALUES < 10;
表 t 的会话类型改为 HISTORY
ALTERTABLE t CREATEHISTORY;
禁用表 t 的日志记录。
ALTERTABLE t DISABLEDELTALOG;
语法:
CREATE AUDIT POLICY <policy_name> AUDITING <audit_status_clause> <audit_action_list> LEVEL <audit_level>
语法元素:
<audit_status_clause> ::= SUCCESSFUL | UNSUCCESSFUL | ALL
<audit_action_list> ::= <audit_action_name>[,<audit_action_name>]...
<audit_action_name> ::=GRANT PRIVILEGE | REVOKE PRIVILEGE| GRANT STRUCTURED PRIVILEGE | REVOKE STRUCTURED PRIVILEGE| GRANT ROLE | REVOKE ROLE| GRANT
ANY | REVOKE ANY| CREATE USER | DROP USER| CREATE ROLE | DROP ROLE| ENABLE AUDIT POLICY | DISABLE AUDIT POLICY| CREATE STRUCTURED PRIVILEGE| DROP STRUCTURED PRIVILEGE| ALTER STRUCTURED PRIVILEGE| CONNECT| SYSTEM CONFIGURATION CHANGE| SET SYSTEM LICENSE| UNSET SYSTEM LICENSE
<audit_level> ::=EMERGENCY| ALERT| CRITICAL| WARNING| INFO
描述:
CREATE AUDIT POLICY 语句创建新的审计策略。该审计策略可以稍后启动,并将导致指定的审计活动发生的审计。
只有拥有系统权限 AUDIT ADMIN 用户才可以新建审计策略。
指定的审计策略名必须和已有的审计策略名不同。
审计策略定义将被审计的审计活动。现有的审计策略需要被激活,从而进行审计。
<audit_status_clause>定义, 成功或不成功或执行指定的审计活动进行审核。
以下的审计活动是可供使用的。它们被分在不同的组里。一组审计活动可以组合成一个审计策略,不同组的审计行动不能组合成审计策略。
GRANT PRIVILEGE 1
审计授予用户或角色的权限
REVOKE PRIVILEGE 1
审计撤销用户或角色的权限
GRANT STRUCTURED PRIVILEGE 1
审计授予用户的结构/分析权限
REVOKE STRUCTURED PRIVILEGE 1
审计撤销用户的结构/分析权限
GRANT ROLE 1
审计授予用户或角色的角色
REVOKE ROLE 1
审计撤销用户或角色的角色
GRANT ANY 1
审计授予用户或角色的权限、结构/分析权限或角色
REVOKE ANY 1
审计撤销用户或角色的权限、结构/分析权限或角色
CREATE USER 2
审计用户创建
DROP USER
2 审计用户删除
CREATE ROLE 2
审计角色创建
DROP ROLE 2
审计角色删除
CONNECT 3
审计连接到数据库的用户
SYSTEM CONFIGURATION CHANGE 4 审计系统配置的更改(e.g.
INIFILE)
ENABLE AUDIT POLICY 5
审计审核策略激活
DISABLE AUDIT POLICY
5 审计审核策略停用
CREATE STRUCTURED PRIVILEGE
6 审计结构化/分析权限创建
DROP STRUCTURED PRIVILEGE 6
审计结构化/
ALTER STRUCTURED
PRIVILEGE 6
审计结构化/分析权限更改
SET SYSTEM LICENSE 7
审计许可证安装
UNSET SYSTEM LICENSE 7
审计许可证删除
每一个审计分配分配至审计级别,可能的值按照重要性递减有:EMERGENCY, ALERT, CRITICAL, WARNING, INFO
为了使得审计活动发生,审计策略必须建立并启动, global_auditing_state(见下文)必须设置为true。
配置参数:
目前,审计的配置参数存储在 global.ini,部分审计配置如下:
global_auditing_state ( ‘true‘ / ‘false‘ )激活/关闭所有审计,无论有多少审计策略可用和启动。默认为 false,代表没有审计会发生。
default_audit_trail_type ( ‘SYSLOGPROTOCOL‘ / ‘CSVTEXTFILE‘ )定义如何存储审计结果。
SYSLOGPROTOCOL 为默认值。
CSVTEXTFILE 应只用于测试目的。
default_audit_trail_path 指定 存储文件的位置, CSVTEXTFILE 已经选定的情况下。
对于所有的配置参数,可以在视图 M_INIFILE_CONTENTS 中选择,如果当前用户具有这样做所需的权限。但是目前这些参数只有在被显式设置后才可见。这意味着,它们将对新安装的数据库实例不可见。
系统和监控视图
AUDIT_POLICY:显式所有审计策略和其状态
M_INIFILE_CONTENTS:显示审计有关的配置参数
只有数据库用户具有 CATALOG READ, DATA ADMIN 或 INIFILE ADMIN 权限可以在视图M_INIFILE_CONTENTS 查看任意信息,对于其他用户,该视图为空。
例子
新建的名为 priv_audit 的审计策略将审计有关成功授予和撤销权限和角色的命令,该审计策略有中等审计级别 CRITICAL.。
该策略必须显式启动(见 alter_audit_policy),使得审计策略的审计发生。
CREATEAUDIT POLICY priv_audit AUDITING SUCCESSFUL GRANT PRIVILEGE, REVOKE PRIVILEGE, GRANT ROLE, REVOKE ROLE LEVEL CRITICAL;
语法:
CREATE FULLTEXT INDEX <index_name> ON <tableref> ‘(‘ <column_name> ‘)‘ [<fulltext_parameter_list>]
定义全文索引名:
<fulltext_parameter_list> ::= <fulltext_parameter> [, ...]
<fulltext_parameter> ::= LANGUAGE COLUMN <column_name>
| LANGUAGE DETECTION ‘(‘ <string_literal_list> ‘)‘
| MIME TYPE COLUMN <column_name>
| <change_tracking_elem>
| FUZZY SEARCH INDEX <on_off>
| PHRASE INDEX RATIO <on_off>
| CONFIGURATION <string_literal>
| SEARCH ONLY <on_off>
| FAST PREPROCESS <on_off>
<on_off> ::= ON | OFF
LANGUAGE COLUMN:指定文件语言的列
LANGUAGE DETECTION:语言检测设置的语言集合。
MIME TYPE COLUMN:指定文件 mime-type 的列
FUZZY SEARCH INDEX:指定是否使用模糊搜索
PHRASE INDEX RATIO:指定短语索引比率的百分比,值必须为 0.0 和 1.0 之间。
CONFIGURATION:自定义配置文件的文本分析路径。
SEARCH ONLY:如果设为 ON,将不存储原始文件内容。
FAST PREPROCESS:如果设为 ON,将使用快速处理,例如语言搜索将不可用。
<change_tracking_elem> ::= SYNC[HRONOUS]| ASYNC[HRONOUS] [FLUSH [QUEUE]<flush_queue_elem>]
SYNC:指定是否创建同步全文索引
ASYNC:指定是否创建异步全文索引
<flush_queue_elem> ::= EVERY <integer_literal> MINUTES| AFTER <integer_literal> DOCUMENTS| EVERY <integer_literal> MINUTES OR AFTER <integer_literal> DOCUMENTS
指定如果使用异步索引,更新全文索引的时机。
描述:
CREATE FULLTEXT INDEX 语句对给定表创建显式全文索引。
例子:
CREATE FULLTEXT INDEX i1 ON A(C) FUZZY SEARCH INDEXOFF
SYNC
LANGUAGE DETECTION (‘EN‘,‘DE‘,‘KR‘)
上面的例子在表 A 的列 C 创建名为‘i1’的全文索引,未使用模糊搜索索引, 语言检测设置的语言集合由‘EN‘,‘DE‘ 和 ‘KR‘组成。
语法:
CREATE [UNIQUE] [BTREE | CPBTREE] INDEX [<schema_name>.]<index_name> ON <table_name>(<column_name_order>, ...) [ASC | DESC]
语法元素:
<column_name_order> ::= <column_name> [ASC | DESC]
UNIQUE:用来创建唯一性索引。当创建索引和记录添加到表中将进行重复检查。
BTREE | CPBTREE:用来选择使用的索引类型。当列的数据类型为字符串、二进制字符串、十进制数或者约束是一个组合键,或非唯一键,默认的索引类型为 CPBTREE,否则使用 BTREE。
为了使用 B+-树索引,必须使用 BTREE 关键字;对于 CPB+-树索引,需使用 CPBTREE 关键字。
B+-树是维护排序后的数据进行高效的插入、删除和搜索记录的树。
CPB+-树表示压缩前缀 B+-树,是基于 pkB-tree 树。 CPB+树是一个非常小的索引,因为它使用“部分键”,只是索引节点全部键的一部分。对于更大的键, CPB+-树展现出比 B+-树更好的性能。
如果省略了索引类型, SAP HANA 数据库将考虑列的数据类型选择合适的索引。
ASC | DESC:指定以递增或递减方式创建索引。
这些关键字只能在 btree 索引使用,并且对每一列只能使用一次。
描述:
CREATE INDEX 语句创建索引。
例子:
表 t 创建后,以递增方式对表 t 的 b 列创建 CBPTREE 索引 idx。
CREATETABLE t (a INT, b NVARCHAR(10), c NVARCHAR(20));
CREATEINDEX idx ON t(b);
以递增方式对表 t 的 a 列创建 CBPTREE 索引 idx,以递减顺序对 b 列创建:
CREATE CPBTREE INDEX idx1 ON t(a, b DESC);
以递减方式对表 t 的 a 列和 c 列创建 CPBTREE 索引 idx2。
CREATEINDEX idx2 ON t(a, c) DESC;
以递增顺序对表 t 的 b 列和 c 列创建唯一性 CPBTREE 索引 idx3。
CREATEUNIQUEINDEX idx3 ON t(b, c);
以递增顺序对表 t 的 a 列创建唯一性 BTREE 索引 idx4。
CREATEUNIQUEINDEX idx4 ON t(a);
语法:
CREATE SCHEMA <schema_name> [OWNED BY <user_name>]
OWNED BY:指定Schema所有者名字。如果省略,当前用户将为Schema所有者。
描述:
CREATE SCHEMA 语句在当前数据库创建Schema。
例子:
CREATESCHEMA my_schema OWNED BYsystem;
语法:
CREATE SEQUENCE <sequence_name> [<common_sequence_parameter_list>] [RESET BY <subquery>]
语法元素:
<common_sequence_parameter_list> ::= <common_sequence_parameter>, ...
<common_sequence_parameter> ::= START WITH n | <basic_sequence_parameter>
<basic_sequence_parameter> ::= INCREMENT BY n| MAXVALUE n| NO MAXVALUE| MINVALUE n| NO MINVALUE| CYCLE| NO CYCLE
INCREMENT BY:定义上个分配值递增到下一个序列值的量(即递增递减间隔值),默认值为 1。指定一个负的值来生成一个递减的序列。 INCREMENT BY 值为 0,将返回错误。
START WITH:定义起始序列值。如果未定义 START WITH 子句值,递增序列将使用 MINVALUE,递减序列将使用MAXVALUE。
MAXVALUE:定义序列可生成的最大数值,必须为 0 至 4611686018427387903 之间。
NO MAXVALUE:使用 NO MAXVALUE 指令,递增序列的最大值将为 4611686018427387903,递减序列的最大值为-1。
MINVALUE:定义序列可生成的最小数值,必须为 0 至 4611686018427387903 之间。
NO MINVALUE:使用 NO MINVALUE 指令,递增序列的最小值将为 1,递减序列的最小值为-4611686018427387903。
CYCLE:使用 CYCLE 指令,序列在到达最大值或最小值后将会重新开始。
NO CYCLE:使用 NO CYCLE 指令,序列在到达最大值或最小值后将不会重新开始。
RESET BY:系统重启期间,系统自动执行 RESET BY 语句,并且将用 RESET BY 子查询确定的值重启序列。
如果未指定 RESET BY,序列值将持久地存储在数据库中。在数据库重启过程中,序列的下一个值将由已保存的序列值生成。
描述:
CREATE SEQUENCE 语句用来创建序列。
序列用来为多个用户生成唯一整数。 CURRVAL 用来获取序列的当前值,NEXTVAL 则用来获取序列的下一个值。 CURRVAL 只有在会话中调用 NEXTVAL 才有效。
例子:
例子 1:
序列 seq 已创建,使用 CURRVAL 和 NEXTVAL 从序列中读取值。
CREATESEQUENCE seq START WITH 11;
NEXTVAL 返回 11:
SELECT seq.NEXTVAL FROM DUMMY;--11
CURRVAL 返回 11:
SELECT seq.CURRVAL FROM DUMMY;--11
例子 2:
如果序列用来在表 R 的 A 列上创建唯一键,在数据库重启后,通过自动分配列 A 的最大值到序列,创建一个唯一键值,语句如下:
CREATETABLE r (a INT);
CREATESEQUENCE s RESETBYSELECTIFNULL(MAX(a), 0) + 1 FROM r;
SELECT s.NEXTVAL FROM DUMMY;--1
语法:
CREATE [PUBLIC] SYNONYM <synonym_name> FOR <object_name>
语法元素:
<object_name> ::= <table_name>| <view_name>| <procedure_name>| <sequence_name>
描述:
CREATE SYNONYM 为表、视图、存储过程或者序列创建备用名称。
你可以使用同义词把函数和存储过程重新指向不同的表、视图或者序列,而不需要重写函数或者过程。
可选项 PUBLIC 允许创建公用同义词。任何用户可以访问公用同义词,但只有拥有基本对象合适权限的用户可以访问基本对象。
例子:
CREATESYNONYM t_synonym FOR t;
语法:
CREATE [<table_type>] TABLE [<schema_name>.]<table_name> <table_contents_source>[<logging_option> | <auto_merge_option> | <partition_clause> | <location_clause>]
语法元素:
<table_type> ::= COLUMN| ROW| HISTORY COLUMN| GLOBAL TEMPORARY| LOCAL TEMPORARY
COLUMN, ROW:如果大多数的访问是通过大量元组,而只选择少数几个属性,应使用基于列的存储。如果大多数访问选择一些记录的全部属性,使用基于行的存储是最好的。 SAP HANA 数据库使用组合启用两种方式的的存储和解释。你可以为每张表指定组织类型,默认值为 ROW。
HISTORY COLUMN:利用特殊的事务会话类型称为’HISTORY’创建表。具有会话类型’HISTORY’的表支持“时间旅行”, 对历史状态的数据库查询的执行是可能的。
时间旅行可以以如下方式完成:
会话级别时间旅行:
SET HISTORY SESSION TO UTCTIMESTAMP = <utc_timestamp>
SET HISTORY SESSION TO COMMIT ID = <commit_id>
<utc_timestamp> ::= <string_literal>
<commit_id> ::= <unsigned_integer>
数据库会话可以设置回到一个特定时间点。该语句的 COMMIT ID 变量接受 commitid 作为参数。commitid 参数的值必须存在系统表 SYS.TRANSACTION_HISTORY 的 COMMIT_ID 列,否则将抛出异常。 COMMIT_ID 在使用用户定义的快照时是有用的。用户自定义的快照可以通过存储在提交阶段分配至事务的 commitid 来获得。 Commitid 可以通过在事务提交后执行以下查询来读取:
SELECT LAST_COMMIT_ID FROM M_TRANSACTIONS WHERE CONNECTION_ID = CURRENT_CONNECTION;
该语句的 TIMESTAMP 变量接受时间戳作为参数。在系统内部,时间戳用来在系统表SYS.TRANSACTION_HISTORY,commit_time 接近给定的时间戳的地方,查询一对(commit_time,commit_id),准确的说,选择最大 COMMIT_TIME 小于等于给定时间戳的对;如果没有找到这样的对,将会抛出异常。然后会话将使用 COMMIT_ID 变量确定的 commit-id 恢复。 要终止恢复会话切换到当前会话中,必须在数据库连接上执行明确的 COMMIT 或 ROLLBACK。
语句级别时间旅行:
<subquery> AS OF UTCTIMESTAMP <utc_timestamp>
<subquery> AS OF COMMIT ID <commit_id>
为了能使 commitid 与提交时间关联,需维护系统表 SYS.TRANSACTION_HISTORY,存储每个为历史表提交数据的事务的额外信息。有关设置会话级别时间旅行的详细信息,请参阅 SET HISTORY SESSION,关于<subquery>的信息,请参阅 Subquery。
注意:
当会话恢复时,自动提交必须关闭(否则会抛出包含相应错误消息的异常)。
非历史表在恢复会话中总显示其当前快照。
只有数据查询语句(select)可以在恢复会话中使用。
历史表必须有主键。
会话类型可以通过系统表 SYS.TABLES 的 SESSION_TYPE 列检查。
GLOBAL TEMPORARY:
表定义全局可见,但数据只在当前会话中可见。表在会话结束后截断。
全局临时表的元数据是持久的,表示该元数据一直存在直到表被删除,元数据在会话间共享。临时表中的数据是会话特定的,代表只有全局临时表的所有者才允许插入、读取、删除数据,存在于会话持续期间,并且当会话结束时,全局临时表中的数据会自动删除。全局临时表只有当表中没有任何数据才能被删除。全局临时表支持的操作:
1. Create without a primary key
2. Rename table
3. Rename column
4. Truncate
5. Drop
6. Create or Drop view on top of global temporary table
7. Create synonym
8. Select
9. Select into or Insert
10. Delete
11. Update
12. Upsert or Replace
LOCAL TEMPORARY:
表的定义和数据只在当前会话可见,该表在会话结束时被截断。
元数据在会话间共享,并且是会话特定的,代表只有本地临时表的所有者才允许查看。临时表中的数据是会话特定的,代表只有本地临时表的所有者才允许插入、读取、删除数据,存在于会话持续期间,并且当会话结束时,本地临时表中的数据会自动删除。
本地临时表支持的操作:
1. Create without a primary key
2. Truncate
3. Drop
4. Select
5. Select into or Insert
6. Delete
7. Update
8. Upsert or Replace
<table_contents_source> ::= (<table_element>, ...)| <like_table_clause> [WITH [NO] DATA]| [(<column_name>, ...)] <as_table_subquery> [WITH [NO] DATA]]
<table_element> ::= <column_definition> [<column_constraint>]| <table_constraint> (<column_name>, ... )
<column_definition> ::= <column_name> <data_type> [<column_store_data_type>] [<ddic_data_type>][DEFAULT <default_value>] [GENERATED ALWAYS AS
<expression>]
<data_type> ::= DATE | TIME | SECONDDATE | TIMESTAMP | TINYINT | SMALLINT | INTEGER | BIGINT |SMALLDECIMAL | DECIMAL | REAL | DOUBLE|
VARCHAR | NVARCHAR | ALPHANUM | SHORTTEXT |VARBINARY |BLOB | CLOB | NCLOB | TEXT
<column_store_data_type> ::= S_ALPHANUM | CS_INT | CS_FIXED | CS_FLOAT| CS_DOUBLE |CS_DECIMAL_FLOAT | CS_FIXED(p-s, s) | CS_SDFLOAT|
CS_STRING | CS_UNITEDECFLOAT | CS_DATE |CS_TIME | CS_FIXEDSTRING | CS_RAW | CS_DAYDATE | CS_SECONDTIME | CS_LONGDATE |CS_SECONDDATE
<ddic_data_type> ::= DDIC_ACCP | DDIC_ALNM | DDIC_CHAR | DDIC_CDAY | DDIC_CLNT | DDIC_CUKY| DDIC_CURR | DDIC_D16D | DDIC_D34D | DIC_D16R
| DDIC_D34R | DDIC_D16S | DDIC_D34S| DDIC_DATS | DDIC_DAY | DDIC_DEC | DDIC_FLTP | DDIC_GUID | DDIC_INT1 | DDIC_INT2 | DDIC_INT4| DDIC_INT8 | DDIC_LANG | DDIC_LCHR | DDIC_MIN | DDIC_MON| DDIC_LRAW | DDIC_NUMC |DDIC_PREC |DDIC_QUAN | DDIC_RAW | DDIC_RSTR | DDIC_SEC | DDIC_SRST | DDIC_SSTR |DDIC_STRG | DDIC_STXT | DDIC_TIMS | DDIC_UNIT| DDIC_UTCM | DDIC_UTCL | DDIC_UTCS |DDIC_TEXT | DDIC_VARC | DDIC_WEEK
<default_value> ::= NULL | <string_literal> | <signed_numeric_literal>| <unsigned_numeric_literal>
DEFAULT:DEFAULT 定义了 INSERT 语句没有为列提供值情况下,默认分配的值。
GENERATED ALWAYS AS:指定在运行时生成的列值的表达式。
<column_constraint> ::= NULL| NOT NULL| UNIQUE [BTREE | CPBTREE]| PRIMARY KEY [BTREE | CPBTREE]
NULL | NOT NULL:NOT NULL 禁止列的值为 NULL。如果指定了 NULL,将不被认为是常量,其表示一列可能含有空值,默认为 NULL。
UNIQUE:指定为唯一键的列。一个唯一的复合键指定多个列作为唯一键。有了 unique 约束,多行不能在同一列中具有相同的值。
PRIMARY KEY:主键约束是 NOT NULL 约束和 UNIQUE 约束的组合,其禁止多行在同一列中具有相同的值。
BTREE | CPBTREE:指定索引类型。当列的数据类型为字符串、二进制字符串、十进制数或者约束是一个组合键,或非唯一键,默认的索引类型为 PBTREE,
否则使用 BTREE。为了使用 B+-树索引,必须使用 BTREE 关键字;对于 CPB+-树索引,需使用 CPBTREE 关键字。B+-树是维护排序后的数据进行高效的插入、删除和搜索记录的树。CPB+-树表示压缩前缀 B+-树,是基于 pkB-tree 树。 CPB+树是一个非常小的索引,因为它使用“部分键”,只是索引节点全部键的一部分。对于更大的键, CPB+-树展现出比 B+-树更好的性能。如果省略了索引类型, SAP HANA 数据库将考虑列的数据类型选择合适的索引。
<table_constraint> ::= UNIQUE [BTREE | CPBTREE]| PRIMARY KEY [BTREE | CPBTREE]
定义了表约束可以使用在表的一列或者多列上。
<like_table_clause> ::= LIKE <table_name>
创建与 like_table_name 定义相同的表。表中所有列的定义和默认值拷贝自 like_table_name。当提供了可选项 WITH DATA,数据将从指定的表填充,不过,默认值为 WITH NO DATA。
<as_table_subquery> ::= AS ‘(<subquery>)
创建表并且用<subquery>计算的数据填充。使用该子句只拷贝 NOT NULL 约束。如果指定了column_names,该指定的 column_names 将覆盖<subquery>中的列名。WITH [NO] DATA 指定数据拷贝自<subquery> 或 <like_table_clause>。
<logging_option> ::= LOGGING| NO LOGGING [RETENTION <retention_period>]
<retention_period> ::= <unsigned_integer>
LOGGING | NO LOGGING:LOGGING (默认值)指定激活记录表日志。NO LOGGING 指定停用记录表日志。一张 NO LOGGING 表意味表定义是持久的且全局可见的,数据则为临时和全局的。
RETENTION:指定以秒为单位,NO LOGGING 列式表的保留时间。在指定的保留期限已过,如果使用物理内存的主机达到 80%,上述表将被删除。
<auto_merge_option> ::= AUTO MERGE | NO AUTO MERGE
AUTO MERGE | NO AUTO MERGE:AUTO MERGE (默认值)指定触发自动增量合并。
<partition_clause> ::= PARTITION BY <hash_partition> [, <range_partition> | , <hash_partition>]| PARTITION BY <range_partition>| PARTITION BY <roundrobin_partition>
[,<range_partition>]
<hash_partition> ::= HASH (<partition_expression> [, ...]) PARTITIONS {<num_partitions> |GET_NUM_SERVERS()}
<range_partition> ::= RANGE (<partition_expression>) (<range_spec>, ...)
<roundrobin_partition> ::= ROUNDROBIN PARTITIONS {<num_partitions> | GET_NUM_SERVERS()} [,<range_partition>]
<range_spec> ::= {<from_to_spec> | <single_spec>} [, ...] [, PARTITION OTHERS]
<from_to_spec> ::= PARTITION <lower_value> <= VALUES < <upper_value>
<single_spec> ::= PARTITION VALUE <target_value>
<lower_value> ::= <string_literal> | <numeric_literal>
<upper_value> ::= <string_literal> | <numeric_literal>
<target_value> ::= <string_literal> | <numeric_literal>
<partition_expression> ::= <column_name> | YEAR(<column_name>) | MONTH(<column_name>)
<num_partitions> ::= <unsigned_integer>
GET_NUM_SERVERS()函数返回服务器数量。
PARTITION OTHERS 表示分区定义中未指定的其余值成为一个分区。
确定分区创建所在的索引服务器是可能的。如果你指定了 LOCATION,在这些实例中循环创建分区。列表中的重复项将被移除。如果你在分区定义中精确指定实例数为分区数,则每个分区将分配至列表中各自实例。所有索引列表中的服务器必须属于同一个实例。如果指定了 no location,将随机创建分区。如果分区数与服务器数匹配-例如使用
GET_NUM_SERVERS()-可以确保多个 CREATE TABLE 调用以同样的方式分配分区。对于多级别分区的情况,其适用于第一级的分区数。这个机制是很有用的,如果创建彼此语义相关的多张表。
<location_clause> ::= AT [LOCATION] {‘<host>:<port>‘ | (‘<host>:<port>‘, ...)}
AT LOCATION:表可以创建在 host:port 指定的位置,位置列表可以在创建分配至多个实例的分区表时定义。当位置列表没有提供<partition_clause>,表将创建至指定的第一个位置中。如果没有提供位置信息,表将自动分配到一个节点中。此选项可用于在分布式环境中的行存储和列存储表
描述:
CREATE TABLE 创建一张表。表中未填充数据,除了当<as_table_subquery> 或 <like_table_clause>和WITH DATA 可选项一起使用。
例子:
创建了表 A,整数列 A 和 B。列 A 具有主键约束。
CREATETABLE A (A INTPRIMARYKEY, B INT);
创建了分区表 P1,日期列 U。列 U 具有主键约束并且作为 RANGE 分区列使用。
CREATECOLUMNTABLE P1 (U DATEPRIMARYKEY) PARTITIONBY RANGE (U) (PARTITION‘2010-02-03‘<= VALUES < ‘2011-01-01‘, PARTITIONVALUE = ‘2011-05-01‘);
创建了分区表 P2,整数列 I,J 和 K。列 I,J 组成键约束,并且作为哈希分区列使用。列 K 则为子哈希分区列。
CREATECOLUMNTABLE P2 (I INT, J INT, K INT, PRIMARYKEY(I, J)) PARTITIONBY HASH (I, J) PARTITIONS 2, HASH (K) PARTITIONS 2;
创建表 C1,与表 A 的定义相同,记录也相同。
CREATECOLUMNTABLE C1 LIKE A WITH DATA;
创建表 C2,与表 A 的列数据类型和 NOT NULL 约束相同。表 C2 没有任何数据。
CREATETABLE C2 AS (SELECT * FROM A) WITHNO DATA;
语法:
CREATE TRIGGER <trigger_name> <trigger_action_time> <trigger_event> ON <subject_table_name> [REFERENCING <transition_list>][<for_each_row>]
BEGIN
[<trigger_decl_list>]
[<proc_handler_list>]
<trigger_stmt_list>
END
语法元素:
<trigger_name> ::= <identifier> 你创建的触发器名称。
<subject_table_name> ::= <identifier> 你创建的触发器所在表的名称。
<trigger_action_time> ::= BEFORE | AFTER 指定触发动作发生的 时间。
BEFORE:操作主题表之前执行触发。
AFTER:操作主题表之后执行触发。
<trigger_event> ::= INSERT | DELETE | UPDATE 定义激活触发器活动的数据修改命令
<transition_list> ::= <transition> | <transition_list> , <transition>
<transition> ::= <trigger_transition_old_or_new> <trigger_transition_var_or_table> <trans_var_name>|<trigger_transition_old_or_new> <trigger_transition_var_or_table> AS <trans_var_name>
当声明了 触发器转变变量,触发器可以访问 DML 正在修改的记录。
当执行了行级别触发器, <trans_var_name>.<column_name>代表触发器正在修改的记录的相应列。
这里, <column_name>为主题表的列名。参见转换变量的例子。
<trigger_transition_old_or_new> ::= OLD | NEW
<trigger_transition_var_or_table> ::= ROW
OLD
你可以访问触发器 DML 的旧记录,取而代之的是更新的旧记录或删除的旧记录。
UPDATE 触发器和 DELETE 触发器可以有 OLD ROW 事务变量。
NEW
你可以访问触发器 DML 的新记录,取而代之的是插入的新记录或更新的新记录。
UPDATE 触发器和 DELETE 触发器可以有 NEW ROW 事务变量。
只支持事务变量。
事务表不被支持。
如果你将’TABLE’作为<trigger_transition_var_or_table>,你将看到不支持功能错误。
<for_each_row> ::= FOR EACH ROW
触发器将以逐行方式调用。
默认模式为执行行级别触发器,没有 FOR EACH ROW 语法。
目前,逐语句触发不被支持。
<trigger_decl_list> ::= DECLARE <trigger_decl>| <trigger_decl_list> DECLARE <trigger_decl>
<trigger_decl> ::= <trigger_var_decl> | <trigger_condition_decl>
<trigger_var_decl> ::= <var_name> CONSTANT <data_type> [<not_null>] [<trigger_default_assign>] ;| <var_name> <data_type> [NOT NULL] [<trigger_default_assign>] ;
<data_type> ::= DATE | TIME | SECONDDATE | TIMESTAMP | TINYINT | SMALLINT | INTEGER| BIGINT |SMALLDECIMAL | DECIMAL | REAL | DOUBLE| VARCHAR | NVARCHAR | ALPHANUM | SHORTTEXT|VARBINARY | BLOB | CLOB| NCLOB | TEXT
<trigger_default_assign> ::= DEFAULT <expression>| := <expression>
<trigger_condition_decl> ::= <condition_name> CONDITION ;| <condition_name> CONDITION FOR <sql_error_code> ;
<sql_error_code> ::= SQL_ERROR_CODE <int_const>
trigger_decl_list
你可以声明触发器变量或者条件。
声明的变量可以在标量赋值中使用或者在 SQL 语句触发中引用。
声明的条件名可以在异常处理中引用。
CONSTANT
当指定了 CONSTANT 关键字,你不可以在触发器执行时修改变量。
<proc_handler_list> ::= <proc_handler>| <proc_handler_list> <proc_handler>
<proc_handler> ::= DECLARE EXIT HANDLER FOR <proc_condition_value_list> <trigger_stmt>
<proc_condition_value_list> ::= <proc_condition_value>| <proc_condition_value_list> , <proc_condition_value>
<proc_condition_value>
::= SQLEXCEPTION
| SQLWARNING
| <sql_error_code>
| <condition_name>
异常处理可以声明捕捉已存的 SQL 异常,特定的错误代码或者条件变量声明的条件名称。
<trigger_stmt_list> ::= <trigger_stmt>| <trigger_stmt_list>
<trigger_stmt>
<trigger_stmt> ::= <proc_block>
| <proc_assign>
| <proc_if>
| <proc_loop>
| <proc_while>
| <proc_for>
| <proc_foreach>
| <proc_signal>
| <proc_resignal>
| <trigger_sql>
触发器主体的语法是过程体的语法的一部分。
参见 SAP HANA Database SQLScript guide 中的 create procedure 定义。
触发器主体的语法遵循过程体的语法,即嵌套块(proc_block),标量变量分配(proc_assign), if 块
(proc_if),, loop 块(proc_loop), for 块(proc_for), for each 块(proc_foreach), exception
signal(proc_signal), exception resignal(proc_resignal),和 sql 语句(proc_sql)。
<proc_block> ::= BEGIN
[<trigger_decl_list>]
[<proc_handler_list>]
<trigger_stmt_list>
END ;
你可以以嵌套方式添加另外的‘BEGIN ... END;‘块。
<proc_assign> ::= <var_name> := <expression> ;
var_name 为变量名,应该事先声明。
<proc_if> ::= IF <condition> THEN <trigger_stmt_list>
[<proc_elsif_list>]
[<proc_else>]
END IF ;
<proc_elsif_list> ::= ELSEIF <condition> THEN
<trigger_stmt_list>
<proc_else> ::=
ELSE <trigger_stmt_list>
关于 condition 的说明,参见 SELECT 的<condition>。
你可以使用 IF ... THEN ... ELSEIF... END IF 控制执行流程与条件。
<proc_loop> ::= LOOP <trigger_stmt_list> END LOOP ;
<proc_while> ::= WHILE <condition> DO <trigger_stmt_list> END
WHILE ;
<proc_for> ::= FOR <column_name> IN [<reverse>]
<expression> <DDOT_OP> <expression>
DO <trigger_stmt_list>
END FOR ;
<column_name> ::= <identifier>
<reverse> ::= REVERSE
<DDOT_OP> ::= ..
<proc_foreach> ::= FOR <column_name> AS <column_name>
[<open_param_list>] DO
<trigger_stmt_list>
END FOR ;
<open_param_list> ::= ( <expr_list> )
<expr_list> ::= <expression> | <expr_list> ,
<expression>
<proc_signal> ::= SIGNAL <signal_value> [<set_signal_info>] ;
<proc_resignal> ::= RESIGNAL [<signal_value>]
[<set_signal_info>] ;
<signal_value> ::= <signal_name> | <sql_error_code>
<signal_name> ::= <identifier>
<set_signal_info> ::= SET MESSEGE_TEXT = ‘<message_string>‘
<message_string> ::= <identifier>
SET MESSEGE_TEXT
如果你为自己的消息设置 SET MESSEGE_TEXT,当触发器执行时指定的错误被抛出,消息传递给用
户。
SIGNAL 语句显式抛出一个异常。
用户定义的范围( 10000?19999)将被允许发行错误代码。
RESIGNAL 语句在异常处理中对活动语句抛出异常。
如果没有指定错误代码, RESIGNAL 将抛出已捕捉的异常。
<trigger_sql> ::=
<select_into_stmt>
| <insert_stmt>
| <delete_stmt>
| <update_stmt>
| <replace_stmt>
| <upsert_stmt>
对于 insert_stmt 的详情,参见 INSERT。
对于 delete_stmt 的详情,参见 DELETE。
对于 update_stmt 的详情,参见 UPDATE。
对于 replace_stmt 和 upsert_stmt 的详情,参见 REPLACE | UPSERT。
<select_into_stmt> ::= SELECT <select_list> INTO
<var_name_list>
<from_clause >
[<where_clause>]
[<group_by_clause>]
[<having_clause>]
[{<set_operator> <subquery>, ... }]
[<order_by_clause>]
[<limit>]
<var_name_list> ::= <var_name> | <var_name_list> ,
<var_name>
<var_name> ::= <identifier>
关于 select_list, from_clause, where_clause,
group_by_clause, having_clause,set_operator, subquery,
order_by_clause, limit 的详情,参见 SELECT。
var_name 是预先声明的标量变量名。
你可以分配选中项至标量变量中。
描述:
CREATE TRIGGER 语句创建触发器。
触发器是一种特殊的存储过程,在对表发生事件时自动执行。
CREATE TRIGGER 命令定义一组语句,当给定操作(INSERT/UPDATE/DELETE)发生在给定对象(主题表)
上执行。
只有对于给定的<subject_table_name>拥有 TRIGGER 权限的数据库用户允许创建表的触发器。
当前触发器限制描述如下:
l不支持 INSTEAD_OF 触发器。
l访问触发器定义的主题表在触发器主体中是不允许的,这代表对于触发器所在的表的任何
insert/update/delete/replace/select
l只支持行级别触发器,不支持语句级别触发器。行级别触发器表示触发活动只有在每次行改
变时执行。语句级别触发器代表触发活动在每次语句执行时运行。语法‘FOR EACH ROW’表示
行式执行触发,为默认模式;即时没有指定‘FOR EACH ROW’,仍然为行级别触发器。
l不支持事务表(OLD/NEW TABLE)。当触发 SQL 语句想要引用正在被触发器触发事件如
insert/update/delete 修改的数据,事务变量/表将是触发器主体中 SQL 语句访问新数据和旧数
据的方式。事务变量只在行级别触发器中使用,而事务表则在语句级别触发器中使用。
l不支持从节点到多个主机或表中的分区表上执行触发器。
l表只能为每个 DML 操作有一个触发器,可能是插入触发器、更新触发器和删除触发器,并且
它们三个可以一起激活。
因此,一张表总共最多有三个触发器。
l不支持的触发器动作(而存储过程支持):
resultset assignment(select resultset assignment to tabletype),
exit/continue command(execution flow control),
cursor open/fetch/close(get each record data of search result by cursor and
access record in loop),
procedure call(call another proecedure),
dynomic sql execution(build SQL statements dynamically at runtime of
SQLScript),
return(end SQL statement execution)
系统和监控视图:
TRIGGER 为触发器的系统视图:
系统视图 TRIGGER 显示:
SCHEMA_NAME, TRIGGER_NAME, TRIGGER_OID, OWNER_NAME,
OWNER_OID,SUBJECT_TABLE_SCHEMA,SUBJECT_TABLE_NAME, TRIGGER_ACTION_TIME,
TRIGGER_EVENT, TRIGGERED_ACTION_LEVEL,DEFINITION
例子:
你先需要触发器定义的表:
CREATETABLE
TARGET ( A INT);
你也需要表触发访问和修改:
CREATETABLE
SAMPLE ( A INT);
以下为创建触发器的例子:
CREATE TRIGGER TEST_TRIGGER AFTERINSERTON TARGET FOR EACH ROW
BEGIN
DECLARE SAMPLE_COUNT INT;
SELECTCOUNT(*) INTO SAMPLE_COUNT FROM SAMPLE;
IF :SAMPLE_COUNT = 0 THEN
INSERTINTO SAMPLE VALUES(5);
ELSEIF :SAMPLE_COUNT = 1 THEN
INSERTINTO SAMPLE VALUES(6);
ENDIF;
END;
触发器 TEST_TRIGGER 将在任意记录插入至 TARGET 表后执行。由于在第一次插入中,表 SAMPLE 记录数为 0,触发器 TEST_TRIGGER 将插入 5 至表中。
在第二次插入 TARGET 表时,触发器插入 6,因为其计数为 1。
INSERTINTO TARGET VALUES (1);
SELECT * FROM SAMPLE;--5
INSERTINTO TARGET VALUES (2);
SELECT * FROM SAMPLE;--5 6
语法:
CREATE VIEW [<schema_name>.]<view_name> [(<column_name>, ... )] AS <subquery>
描述:
CREATE VIEW 可以有效地根据 SQL 结果创建虚拟表,这不是真正意义上的表,因为它本身不包含数据。
当列名一起作为视图的名称,查询结果将以列名显示。如果列名被省略,查询结果自动给出一个适当的列名。列名的数目必须与从<subquery>返回的列数目相同。
支持视图的更新操作,如果满足以下条件:
视图中的每一列必须映射到单个表中的一列。
如果基表中的一列有 NOT NULL 约束,且没有默认值,该列必须包含在可插入视图的列中。更新操作没有该条件。
例如在 SELECT 列表,必须不包含聚合或分析的功能,以下是不允许的:
. 在 SELECT 列表中的 TOP, SET, DISTINCT 操作
. GROUP BY, ORDER BY 子句
在 SELECT 列表中必须不能含有子查询。
必须不能包含序列值(CURRVAL, NEXTVAL)。
必须不能包含作为基视图的列视图。
如果基视图或表是可更新的,符合上述条件的基础上,基视图或表的视图是可更新的。
例子:
选择表 a 中的所有数据创建视图 v:
CREATEVIEW v ASSELECT * FROM a;
语法:
DROP AUDIT POLICY <policy_name>
描述:
DROP AUDIT POLICY 语句删除审计策略。 <policy_name>必须指定已存在的审计策略。
只有拥有系统权限 AUDIT ADMIN 的数据库用户允许删除审计策略。每个拥有该权限的数据库用户可以删除任意的审计策略,无论是否由该用户创建。
即使审计策略被删除了,可能发生的是,定义在已删除的审计策略中的活动将被进一步审计;如果也启用了其他审计策略和定义了审计活动。
暂时关闭审计策略时,可以禁用而不用删除。
系统和监控视图:
AUDIT_POLICY:显示所有审计策略和状态。
M_INIFILE_CONTENTS:显示数据库系统配置参数。
只有拥有系统权限 CATALOG READ, DATA ADMIN 或 INIFILE ADMIN 的用户可以查看M_INIFILE_CONTENTS 视图中的内容,对于其他用户则为空。
例子:
假设使用如下语句前,审计策略已创建:
CREATEAUDIT POLICY priv_audit AUDITING SUCCESSFUL GRANT PRIVILEGE, REVOKE PRIVILEGE, GRANT ROLE, REVOKE ROLE LEVEL CRITICAL;
现在,该审计策略必须删除:
DROPAUDIT POLICY priv_audit;
语法:
DROP FULLTEXT INDEX <fulltext_index_name>
描述:
DROP FULLTEXT INDEX 语句移除全文索引。
例子:
DROP FULLTEXT INDEX idx;
语法:
DROP INDEX <index_name>
描述:
DROP INDEX 语句移除索引。
例子:
DROPINDEX idx;
语法:
DROP SCHEMA <schema_name> [<drop_option>]
语法元素:
<drop_option> ::= CASCADE | RESTRICT
Default = RESTRICT
有限制的删除操作将删除对象当其没有依赖对象时。如果存在依赖对象,将抛出错误。
CASCADE级联删除:将删除对象以及其依赖对象。
描述:
DROP SCHEMA 语句移除schema。
例子:
创建集合 my_schema,表 my_schema.t,然后 my_schema 将使用 CASCADE 选项删除。
CREATESCHEMA my_schema;
CREATETABLE my_schema.t (a INT);
DROPSCHEMA my_schema CASCADE;
语法:
DROP SEQUENCE <sequence_name> [<drop_option>]
语法元素:
<drop_option> ::= CASCADE | RESTRICT
Default = RESTRICT
级联删除将删除对象以及其依赖对象。当未指定 CASCADE 可选项,将执行非级联删除对象,不会删除依赖对象,而是使依赖对象 (VIEW, PROCEDURE) 无效。
无效的对象可以重新验证当一个对象有同样的集合,并且已创建了对象名。对象 ID,集合名以及对象名为重新验证依赖对象而保留。
有限制的删除操作将删除对象当其没有依赖对象时。如果存在依赖对象,将抛出错误。
描述:
DROP SEQUENCE 语句移除序列。
例子:
DROPSEQUENCE s;
语法:
DROP [PUBLIC] SYNONYM <synonym_name> [<drop_option>]
语法元素:
<drop_option> ::= CASCADE | RESTRICT
Default = RESTRICT
级联删除将删除对象以及其依赖对象。当未指定 CASCADE 可选项,将执行非级联删除操作,不会删除依赖对象,而是使依赖对象 (VIEW, PROCEDURE) 无效。
无效的对象可以重新验证当一个对象有同样的集合,并且已创建了对象名。对象 ID,集合名以及对象名为重新验证依赖对象而保留。
有限制的删除操作将删除对象当其没有依赖对象时。如果存在依赖对象,将抛出错误。
描述:
DROP SYNONYM 删除同义词。可选项 PUBLIC 允许删除公用同义词。
例子:
表 a 已创建,然后为表 a 创建同义词 a_synonym 和公用同义词 pa_synonym:
CREATETABLE a (c INT);
CREATESYNONYM a_synonym FOR a;
CREATEPUBLICSYNONYM pa_synonym FOR a;
删除同义词 a_synonym 和公用同义词 pa_synonym
DROPSYNONYM a_synonym;
DROPPUBLICSYNONYM pa_synonym;
语法:
DROP TABLE [<schema_name>.]<table_name> [<drop_option>]
语法元素:
<drop_option> ::= CASCADE | RESTRICT
Default = RESTRICT
级联删除将删除对象以及其依赖对象。当未指定 CASCADE 可选项,将执行非级联删除操作,不会删除依赖对象,而是使依赖对象 (VIEW, PROCEDURE) 无效。
无效的对象可以重新验证当一个对象有同样的集合,并且已创建了对象名。对象 ID,集合名以及对象名为重新验证依赖对象而保留。
有限制的删除操作将删除对象当其没有依赖对象时。如果存在依赖对象,将抛出错误。
描述:
DROP TABLE 语句删除表。
例子:
创建表 A,然后删除。
CREATETABLE A(C INT);
DROPTABLE A;
DROP TRIGGER <trigger_name>
描述:
DROP TRIGGER 语句删除一个触发器。
只有在触发器所作用表上有 TRIGGER 权限的数据库用户才允许删除该表的触发器。
例子:
对于这个例子,你需要先创建一个名为 test_trigger 的触发器,如下:
CREATETABLE TARGET ( A INT);
CREATETABLE SAMPLE ( A INT);
CREATE TRIGGER TEST_TRIGGER AFTERUPDATEON TARGET
BEGIN
INSERTINTO SAMPLE VALUES(3);
END;
现在你可以删除触发器:
DROP TRIGGER TEST_TRIGGER;
语法:
DROP VIEW [<schema_name>.]<view_name> [<drop_option>]
语法元素:
<drop_option> ::= CASCADE | RESTRICT
Default = RESTRICT
级联删除将删除对象以及其依赖对象。当未指定 CASCADE 可选项,将执行非级联删除操作,不会删除依赖对象,而是使依赖对象 (VIEW, PROCEDURE) 无效。
无效的对象可以重新验证当一个对象有同样的集合,并且已创建了对象名。对象 ID,集合名以及对象名为重新验证依赖对象而保留。
有限制的删除操作将删除对象当其没有依赖对象时。如果存在依赖对象,将抛出错误。
描述:
DROP VIEW 语句删除视图。
例子:
表 t 已创建,然后选择表 a 中的所有数据创建视图 v:
CREATETABLE t (a INT);
CREATEVIEW v ASSELECT * FROM t;
删除视图 v:
DROPVIEW v;
语法:
RENAME COLUMN <table_name>.<old_column_name> TO <new_column_name>
描述:
RENAME COLUMN 语句修改列名:
例子:
创建表 B:
CREATETABLE B (A INTPRIMARYKEY, B INT);
显示表 B 中列名的列表:
SELECT COLUMN_NAME, POSITION FROM TABLE_COLUMNS WHERE SCHEMA_NAME =CURRENT_SCHEMA AND TABLE_NAME = ‘B‘ORDERBYPOSITION;
列 A 重名为 C:
RENAMECOLUMN B.A TO C;
语法:
RENAME INDEX <old_index_name> TO <new_index_name>
描述:
RENAME INDEX 语句重命名索引名。
例子:
表 B 已创建,然后索引 idx 建立在表 B 的列 B:
CREATETABLE B (A INTPRIMARYKEY, B INT);
CREATEINDEX idx on B(B);
显示表 B 的索引名列表:
SELECT INDEX_NAME FROM INDEXES WHERE SCHEMA_NAME = CURRENT_SCHEMA AND TABLE_NAME=‘B‘;
索引 idx 重名为 new_idx:
RENAMEINDEX idx TO new_idx;
语法:
RENAME TABLE <old_table_name> TO <new_table_name>
描述:
RENAME TABLE 语句在同一个Schema下,将表名修改为 new_table_name。
例子:
在当前集合创建表 A:
CREATETABLE A (A INTPRIMARYKEY, B INT);
显示当前集合下表名的列表:
SELECT TABLE_NAME FROM TABLES WHERE SCHEMA_NAME = CURRENT_SCHEMA;
表 A 重命名为 B:
RENAMETABLE A TO B;
SCHEMA mySchema 已创建,然后创建表 mySchema.A:
CREATESCHEMA mySchema;
CREATETABLE mySchema.A (A INTPRIMARYKEY, B INT);
显示模式 mySchema 下表名的列表:
SELECT TABLE_NAME FROM TABLES WHERE SCHEMA_NAME = ‘MYSCHEMA‘;
表 mySchema.A 重命名为 B:
RENAMETABLE mySchema.A TO B;注:修改后B还是在mySchema里
语法:
<table_conversion_clause> ::= [ALTER TYPE] { ROW [THREADS <number_of_threads>] | COLUMN [THREADS <number_of_threads> [BATCH <batch_size>]] }
语法元素:
<number_of_threads> ::= <numeric_literal>
指定进行表转换的并行线程数。线程数目的最佳值应设置为可用的 CPU 内核的数量。
<batch_size> ::= <numeric_literal>
指定批插入的行数,默认值为最佳值 2,000,000。插入表操作在每个<batch_size>记录插入后立即提交,可以减少内存消耗。 BATCH 可选项只可以在表 从行转换为列时使用。然而,大于 2,000,000的批大小可能导致高内存消耗,因此不建议修改该值。
描述:
通过复制现有的表中的列和数据,可以从现有的表创建一个不同存储类型的新表。该命令用来把表从行转换为列或从列转换为行。如果源表是行式存储,则新建的表为列式存储。
配置参数:
用于表转换的默认线程数在 indexserver.ini 的[sql]部分定义, table_conversion_parallelism =<numeric_literal> (初始值为 8)。
例子:
对于这个例子,你需要先创建欲进行转换的表:
CREATECOLUMNTABLE col_to_row (col1 INT, col2 INT)
CREATEROWTABLE row_to_col (col1 INT, col2 INT)
表 col_to_row 将以列式存储方式创建,表 row_to_col 则为行式存储。
现在你可以将表 col_to_row 的存储类型从列转为行:
ALTERTABLE col_to_row ALTERTYPEROW
你也可以将表 row_to_col 的存储类型从行转为列:
ALTERTABLE row_to_col ALTERTYPECOLUMN
为了使用批量转换模式,你需要在语句结尾处添加批选项:
ALTERTABLE row_to_col ALTERTYPECOLUMN BATCH 10000
语法:
TRUNCATE TABLE <table_name>
描述:
删除表中所有记录。当从表中删除所有数据时, TRUNCATE 比 DELETE FROM 快,但是 TRUNCATE无法回滚。要回滚删除的记录,应使用"DELETE FROM <table_name>"。
HISTORY 表可以通过执行该语句像正常表一样删除。历史表的所有部分(main, delta, history main and history delta)将被删除并且内容会丢失。
语法:
DELETE [HISTORY] FROM [<schema_name>.]<table_name> [WHERE <condition>]
<condition> ::= <condition> OR <condition>| <condition> AND <condition>| NOT <condition>| ( <condition> )| <predicate>
关于谓词的详情,请参阅 Predicates。
描述:
DELETE 语句当满足条件时,从表中删除所有记录。如果省略了 WHERE 子句,将删除表中所有记录。
DELETE HISTORY
DELETE HISTORY 将标记选中的历史表中历史记录进行删除。这表示执行完该语句后,引用已删除记录的时间旅行查询语句可能仍然可以查看这些数据。 为了在物理上删除这些记录,必须执行下面的语句:
ALTER SYSTEM RECLAIM VERSION SPACE; MERGE HISTORY DELTA of <table_name>;
请注意:在某些情况中,即使执行了上述两条语句,仍无法从物理上删除。
欲检查记录是否已从物理上删除,以下语句会有帮助:
SELECT * FROM <table_name> WHERE <condition> WITH PARAMETERS (‘REQUEST_FLAGS‘=(‘ALLCOMMITTED‘,‘HISTORYONLY‘));
注意: “WITH PARAMETERS (‘REQUEST_FLAGS‘= (‘ALLCOMMITTED‘,‘HISTORYONLY‘))”子句可能只适用于验证 DELETE HISTORY 语句的执行结果。
例子:
CREATETABLE T (KEYINTPRIMARYKEY, VAL INT);
INSERTINTO T VALUES (1, 1);
INSERTINTO T VALUES (2, 2);
INSERTINTO T VALUES (3, 3);
在下面的例子中,将删除一条记录:
DELETEFROM T WHEREKEY = 1;
语法:
EXPLAIN PLAN [SET STATEMENT_NAME = <statement_name>] FOR <sql_subquery>
语法元素:
<statement_name> ::= string literal used to identify the name of a specific executi on plan in the output table for a given SQL statement.
如果未指定 SET STATEMENT_NAME,则将设为 NULL。
描述:
EXPLAIN PLAN 语句用来评估 SAP HANA 数据库遵循的执行 SQL 语句的执行计划。评估的结果存在视图 EXPLAIN_PLAN_TABLE,以便稍后的用户检查。
SQL 语句必须是数据操纵语句,因此Schema定义语句不能在 EXPLAIN STATEMENT 中使用。
你可以从 EXPLAIN_PLAN_TABLE 视图中得到 SQL 计划,该视图为所有用户共享。这里是从视图读取 SQL 计划的例子:
SELECT * FROM EXPLAIN_PLAN_TABLE;
EXPLAIN_PLAN_TABLE 视图中的列:表 1:列名和描述
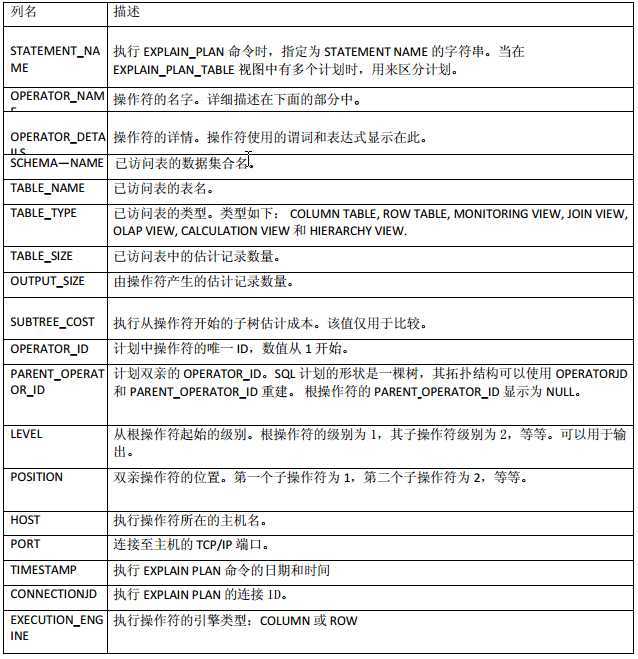
EXPLAIN_PLAN_TABLE 视图中的 OPERATOR_NAME 列。 表 2: OPERATOR_NAME 列显示的列式引擎操作符列表:

COLUMN SEARCH 为列式引擎操作符起始位置标记, ROW SEARCH 为行式引擎操作符起始位置标记。在以下的例子中, COLUMN SEARCH (ID 10)生成的中间结果被 ROW SEARCH (ID 7)使用, ROWSEARCH (ID 7) 被另一个 COLUMN SEARCH (ID 1)使用。位于 COLUMN SEARCH (ID 10) 最底层的操作符解释了 COLUMN SEARCH (ID 10) 是如何执行的。 ROW SEARCH (ID 7) 和 COLUMN SEARCH (ID 10) 之间的操作符说明了 ROW SEARCH (ID 7) 如何处理由 COLUMN SEARCH (ID 10) 生成的中间结果。位于COLUMN SEARCH (ID 1) 和 ROW SEARCH (ID 7)顶层的操作符解释了顶层 COLUMN SEARCH (ID 1) 是如何处理由 ROW SEARCH (ID 7)生成的中间结果。

SQL 计划解释例子。
该语句来自语 TPC-H 基准。例子中的所有表都是行式存储。
setschema hana_tpch;
DELETEFROM explain_plan_table WHERE statement_name = ‘TPC-H Q10‘;
EXPLAINPLANSET STATEMENT_NAME = ‘TPC-H Q10‘FOR
SELECT TOP 20 c_custkey,c_name,SUM(l_extendedprice * (1 - l_discount)) AS revenue,
c_acctbal,
n_name,
c_address,
c_phone,
c_comment
FROM
customer,
orders ,
lineitem,
nation
WHERE
c_custkey = o_custkey
AND l_orderkey = o_orderkey
AND o_orderdate >= ‘1993-10-01‘
AND o_orderdate < ADD_MONTHS(‘1993-10-01‘,3)
AND l_returnflag = ‘R‘
AND c_nationkey = n_nationkey
GROUPBY
c_custkey,
c_name,
c_acctbal ,
c_phone,
n_name,
c_address ,
c_comment
ORDERBY revenue DESC;
SELECT operator_name, operator_details , table_name FROM explain_plan_table WHERE statement_name = ‘TPC-H Q10‘;
以下是对这个查询语句的计划解释:
语法:
INSERT INTO [ <schema_name>. ]<table_name> [ <column_list_clause> ] { <value_list_clause> | <subquery> }
语法元素:
<column_list_clause> ::= ( <column_name>, ... )
<value_list_clause> ::= VALUES ( <expression>, ... )
描述:
INSERT 语句添加一条到表中。返回记录的子查询可以用来插入表中。如果子查询没有返回任何结果,数据库将不会插入任何记录。可以使用 INSERT 语句指定列的列表。不在列表中的列将显示默认值。如果省略了列的列表,数据库插入所有记录到表中。
例子:
CREATETABLE T (KEYINTPRIMARYKEY, VAL1 INT, VAL2 NVARCHAR(20));
在以下的例子中,你可以插入值:
INSERTINTO T VALUES (1, 1, ‘The first‘);
你可以将值插入到指定的列:
INSERTINTO T (KEY) VALUES (2);
你也可以使用子查询:
INSERTINTO T SELECT 3, 3, ‘The third‘FROM DUMMY;
语法:
LOAD <table_name> {DELTA | ALL | (<column_name>, ...)}
描述:
LOAD 语句明确地加载列式(注:Load只支持列式存储,对于行式存储不能使用)存储表的数据至内存中,而非第一次访问时加载。
DELTA
使用 DELTA,列式表的一部分将加载至内存。由于列式存储对于读操作做了优化和压缩,增量用来优化插入或更新。 所有的插入被传递给一个增量。
ALL
主要的和增量的列存储表中所有数据加载到内存中。
例子:
以下的例子加载整张表 a_table 至内存中。
LOAD a_table all;
以下的例子加载列 a_column 和表 a_table 列 another_column 至内存中。
LOAD a_table (a_column,another_column);
表加载状态可以查询:
select loaded from m_cs_tables where table_name = ‘<table_name>‘
语法:
MERGE [HISTORY] DELTA OF [<schema_name>.]<table_name> [PART n] [WITH PARAMETERS (<parameter_key_value>, ...)]
语法元素:
WITH PARAMETERS (<parameter_list>):
<parameter_list> ::= <parameter>,<parameter_list>
<parameter> ::= <parameter_name> = <parameter_setting>
<parameter_name> ::= ‘SMART_MERGE‘ | ‘MEMORY_MERGE‘
<parameter_setting> ::= ‘ON‘ | ‘OFF‘
当前参数: ‘SMART_MERGE‘ = ‘ON‘ | ‘OFF‘。当 SMART_MERGE 为 ON,数据库执行智能合并,这代表数据库基于 Indexserver 配置中定义的合并条件来决定是否合并。‘MEMORY_MERGE‘ = ‘ON‘ | ‘OFF‘ 数据库只合并内存中表的增量部分,不会被持久化。
描述:
使用 DELTA,列式表的一部分将加载至内存。由于列式存储对于读操作做了优化和压缩,增量用来优化插入或更新。 所有的插入被传递至一个增量部分。
HISTORY 可以指定合并历史表增量部分到临时表的主要历史部分。
PART-可以指定合并历史表增量部分到临时表的主要历史部分,该表已分区。
例子:
MERGEDELTAOF A;
Merges the column store table delta part to its main part.
MERGEDELTAOF A WITH PARAMETERS(‘SMART_MERGE‘ = ‘ON‘);
Smart merges the column store table delta part to its main part.
MERGEDELTAOF A WITH PARAMETERS(‘SMART_MERGE‘ = ‘ON‘, ‘MEMORY_MERGE‘ = ‘ON‘);
Smart merges the column store table delta part to its main part non-persistent, in memory only.
MERGEDELTAOF A PART 1;
Merge the delta of partition no. 1 of table with name "A" to main part of partion no. 1.
MERGEHISTORYDELTAOF A;
Merge the history delta part of table with name "A" into its history main part.
MERGEHISTORYDELTAOF A PART 1;
Merges the column store table delta part of the history of table with name "A" to its history main part.
语法:
UPSERT [ <schema_name>. ]<table_name> [ <column_list_clause> ] { <value_list_clause> [ WHERE <condition> | WITH PRIMARY KEY ] | <subquery> }
REPLACE [ <schema_name>. ]<table_name> [ <column_list_clause> ] { <value_list_clause> [ WHERE <condition> | WITH PRIMARY KEY ] | <subquery> }
语法元素:
<column_list_clause> ::= ( <column_name>, ... )
<value_list_clause> ::= VALUES ( <expression>, ... )
<condition> ::= <condition> OR <condition>| <condition> AND <condition>| NOT <condition>| ( <condition> )| <predicate>
有关谓词的详情,请参阅 Predicates。
描述:
没有子查询的 UPSERT 或者 REPLACE 语句与 UPDATE 相似。唯一的区别是当 WHERE 子句为假(或没有Where子句)时,该语句像 INSERT 一样添加一条新的记录到表中。
对于表有 PRIMARY KEY 的情况,主键列必须包含在列的列表中。没有默认设定,由 NOT NULL 定义的列也必须包含在列的列表中。
有子查询的 UPSERT 或者 REPLACE 语句与 INSERT 一样,除了如果表中旧记录与主键的新记录值相同,则旧记录将被子查询返回的记录所修改。除非表有一个主键,否则就变得等同于 INSERT(即如果表没有设定主键,则为INSERT?),因为没有使用索引来判断新记录是否与旧记录重复。
有‘WITH PRIMARY KEY‘的 UPSERT 或 REPLACE 语句与有子查询的语句相同。其在 PRIMARY KEY 基础上工作。
例子:
CREATETABLE T (KEYINTPRIMARYKEY, VAL INT);
你可以插入一条新值:
UPSERT T VALUES (1, 1);--没有Where与子查询,直接插入
![]()
如果 WHERE 子句中的条件为假,将插入一条新值:
UPSERT T VALUES (2, 2) WHEREKEY = 2; --没有就插入
![]()
你可以更新列"VAL"的第一条记录
UPSERT T VALUES (1, 9) WHEREKEY = 1;--有就更新
![]()
或者你可以使用"WITH PRIMARY KEY" 关键字
UPSERT T VALUES (1, 8) WITHPRIMARYKEY;--根据主键进行更新,如果不存在,则插入
![]()
你可以使用子查询插入值:
UPSERT T SELECTKEY + 2, VAL FROM T;--将子查询的结果插入,如果存在,则更新
UPSERT T VALUES (5, 1) WITHPRIMARYKEY;--根据主键查询时不存在,则插入
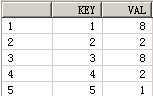
UPSERT T SELECT 5,3 from dummy;--存在,则更新

语法:
<select_statement> ::= <subquery> [ <for_update> | <time_travel> ]| ( <subquery> ) [ <for_update> | <time_travel> ]
<subquery> ::= <select_clause> <from_clause> [<where_clause>] [<group_by_clause>] [<having_clause>] [{<set_operator> <subquery>, ... }] [<order_by_clause>] [<limit>]
语法元素:
SELECT 子句:
SELECT 子句指定要返回给用户或外部的 select 子句一个输出,如果存在的话。
<select_clause> ::= SELECT [TOP <integer>] [ ALL | DISTINCT ] <select_list>
<select_list> ::= <select_item>[, ...]
<select_item> ::= [<table_name>.] *| <expression> [ AS <column_alias> ]
TOP n:TOP n 用来返回 SQL 语句的前 n 条记录。
DISTINCT 和 ALL:可以使用 DISTINCT 返回重复的记录,每一组选择只有一个副本。使用 ALL 返回选择的所有记录,包括所有重复记录的拷贝。默认值为 ALL。
Select_list:select_list 允许用户定义他们想要从表中选择的列。
*:*可以从 FROM 子句中列出的表或视图中选择所有列。如果集合名和表名或者表名带有星号(*),其用来限制结果集至指定的表。
column_alias:column_alias 可以用于简单地表示表达式。
FROM:FROM 子句中指定输入值,如表、视图、以及将在 SELECT 语句中使用的子查询。
<from_clause> ::= FROM {<table>, ... }
<table> ::= <table_name> [ [AS] <table_alias> ] | <subquery> [ [AS] <table_alias> ] | <joined_table>
<joined_table> ::= <table> [<join_type>] JOIN <table> ON <predicate> | <table> CROSS JOIN <table> | <joined_table>
<join_type> ::= INNER | { LEFT | RIGHT | FULL } [OUTER]
table alias:表别名可以用来简单地表示表或者子查询。
join_type 定义了将执行的联接类型, LEFT 表示左外联接, RIGHT 表示右外联接, FULL 表示全外联接。执行联接操作时, OUT 可能或者可能不使用。
ON <predicate>:ON 子句定义联接谓词。
CROSS JOIN:CROSS 表示执行交叉联接,交叉联接生成两表的交叉积结果。
WHERE 子句
WHERE 子句用来指定 FROM 子句输入的谓词, 使用户可以检索所需的记录。
<where_clause> ::= WHERE <condition>
<condition> ::=<condition> OR <condition> | <condition> AND <condition> | NOT <condition> | ( <condition> ) | <predicate>
<predicate> ::= <comparison_predicate> | <range_preciate> | <in_predicate> | <exist_predicate> | <like_predicate> | <null_predicate>
<comparison_predicate> ::= <expression> { = | != | <> | > | < | >= | <= } [ ANY | SOME | ALL ] ({<expression_list> | <subquery>})
<range_predicate> ::= <expression> [NOT] BETWEEN <expression> AND <expression>
<in_predicate> ::= <expression> [NOT] IN ( { <expression_list> | <subquery> } )
<exist_predicate> ::= [NOT] EXISTS ( <subquery> )
<like_predicate> ::= <expression> [NOT] LIKE <expression> [ESCAPE <expression>]
<null_predicate> ::= <expression> IS [NOT] NULL
<expression_list> ::= {<expression>, ... }
GROUP BY 子句
<group_by_clause> ::=GROUP BY { { <expression>, ... } | <grouping_set> }
<grouping_set> ::= { GROUPING SETS | ROLLUP | CUBE }[BEST <integer>] [LIMIT <integer>[OFFSET <integer>] ] [WITH SUBTOTAL] [WITH BALANCE] [WITH TOTAL]
[TEXT_FILTER <filterspec> [FILL UP [SORT MATCHES TO TOP]]] [STRUCTURED RESULT [WITH OVERVIEW] [PREFIX <string_literal>] | MULTIPLE RESULTSETS] ( <grouping_expression_list> )
<grouping_expression_list> ::= { <grouping_expression>, ... }
<grouping_expression> ::=<expression>| ( <expression>, ... ) | ( ( <expression>, ... ) <order_by_clause> )
GROUP BY 用来对基于指定列值选定的行进行分组。
GROUPING SETS
在一条语句中, 生成多个特定数据分组结果。如果没有设置例如 best 和 limit 的可选项,结果将和 UNION ALL 每个指定组的聚合值相同。例如:
"select col1, col2, col3, count(*) from t groupbygrouping sets ( (col1, col2), (col1, col3) )"与" select col1, col2, NULL, count(*) from t groupby col1, col2 unionallselect col1, NULL, col3,count(*) from t groupby col1, col3"相同。在 grouping-sets 语句中,
每个(col1, col2) 和(col1, col3)定义了分组。
ROLLUP
在一条语句中,生成多级聚合结果。例如, "rollup (col1, col2,col3)"与有额外 聚合,但没有分组的"grouping sets ( (col1, col2, col3), (col1, col2), (col1) )"结果相同。因此,结果集所包含的分组的数目是 ROLLUP 列表中的列加上一个最后聚合的数目,如果没有额外的选项。
CUBE
在一条语句中,生成多级聚合的结果。例如, "cube (col1, col2,col3)" 与有额外聚合,但没有分组的"grouping sets ( (col1, col2, col3), (col1, col2), (col1, col3), (col2, col3), (col1), (col2),(col3) )"结果相同。因此,结果集所包含分组的数目与所有可能排列在 CUBE 列表的列加上一个最后聚合的数目是相同的,如果没有附加的选项。
BEST n
返回每个以行聚合数降序排列的分组集中前 n 个分组集(返回的是某个分组里的所有记录,而不是某几条)。 n 可以是任意零,正数或负数。当 n 为零时,作用和没有 BEST 选项一样。当 n 为负数表示以升序排序。
LIMIT n1 [OFFSET n2]
返回每个分组集中(取每个组中的部分行)第一个 N1 分组记录跳过 N2 个后的结果。
WITH SUBTOTAL
返回每个分组集中由 OFFSET 或者 LIMIT 控制的返回结果的分类汇总。除非设置了 OFFSET 和LIMIT,返回值将和 WITH TOTAL 相同。
WITH BALANCE
返回每个分组集中 OFFSET 或者 LIMIT 没有返回的其余结果值。
WITH TOTAL
返回每个分组集中额外的合计总值行。 OFFSET 和 LIMIT 选项不能修改该值。
TEXT_FILTER <filterspec>
执行文本过滤或者用<filterspec>高亮分组列, <filterspec>为单引号字符串,语法如下:
<filterspec> ::= ‘[<prefix>]<element>{<subsequent>, ...}‘
<prefix> ::= + | - | NOT
<element> ::= <token> | <phrase>
<token> ::= !! Unicode letters or digits
<phrase> ::= !! double-quoted string that does not contain double quotations inside
<subsequent> ::= [<prefix_subsequent>]<element>
<prefix_subsequent> ::= + | - | NOT | AND | AND NOT | OR
<filterspec>定义的过滤是由与逻辑操作符 AND, OR 和 NOT 连接的标记/词组或者短语组成。 一个标记相匹配的字符串,其中包含对应不区分大小写的单词, ‘ab‘ 匹配 ‘ab cd‘ 和 ‘cd Ab‘ ,但不匹配‘abcd‘。一个标记可以包含通配字符’,匹配任何字符串, ’匹配任意字母。但是在词组内, ’和’不是通配符。逻辑运算符 AND, OR 和 NOT 可以与标记,词组一起使用。由于 OR 是默认操作符, ‘ab cd‘ 和‘ab OR cd‘意义一样。注意,逻辑运算符应该大写。作为一种逻辑运算符,前缀‘+‘ 和 ‘-‘各自表示包含(AND) 和不包含 (AND NOT)。例如, ‘ab -cd‘ 和 ‘ab AND NOT cd‘意义相同。如果没有 FILL UP 选项,只返回含有匹配值的分组记录。 需要注意的是一个过滤器仅被运用到每个分组集的第一个分组列。
FILL UP
不仅返回匹配的分组记录,也包含不匹配的记录。 text_filter 函数对于识别哪一个匹配是很有用的。参阅下面的‘Related Functions’。
SORT MATCHES TO TOP
返回匹配值位于非匹配值前的分组集。该选项不能和 SUBTOTAL, BALANCE 和 TOTAL 一起使用。
STRUCTURED RESULT
结果作为临时表返回。 对于每一个分组集创建一个临时表,如果设置 WITH OVERVIEW 选项,将为分组集的总览创建额外的临时表,该临时表的名字由 PREFIX 选项定义。
WITH OVERVIEW
将总览返回至单独的额外一张表中。
PREFIX 值
使用前缀命名临时表。必须以"#"开始,代表是临时表。如果省略,默认前缀为"#GN", 然后,连接该前缀值和一个非负整数,用作临时表的名称,比如"#GN0", "#GN1" 和 "#GN2"。
MULTIPLE RESULTSETS
返回多个结果集中的结果。
相关函数
grouping_id ( <grouping_column1, ..., grouping_columnn> )函数返回一个整数,判断每个分组记录属于哪个分组集。 text_filter ( <grouping_column> ) 函数与 TEXT_FILTER, FILL UP, 和 SORT MATCHES TO TOP 一起使用,显示匹配值或者 NULL。当指定了 FILL UP 选项时,未匹配值显示为 NULL。
返回格式
如果 STRUCTURED RESULT 和 MULTIPLE RESULTSETS 都没有设置,返回所有分组集 的联合,以及对于没有包含在指定分组集中的属性填充的 NULL 值。使用 STRUCTURED RESULT,额外的创建临时表,在同一会话中用"SELECT * FROM <table name>"可以查询。表名遵循的格式:
<PREFIX>0:如果定义了 WITH OVERVIEW,该表将包含总览。
<PREFIX>n: 由 BEST 参数重新排序的第 n 个分组集。
使用 MULTIPLE RESULTSETS,将返回多个结果集。每个分组集的分组记录都在单个结果集中。
HAVING 子句:
HAVING 子句用于选择满足谓词的特定分组。如果省略了该子句,将选出所有分组。
<having_clause> ::= HAVING <condition>
SET OPERATORS
SET OPERATORS 使多个 SELECT 语句相结合,并只返回一个结果集。
<set_operator> ::= UNION [ ALL | DISTINCT ] | INTERSECT [DISTINCT] | EXCEPT [DISTINCT]
UNION ALL
选择所有 select 语句中的所有(并集)记录。重复记录将不会删除。
UNION [DISTINCT]
选择所有 SELECT 语句中的唯一记录,在不同的 SELECT 语句中删除重复记录。 UNION 和 UNION DISTINCT 作用相同。
INTERSECT [DISTINCT]
选择所有 SELECT 语句中共有(交集)的唯一记录。
EXCEPT [DISTINCT]
在位于后面的 SELECT 语句删除(差集)重复记录后,返回第一个 SELECT 语句中所有唯一的记录。
ORDER BY 子句
<order_by_clause> ::= ORDER BY { <order_by_expression>, ... }
<order_by_expression> ::= <expression> [ ASC | DESC ]| <position> [ ASC | DESC]
<position> ::= <integer>
ORDER BY 子句用于根据表达式或者位置对记录排序。位置表示选择列表的索引。对"select col1,col2 from t order by 2", 2 表示 col2 在选择列表中使用的第二个表达式。 ASC 用于按升序排列记录,DESC 用于按降序排列记录。默认值为 ASC。
LIMIT
LIMIT 关键字定义输出的记录数量。
<limit> ::= LIMIT <integer> [ OFFSET <integer> ]
LIMIT n1 [OFFSET n2]:返回跳过 n2 条记录后的最先 n1 条记录。
FOR UPDATE
FOR UPDATE 关键字锁定记录,以便其他用户无法锁定或修改记录,直到本次事务结束。
<for_update> ::= FOR UPDATE
TIME TRAVEL
该关键字与时间旅行有关,用于语句级别时间旅行回到 commit_id 或者时间指定的快照。
<time_travel> ::= AS OF { { COMMIT ID <commit_id> } | { UTCTIMESTAMP <timestamp> }}时间旅行只对历史列表适用。 <commit_id>在每次提交后可以从 m_history_index_last_commit_id 获得,其相关的<timestamp>可以从 sys.m_transaction_history 读取。
createhistorycolumntable x ( a int, b int ); // after turnning off auto commit
insertinto x values (1,1);
commit;
select last_commit_id from m_history_index_last_commit_id where session_id = current_connection;// e.g., 10
insertinto x values (2,2);
commit;
select last_commit_id from m_history_index_last_commit_id where session_id = current_connection; // e.g., 20
deletefrom x;
commit;
select last_commit_id from m_history_index_last_commit_id where session_id = current_connection; // e.g., 30
select * from x asofcommit id 30; // return nothing
select * from x asofcommit id 20; // return two records (1,1) and (2,2)
select * from x asofcommit id 10; // return one record (1,1)
select commit_time from sys.transaction_history where commit_id = 10; // e.g., ‘2012-01-01 01:11:11‘
select commit_time from sys.transaction_history where commit_id = 20; // e.g., ‘2012-01-01 02:22:22‘
select commit_time from sys.transaction_history where commit_id = 30; // e.g., ‘2012-01-01 03:33:33‘
select * from x asof utctimestamp ‘2012-01-02 02:00:00‘; // return one record (1,1)
select * from x asof utctimestamp ‘2012-01-03 03:00:00‘; // return two records (1,1) and (2,2)
select * from x asof utctimestamp ‘2012-01-04 04:00:00‘; // return nothing
例子:
表 t1:
droptable t1;
createcolumntable t1 ( id intprimarykey, customer varchar(5), yearint, product varchar(5), sales int );
insertinto t1 values(1, ‘C1‘, 2009, ‘P1‘, 100);
insertinto t1 values(2, ‘C1‘, 2009, ‘P2‘, 200);
insertinto t1 values(3, ‘C1‘, 2010, ‘P1‘, 50);
insertinto t1 values(4, ‘C1‘, 2010, ‘P2‘, 150);
insertinto t1 values(5, ‘C2‘, 2009, ‘P1‘, 200);
insertinto t1 values(6, ‘C2‘, 2009, ‘P2‘, 300);
insertinto t1 values(7, ‘C2‘, 2010, ‘P1‘, 100);
insertinto t1 values(8, ‘C2‘, 2010, ‘P2‘, 150);
以下的 GROUPING SETS 语句和第二个 group-by 查询相等。 需要注意的是,两组在第一个查询的分组集内指定的各组在第二个查询。
select customer, year, product, sum(sales) from t1 groupbyGROUPING SETS((customer, year),(customer, product));
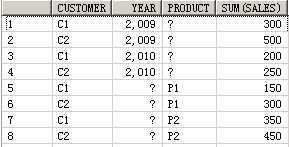
select customer, year, NULL, sum(sales) from t1 groupby customer, year
unionall
select customer, NULL, product, sum(sales) from t1 groupby customer, product;
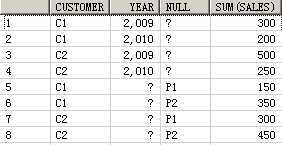
注:Union时,两个Select语句的字段个数,对应字段的类型要相同。BW中的MultiCube是将多个InfoProvider的记录插入到MultiCube所对应的物理表中,这一过程并不是通过Union SQL语句来完成的,而是一个个将InfoProvider的数据插入到MultiCube中,所以来自InfoProvider的字段个数可以不同,只是在报表展示时,通过 Group进行了合并
ROLLUP 和 CUBE 经常使用的分组集的简明表示。 下面的 ROLLUP 查询与第二个 group-by 查询相等。
select customer, year, sum(sales) from t1 groupby ROLLUP(customer, year);
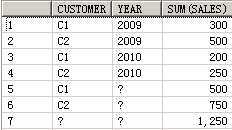
select customer, year, sum(sales) from t1 groupbygrouping sets((customer, year),(customer))
unionall
selectNULL, NULL, sum(sales) from t1;
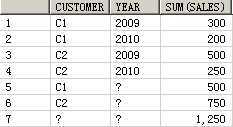
selectNULL, NULL, sum(sales) from t1;
![]()
select customer, year, sum(sales) from t1 groupbygrouping sets((customer, year),(customer))
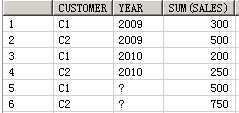
select customer, year, sum(sales) from t1 groupbygrouping sets((customer, year),(customer),())
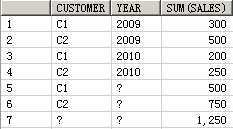
以下的 CUBE 查询与第二个 group-by 查询相等。
select customer, year, sum(sales) from t1 groupby CUBE(customer, year);
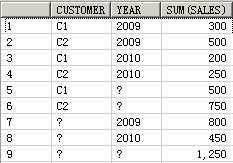
select customer, year, sum(sales) from t1 groupbygrouping sets((customer, year),(customer),(year))
unionall
selectNULL, NULL, sum(sales) from t1;
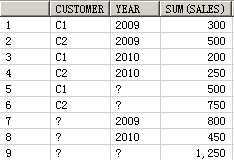
select customer, year, sum(sales) from t1 groupbygrouping sets((customer, year),(customer),(year))
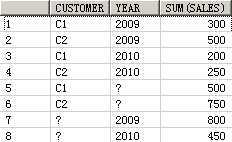
select customer, year, sum(sales) from t1 groupbygrouping sets((customer, year),(customer),(year),())
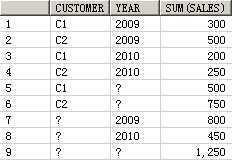
BEST 1 指定以下查询语句只能返回最上面的 1 个 best 组。在该个例子中,对于(customer, year)组存在 4 条记录,而(product)组存在 2 条记录,因此返回之前的 4 条记录。对于 ‘BEST -1‘ 而非 ‘BEST 1‘,返回后 2 条记录。
select customer, year, product, sum(sales) from t1 groupbygrouping sets ((customer, year),(product));
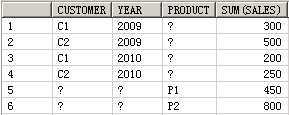
select customer, year, product, sum(sales) from t1 groupbygrouping sets BEST 1((customer, year),(product));
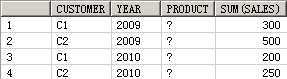
select customer, year, product, sum(sales) from t1 groupbygrouping sets BEST 2((customer, year),(product));
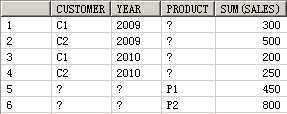
select customer, year, product, sum(sales) from t1 groupbygrouping sets BEST -1((customer, year),(product));
![]()
LIMIT2 限制每组最大记录数为 2。对于(customer, year) 组,存在 4 条记录,只返回前 2 条记录;(product)组的记录条数为 2,因此返回所有结果。
select customer, year, product, sum(sales) from t1 groupbygrouping sets LIMIT 2((customer, year),(product));

WITH SUBTOTAL 为每一组生成额外的一条记录,显示返回结果的分类汇总(没有显示出来的不会被统计,这与With Total是不一样的,请参考后面的With Total)。这些记录的汇总对customer, year, product 列返回 NULL,选择列表中 sum(sales)的总和。
select customer, year, product, sum(sales) from t1 groupbygrouping sets LIMIT 2 WITH SUBTOTAL((customer, year),(product));
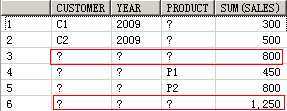
WITH BALNACE 为每一组生成额外的一条记录,显示未返回结果的分类汇总(如果未返回结果行不存在,则以分类汇总行还是会显示,只不过都是问号,而不是不显示)。
select customer, year, product, sum(sales) from t1 groupbygrouping sets WITH BALANCE((customer, year),(product));
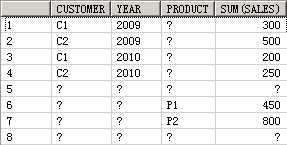
select customer, year, product, sum(sales) from t1 groupbygrouping sets LIMIT 2 WITH BALANCE((customer, year),(product));
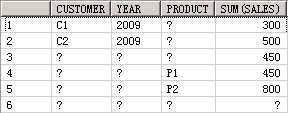
select customer, year, product, sum(sales) from t1 groupbygrouping sets LIMIT 1 WITH BALANCE((customer, year),(product));

WITH TOTAL为每一组生成额外的一条记录,显示所有分组记录的汇总,不考虑该分组记录是否返回(即没有显示在分组里的数据也会汇总起来,如下面的 300 + 500 <> 1250,因为使用了Limit限制了每组返回的条数,但那些未显示出来的数据也会被一起统计,这与 With SubTotal不一样)。
select customer, year, product, sum(sales) from t1 groupbygrouping sets LIMIT 2 WITH TOTAL((customer, year),(product))
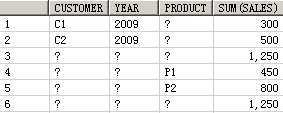
TEXT_FILTER 允许用户获得有指定的<filterspec>的分组的第一列。以下查询将搜索以’2’结尾的列:对于第一个分组集为 customers, 第二个为 products。只返回三条匹配的记录。在 SELECT 列表中的 TEXT_FILTER 对于查看哪些值匹配是很有用的。
select customer, year, product, sum(sales), text_filter(customer), text_filter(product) from t1
groupbygrouping sets TEXT_FILTER ‘*2‘((customer, year),(product));--只是去搜索每个分组里里的第一列,如这里的customer与product,但不搜索Year列,因为不是分组中的首列

FILL UP 用于返回含有<filterspec>的匹配和不匹配的记录。 因此,下面的查询返回 6 条记录,而先前的查询返回 3 条。
select customer, year, product, sum(sales), text_filter(customer), text_filter(product)
from t1 groupbygrouping sets TEXT_FILTER ‘*2‘ FILL UP ((customer, year),(product));

SORT MATCHES TO TOP 用于提高匹配记录。对于每个分组集,将对其分组记录进行排序。
select customer, year, product, sum(sales), text_filter(customer), text_filter(product)
from t1 groupbygrouping sets TEXT_FILTER ‘*2‘ FILL UP SORT MATCHES TO TOP((customer, year),(product));
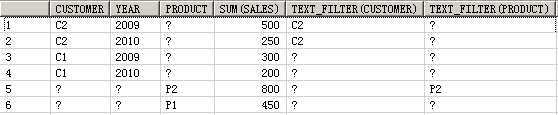
STRUCTURED RESULT 为每个分组集创建一张临时表,并且可选地,为总览表也创建一张。表"#GN1" 为 分组集(customer, year),表"#GN2" 为分组集(product)。注意,每张表只含有一列相关列。也就是说,表"#GN1"不包含列"product",而表"#GN2"不包含列"customer" and "year"。
select customer, year, product, sum(sales) from t1 groupbygrouping sets STRUCTURED RESULT((customer, year),(product));
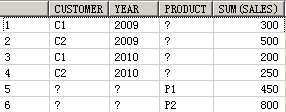
select * from"#GN1";
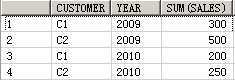
select * from"#GN2";
![]()
WITH OVERVIEW 为总览表创建临时表"#GN0"。
select customer, year, product, sum(sales)
from t1 groupbygrouping sets structured result WITH OVERVIEW((customer, year),(product));
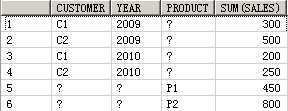
select * from"#GN0";

select * from"#GN1";
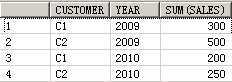
select * from"#GN2";
![]()
用户可以通过使用 PREFIX 关键字修改临时表的名字。注意,名字必须以临时表的前缀‘#‘开始,下面与上面结果是一样,只是临时表名不一样而已:
select customer, year, product, sum(sales)
from t1
groupbygrouping sets STRUCTURED RESULT WITH OVERVIEW PREFIX ‘#MYTAB‘((customer, year),(product));
select * from"#MYTAB0";
select * from"#MYTAB1";
select * from"#MYTAB2";
当相应的会话被关闭或用户执行 drop 命令,临时表被删除。 临时列表是显示在m_temporary_tables。
select * from m_temporary_tables;
MULTIPLE RESULTSETS 返回多个结果的结果集。在 SAP HANA Studio 中,以下查询将返回三个结果集:一个为总览表,两个为分组集。
select customer, year, product, sum(sales) from t1 groupbygrouping sets MULTIPLE RESULTSETS((customer, year),(product));
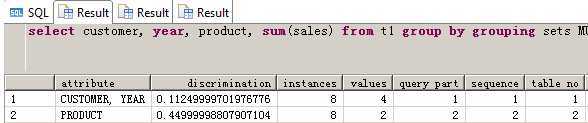
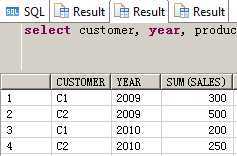
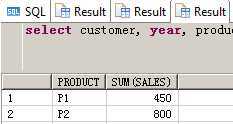
语法:
UNLOAD <table_name>
描述:
UNLOAD 语句从内存中卸载列存储表, 以释放内存。表将在下次访问时重新加载。
例子:
在下面的例子中,表 a_table 将从内存中卸载。
UNLOAD a_table;
卸载表的状态可以通过以下语句查询:
select loaded from m_cs_tables where table_name = ‘t1‘;
语法
UPDATE [<schema_name>.]<table_name> [ AS <alias_name> ] <set_clause> [ WHERE <condition> ]
<set_clause> ::= SET {<column_name> = <expression>},...
关于表达式的详情,请参见 Expressions。
<condition> ::= <condition> OR <condition> | <condition> AND <condition> | NOT <condition> | ( <condition> ) | <predicate>
关于谓词的详情,请参见 Predicates。
描述:
UPDATE 语句修改满足条件的表中记录的值。如果 WHERE 子句中条件为真,将分配该列至表达式的结果中。如果省略了 WHERE 子句,语句将更新表中所有的记录。
例子:
CREATETABLE T (KEYINTPRIMARYKEY, VAL INT);
INSERTINTO T VALUES (1, 1);
INSERTINTO T VALUES (2, 2);
![]()
如果 WHERE 条件中的条件为真,记录将被更新。
UPDATE T SET VAL = VAL + 1 WHEREKEY = 1;
![]()
如果省略了 WHERE 子句,将更新表中所有的记录。
UPDATE T SET VAL = KEY + 10;
![]()
语法:
SET SYSTEM LICENSE ‘<license key>‘
描述:
安装许可证密钥的数据库实例。许可证密钥(<license key>="">) 将从许可证密钥文件中复制黏贴。
执行该命令需要系统权限 LICENSE ADMIN。
例子:
SETSYSTEM LICENSE ‘----- Begin SAP License -----
SAPSYSTEM=HD1
HARDWARE-KEY=K4150485960
INSTNO=0110008649
BEGIN=20110809
EXPIRATION=20151231
LKEY=...
SWPRODUCTNAME=SAP-HANA
SWPRODUCTLIMIT=2147483647
SYSTEM-NR=00000000031047460‘
语法:
ALTER CONFIGURATION (<filename>, <layer>[, <layer_name>]) SET | UNSET <parameter_key_value_list> [ WITH RECONFIGURE]
语法元素:
<filename> ::= <string_literal>
行存储引擎配置的情况下,文件名是‘indexserver.ini‘。 所使用的文件名必须是一个位于’DEFAULT’层的 ini 文件。如果选择文件的文件名在所需的层不存在,该文件将用 SET 命令创建。
<layer> ::= <string_literal>
设置配置变化的目标层。 该参数可以是‘SYSTEM‘或‘HOST‘。 SYSTEM 层为客户设置的推荐层。 HOST层应该一般仅可用于少量的配置,例如, daemon.ini 包含的参数。
<layer_name> ::= <string_literal>
如果上述的层设为’HOST’, layer_name 将用于设置目标 tenant 名或者目标主机名。例如,
‘selxeon12‘ 为目标 ‘selxeon12‘ 主机名。
SET
SET 命令更新键值,如果该键已存在,或者需要的话插入该键值。
UNSET
UNSET 命令删除键及其关联值。
<parameter_key_value_list> ::={(<section_name>,<parameter_name>) = <parameter_value>},...
指定要修改的 ini 文件的段、键和值语句如下:
<section_name> ::= <string_literal>
将要修改的参数段名:
<parameter_name> ::= <string_literal>
将要修改的参数名:
<parameter_value> ::= <string_literal>
将要修改的参数值。
WITH RECONFIGURE
当指定了 WITH RECONFIGURE,配置的修改将直接应用到 SAP HANA 数据库实例。
当未指定 WITH RECONFIGURE,新的配置将写到文件 ini 中,然而,新的值将不会应用到当前运行系统中,只在数据库下次的启动时应用。这意味 ini 文件中的内容可能和 SAP HANA 数据库使用的实际配置值存在不一致。
描述:
设置或删除 ini 文件中的配置参数。 ini 文件配置用于 DEFAULT, SYSTEM, HOST 层。
注意: DEFAULT 层配置不能使用此命令更改或删除。
以下为 ini 文件位置的例子:
DEFAULT: /usr/sap/<SYSTEMNAME>/HDB<INSTANCENUMBER>/exe/config/indexserver.ini
SYSTEM: /usr/sap/<SYSTEMNAME>/SYS/global/hdb/custom/config/indexserver.ini
HOST: /usr/sap/<SYSTEMNAME>/HDB<INSTANCENUMBER>/<HOSTNAME>/indexserver.ini
配置层的优先级: DEFAULT < SYSTEM < HOST。这表示 HOST 层具有最高优先级,跟着是 SYSTEM层,最后是 DEFAULT 层。最高优先级的配置将应用到运行环境中。 如果最高优先级的配置被删除,具有下一个最高优先级的配置将被应用。
系统和监控视图:
目前可供使用的 ini 文件在系统表 M_INIFILES 列出,并且当前配置在系统表 M_INIFILE_CONTENTS可见。
例子:
修改系统层配置的例子如下:
ALTERSYSTEMALTER CONFIGURATION (‘filename‘, ‘layer‘) SET (‘section1‘, ‘key1‘) = ‘value1‘, (‘section2‘,‘key2‘) = ‘value2‘, ... [WITH RECONFIGURE];
ALTERSYSTEMALTER CONFIGURATION (‘filename‘, ‘layer‘, ‘layer_name‘ ) UNSET (‘section1‘, ‘key1‘),(‘section2‘), ...[WITH RECONFIGURE];
语法:
ALTER SYSTEM ALTER SESSION <session_id> SET <key> = <value>
语法元素:
<session_id> ::= <unsigned_integer>
应当设置变量的会话的 ID。
<key> ::= <string_literal>
会话变量的键值,最大长度为 32 个字符。
<value> ::= <string_literal>
会话变量的期望值,最大长度为 512 个字符。
描述:
使用该命令,你可以设置数据库会话的会话变量:
注意:有几个只读会话变量,你不能使用该命令修改值: APPLICATION, APPLICATIONUSER,TRACEPROFILE。
会话变量可以使用 SESSION_CONTEXT 函数获得,使用 ALTER SYSTEM ALTER SESSION UNSET 命令取消设置。
例子:
在以下的例子中,你在会话 200006 将变量‘MY_VAR‘ 设为 ‘dummy‘:
ALTERSYSTEMALTER SESSION 200006 SET‘MY_VAR‘= ‘dummy‘;
语法:
ALTER SYSTEM ALTER SESSION <session_id> UNSET <key>
语法元素:
<session_id> ::= <unsigned_integer>
应当取消设置变量的会话 ID。
<key> ::= <string_literal>
会话变量的键值, 最大长度为 32 个字符。
描述:
使用该命令,你可以取消设置数据库会话的会话变量。
会话可以通过 SESSION_CONTEXT 函数获得。
例子:
获得当前会话的会话变量:
SELECT * FROM M_SESSION_CONTEXT WHERE CONNECTION_ID = CURRENT_CONNECTION
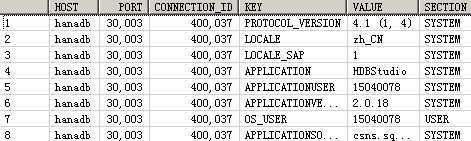
从特定会话中删除会话变量:
ALTERSYSTEMALTER SESSION 200001 UNSET ‘MY_VAR‘;
语法
ALTER SYSTEM CANCEL [WORK IN] SESSION <session_id>
语法元素:
<session_id> ::= <string_literal>
所需会话的会话 ID。
描述:
通过指定会话 ID 取消当前正在运行的语句。取消的会话将在取消后回滚,执行中的语句将返回错误代码 139(current operation cancelled by request and transaction rolled back)。
例子:
你可以使用下面的查询来获取当前的连接 ID 和它们执行的语句。
SELECT C.CONNECTION_ID, PS.STATEMENT_STRING
FROM M_CONNECTIONS C JOIN M_PREPARED_STATEMENTS PS
ON C.CONNECTION_ID = PS.CONNECTION_ID AND C.CURRENT_STATEMENT_ID = PS.STATEMENT_ID
WHERE C.CONNECTION_STATUS = ‘RUNNING‘AND C.CONNECTION_TYPE = ‘Remote‘
![]()
利用上文中的查询语句获得的连接 ID,你现在可以取消一条正在运行的查询,语句如下:
ALTERSYSTEM CANCEL SESSION ‘400037‘;
语法:
ALTER SYSTEM CLEAR SQL PLAN CACHE
描述:
SQL PLAN CACHE 存储之前执行的 SQL 语句生成的计划, SAP HANA 数据库使用该计划缓存加速查询语句的执行,如果同样的 SQL 语句 再次执行。计划缓存也收集关于计划准备和执行的数据。
你可以从以下的监控视图中找到更多有关 SQL 缓存计划的内容:
M_SQL_PLAN_CACHE, M_SQL_PLAN_CACHE_OVERVIEW
ALTER SYSTEM CLEAR SQL PLAN CACHE 语句删除所有当前计划缓存没有执行的 SQL 计划。该命令还可以从计划缓存中删除所有引用计数为 0 的计划,并重置所有剩余计划的统计数据。最后,该命令也重置监控视图 M_SQL_PLAN_CACHE_OVERVIEW 的内容。
例子:
ALTERSYSTEM CLEAR SQLPLANCACHE
语法:
ALTER SYSTEM CLEAR TRACES (<trace_type_list>)
语法元素:
<trace_type_list> ::= <trace_type> [,...]
通过在逗号分隔的列表中加入多个 trace_types,您可以同时清除多个追踪。
<trace_type> ::= <string_literal>
你可以通过设置 trace_type 为以下类型之一,有选择地清除特定的追踪文件:
描述:
你可以使用 ALTER SYSTEM CLEAR TRACES 清除追踪文件中的追踪内容。当您使用此命令所有开设了 SAP HANA 数据库的跟踪文件将被删除或清除。在分布式系统中,该命令将清除所有主机上的所有跟踪文件。
使用此命令可以减少大跟踪文件使用的磁盘空间,例如,当追踪组件设为 INFO 或 DEBUG。
你可以使用系统表 M_TRACEFILES, M_TRACEFILE_CONTENTS 各自监控追踪文件及其内容。
例子:
要清除警告的跟踪文件,使用下面的命令:
ALTERSYSTEM CLEAR TRACES(‘ALERT‘);
要清除警告和客户端跟踪文件,使用下面的命令:
ALTERSYSTEM CLEAR TRACES(‘ALERT‘, ‘CLIENT‘);
语法:
ALTER SYSTEM DISCONNECT SESSION <session_id>
语法元素:
<session_id> ::= <string_literal>
要断开连接的会话 ID。
描述:
你使用 ALTER SYSTEM DISCONNECT SESSION 来断开数据库指定的会话。在断开连接之前,与会话相关联的所有正在运行的操作将被终止。
例子:
你使用如下的命令获得空闲会话的会话 ID:
SELECT CONNECTION_ID, IDLE_TIME FROM M_CONNECTIONS WHERE CONNECTION_STATUS = ‘IDLE‘AND CONNECTION_TYPE = ‘Remote‘ORDERBY IDLE_TIME DESC
![]()
你使用如下命令断开会话连接:
ALTERSYSTEMDISCONNECT SESSION ‘400043‘
语法:
ALTER SYSTEM LOGGING <on_off>
语法元素:
<on_off> ::= ON | OFF
描述:
启动或禁用日志。
日志记录被禁用后,任何日志条目将不会持久化。当完成一个保存点,只有数据区被写入数据。
这可能会导致损失已提交的事务,当 indexserver 在加载中时被终止。在终止的情况下,你必须截断,并再次插入的所有数据。
启用日志记录后,你必须执行一个保存点,以确保所有的数据都保存,并且你必须执行数据备份,否则你将不能恢复这些数据。
只在初次加载时使用该命令!
你可以使用 ALTER TABLE ... ENABLE/DISABLE DELTA LOG 为单个列表完成操作。
语法:
ALTER SYSTEM RECLAIM DATAVOLUME [SPACE] [<host_port>] <percentage_of_overload_size>
<shrink_mode>
语法元素:
<host_port> ::= ‘host_name:port_number‘
指定服务器在持久层应减少的大小:
<percentage_of_overload_size> ::= <int_const>
指定过载的数据量应减少的百分比。
<shrink_mode> ::= DEFRAGMENT | SPARSIFY
指定持续层减少大小的策略,默认值为 DEFRAGEMENT。请注意, SPARSIFY 尚未支持,并保留以备将来使用
描述:
该命令应在持久层中未使用的空间释放时使用。 它减少数据量到过载量的 N%; 它的工作原理就像一个硬盘进行碎片整理,散落在页面的数据将被移动到数据量的前端和数据量尾端的自由空间将被截断。
如果省略了<host_port> ,该语句将持久化地分配至所有服务器。
例子:
在下面的例子中,架构中的所有服务器持久层将进行碎片整理,并减少至过载尺寸的 120%。
ALTERSYSTEM RECLAIM DATAVOLUME 120 DEFRAGMENT
语法:
ALTER SYSTEM RECLAIM LOG
描述:
当数据库中已经积累了大量的日志段时,你可以使用此命令,收回磁盘空间目前未使用的日志段。
日志段的积累,可以以多种方式引起。 例如,当自动日志备份不可长期操作或日志保存点被阻塞很长时间, 当这样的问题发生时,你只能在修复日志积累的根本原因后, 使用 ALTER SYSTEM CLAIM LOG 命令。
例子:
你回收目前未使用的日志段的磁盘空间,使用下面的命令:
ALTERSYSTEM RECLAIM LOG
语法:
ALTER SYSTEM RECLAIM VERSION SPACE
描述:
执行 MVCC 版本垃圾回收来重用资源。
语法:
ALTER SYSTEM RECONFIGURE SERVICE (<service_name>,<host>,<port>)
语法元素:
<service_name> ::= <string_literal>
你希望重新配置的服务名称。关于可用的服务类型的列表,请参阅监控视图 M_SERVICE_TYPES。
<host> ::= <string_literal>
<port> ::= <integer>
你将重新配置服务的主机和端口号。
描述:
你可以使用 ALTER SYSTEM RECONFIGURE SERVICE 通过应用当前配置参数,重新配置指定的服务。
在使用没有 RECONFIGURE 选项的 ALTER CONFIGURATION 修改多个配置参数使用该命令。参见ALTER SYSTEM ALTER CONFIGURATION。
欲重新配置特定的服务,指定<host> 和 <port>的 值, 而<service_name> 留空。
欲重新配置一种类型的所有服务,指定<service_name> 的值, 而 host> 和 <port>留空。
欲重新配置所有服务,所有参数留空。
例子:
你可以使用以下命令来重新配置 ld8520.sap.com 主机上所有使用端口号 30303 的服务:
ALTERSYSTEM RECONFIGURE SERVICE (‘‘,‘ld8520.sap.com‘,30303)
你可以使用以下命令重新配置类型 indexserver 的所有服务:
ALTERSYSTEM RECONFIGURE SERVICE (‘indexserver‘,‘‘,0)
参见 ALTER SYSTEM ALTER CONFIGURATION。
语法:
ALTER SYSTEM REMOVE TRACES (<host>, <trace_file_name_list>)
<trace_file_name_list> ::= <trace_file>,...
语法元素:
<host> :== <string_literal>
将要删除追踪记录的主机名。
<trace_file_name_list> ::= <trace_file> [,..]
你可以通过在逗号分隔的列表中添加多条 trace_file 记录,同时删除多条追踪记录。
<trace_file> :== see table below.
你可以将 trace_file 设置为以下类型之一:
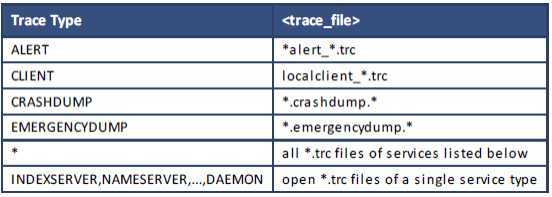
描述:
你可以使用该命令删除指定主机中的追踪文件,减少大追踪文件占用的硬盘空间。当某个服务的追踪文件已打开,则不能被删除。这种情况下,你可以使用 ALTER SYSTEM CLEAR TRACES 命令清除追踪文件。
例子:
你使用以下命令删除主机 lu873.sap.com 上所有 ALERT 追踪文件:
ALTERSYSTEM REMOVE TRACES (‘lu873.sap.com‘, ‘*alert_*.trc‘);
参见 ALTER SYSTEM CLEAR TRACES。
语法:
ALTER SYSTEM RESET MONITORING VIEW <view_name>
语法元素:
<view_name> ::= <identifier>
重设可重置监控视图的名字。
注意:不是所有监控视图可以使用该命令进行重置。可重设视图的名字后缀为"_RESET",你可以通过其名字判断是否可以重置。
描述:
你可以使用此命令重置指定的监视视图的统计数据。
你可以使用此命令来定义测量的起始点。首先,你重置监控视图,然后执行一个操作。当该操作完成后,查询监控视图"_RESET"版本获得从上次重置之后收集到的统计信息。
例子:
在以下的例子中,你重置"SYS"."M_HEAP_MEMORY_RESET"监控视图:
ALTERSYSTEMRESET MONITORING VIEW"SYS"."M_HEAP_MEMORY_RESET"
语法:
ALTER SYSTEM SAVE PERFTRACE [INTO FILE <file_name>]
语法元素:
<file_name> ::= <string_literal>
原始性能数据保存的文件。
描述:
你可以使用命令收集.prf 文件中的原始性能数据,保存该信息至.tpt 文件。 .tpt 文件保存在 SAP HANA 数据库实例的追踪文件目录中。如果你未指定文件名,则文件将保存为‘perftrace.tpt‘。
性能追踪数据文件(.tpt)可以从‘SAP HANA Computing Studio‘->Diagnosis-Files 下载,之后性能追踪可以利用 SAP HANA 实例中的 HDBAdmin 加载和分析。
监控视图:
性能文件的状态可以从 M_PERFTRACE 监控。
例子:
你可以使用如下命令将原始性能数据保存至‘mytrace.tpt‘文件:
ALTERSYSTEM SAVE PERFTRACE INTO FILE ‘mytrace.tpt‘
语法:
ALTER SYSTEM SAVEPOINT
描述:
持久层管理器上执行保存点。 保存点是一个数据库的完整连续镜像保存在磁盘上的时间点,该镜像可以用于重启数据库。
通常情况下,保存点定期执行,由[persistence]部分的参数 savepoint_interval_s 配置。 对于特殊的(通常测试)的目的,保存点可能会被禁用。在这种情况下,你可以使用此命令来手动执行保存点。
语法:
ALTER SYSTEM START PERFTRACE [<user_name>] [<application_user_name>] [PLAN_EXECUTION][FUNCTION_PROFILER] [DURATION <duration_seconds>]
语法元素:
<user_name> ::= <identifier>
限制 perftrace 收集为指定的 SQL 用户名。
<application_user_name> ::= <identifier>
限制为指定的 SQL 用户名收集 perftrace,应用用户可以通过会话变量 APPLICATIONUSER 定义。
PLAN_EXECUTION
收集计划执行细节:
FUNCTION_PROFILER
收集函数级别细节:
<duration_seconds> ::= <numeric literal>
经过 duration_seconds 后, perftrace 自动停止。如果未指定该参数,仅停止有 ALTER SYSTEM STOP PERFTRACE 的 perftrace。
描述:
开始性能追踪。
利用‘Explain Plan‘ 或 ‘Visualize Plan‘,你可以在逻辑级别查看语句的执行。利用‘Perfomance Trace‘,语句的执行将记录在线程和函数级别。
一次只能有一个 perftrace 活动。
性能追踪文件状态可以从 M_PERFTRACE 监控。
例子:
ALTERSYSTEM START PERFTRACE sql_user app_user PLAN_EXECUTION FUNCTION_PROFILER
语法:
ALTER SYSTEM STOP PERFTRACE
描述:
停止先前启动的性能追踪。停止后,需要利用 ALTER SYSTEM SAVE PERFTRACE 收集和保存性能追踪数据。
例子:
ALTERSYSTEM STOP PERFTRACE
语法:
ALTER SYSTEM STOP SERVICE <host_port> [IMMEDIATE [WITH COREFILE]]
语法元素:
<host_port> ::= <host_name:port_number> | (‘<host_name>‘,<port_number>)
将停止的服务的位置。
IMMEDIATE
立即停止(中止)服务,无需等待正常关机。
WITH COREFILE
写入 core 文件。
描述:
停止或终止单个或者多个服务。 通常,该服务将由守护进程重新启动。
修改了不能在线更改的参数之后使用。
例子:
ALTERSYSTEM STOP SERVICE ‘ld8520:30303‘
UNSET SYSTEM LICENSE ALL
语法:
描述:
删除所有已安装的许可证密钥。 使用此命令后,系统将被立即锁定,并且需要一个新的有效许可证密钥,然后才可以继续使用。执行该命令需要有 LICENSE ADMIN 权限。
例子:
UNSET SYSTEM LICENSE ALL
语法:
CONNECT <connect_option>
语法元素:
<connect_option> ::=<user_name> PASSWORD <password> | WITH SAML ASSERTION ‘<xml>‘
描述:
通过指定 user_name 和密码或者指定 SAML 断言连接数据库实例。
例子:
CONNECT my_user PASSWORD myUserPass1
语法:
SET HISTORY SESSION TO <when>
语法元素:
<when>:
用户应该指定一个确切的会话旅行的时间。
<when> ::= NOW | COMMIT ID <commit_id> | UTCTIMESTAMP <utc_timestamp>
描述:
SET HISTORY SESSION 使当前会话查看历史记录表过去的版本。用户可以指定 COMMIT ID 中的版本或 UTCTIMESTAMP 格式,或者通过指定 NOW 回到当前版本。发布带有 COMMIT ID 或UTCTIMESTAMP 的 SET HISTORY SESSION 之后,当前会话中看到了一个旧版本的历史记录表,而不能写进系统任何东西。如果给定了 NOW 选项,当前会话恢复到一个正常的会话,看到当前版本的历史记录表,并能写入系统。 此命令只适用于历史记录表,普通表的可见性不会受到影响。
例子:
SELECT CURRENT_UTCTIMESTAMP FROM SYS.DUMMY
SELECT LAST_COMMIT_ID FROM M_HISTORY_INDEX_LAST_COMMIT_ID WHERE SESSION_ID =
CURRENT_CONNECTION COMMIT
SET HISTORY SESSION TO UTCTIMESTAMP ‘2012-03-09 07:01:41.428‘
SET HISTORY SESSION TO NOW
语法:
SET SCHEMA <schema_name>
描述:
你可以修改会话的当前schema。 如果表前不限制schema,则使用当前用户的schema。
语法:
SET [SESSION] <key> = <value>
(SESSION选项可以省略)
语法元素:
<key> ::= <string_literal>
会话变量的键值,最大长度为 32 个字符。
<value> ::= <string_literal>
会话变量的期望值,最大长度为 512 个字符。
描述:
你可以使用该命令设置你数据库会话的会话变量,通过提供键值对。
注意:有几个只读会话变量,你不能使用该命令修改值: APPLICATION, APPLICATIONUSER,TRACEPROFILE。
会话变量可以使用 SESSION_CONTEXT 函数获得,使用 UNSET [SESSION]命令取消设置。
例子:
SET‘MY_VAR‘ = ‘dummy‘;
SELECT SESSION_CONTEXT(‘MY_VAR‘) FROM dummy;
![]()
UNSET ‘MY_VAR‘;
语法:
UNSET [SESSION] <key>
语法元素:
<key> ::= <string_literal>
会话变量的键值,最大长度为 32 个字符。
描述:
你可以使用 UNSET [SESSION]取消设置当前会话的会话变量。
注意:有几个只读会话变量,你不能使用该命令修改值: APPLICATION, APPLICATIONUSER,TRACEPROFILE。
例子:
SET‘MY_VAR‘= ‘dummy‘;
SELECT SESSION_CONTEXT(‘MY_VAR‘) FROM dummy;
UNSET ‘MY_VAR‘;
语法:
COMMIT
描述:
该系统支持事务一致性,保证了当前作业是完全应用到系统中或者弃用。如果用户希望持久地应用当前作业至系统中,用户应使用 COMMIT 命令。 如果 COMMIT 命令发出后,并成功处理,任何改变将应用到当前事务完成的系统中,改变也将对其他未来开始的作业可见。通过 COMMIT 命令已经承诺的工作,将不能恢复。 分布式系统中,遵守标准的两阶段提交协议。在第一阶段, 事务处理协调器将询问每一位参与者是否准备提交,并将结果发送到第二阶段的参与者。 COMMIT 命令只适用于‘autocommit‘的禁用会话。
例子:
COMMIT
语法:
LOCK TABLE <table_name> IN EXCLUSIVE MODE [NOWAIT]
描述:
LOCK TABLE 命令显式地尝试获取表的互斥锁。如果指定了 NO WAIT 选项, 其只是试图获得表的锁。如果指定了 NOWAIT 选项不能获得锁,将返回一个错误代码,但是当前事务将回滚。
例子:
LOCKTABLE t1 INEXCLUSIVEMODE NOWAIT
语法:
ROLLBACK
描述:
该系统支持事务一致性,保证了当前作业是完全应用到系统中或者弃用。在事务的中间过程, 可以显式恢复,因为由于 ROLLBACK 命令,事务尚未执行。发布 ROLLBACK 命令后, 将完全恢复事务系统做的任何变化,当前会话将处于闲置状态。 ROLLBACK 命令只适用于‘autocommit‘的禁用会话。
例子:
ROLLBACK
语法:
SET TRANSACTION <isolation_level> | <transaction_access_mode>
语法元素:
isolation_level ::= ISOLATION LEVEL <level>
隔离级别设置数据库中的数据语句级读一致性。如果省略了 isolation_level,默认值为 READ COMMITTED。
level ::= READ COMMITTED(提交读取) | REPEATABLE READ(可重复读) | SERIALIZABLE(序列化读)
READ COMMITTED
READ COMMITTED 隔离级别提供事务过程中语句级别读一致性。 在语句开始执行时,事务中的每条语句都能看到已提交状态的数据。这意味着在同一事务中,每个语句可能会看到执行时数据库中不同的快照,因为数据可以在事务中提交。
REPEATABLE READ/SERIALIZABLE
REPEATABLE READ/SERIALIZABLE 隔离级别提供了事务级快照隔离。事务所有语句共享数据库同样的快照。该快照包含所有已提交的事务开始的时间以及事务本身的修改。
transaction_access_mode ::= READ ONLY | READ WRITE
SQL 事务访问模式控制事务是否可以在执行期间修改数据。如果省略了transaction_access_mode,默认值为 READ ONLY。
READ ONLY
如果设置了 READ ONLY 访问模式,则只允许只读的 SELECT 语句。如果在这种模式下尝试更新或插入操作,会抛出一个异常。
READ WRITE
如果设置了 READ WRITE 访问模式,在一个事务中的语句可以按需自由地读取或更改数据库的数据。
描述:
SAP HANA 数据库使用多版本并发控制 (MVCC) 确保读取操作的一致性(提交读取隔离级别+MVCC,可以解决数据不可重复读的问题)。并发的读操作不阻塞并发写操作数据库中的数据的一致视图。并发的读操作不阻塞并发写数据库数据的一致视图。更新操作通过插入数据的新版本而不是覆盖已有数据执行。
指定的隔离级别确定将要使用的锁操作类型。系统同时支持语句级快照隔离和事务级快照隔离。
? 对于语句级快照隔离,使用READ COMMITED。
? 对于事务级快照隔离,使用REPEATABLE READ 或者 SERIALIZABLE。
在一个事务中,当记录被插入、更新或删除时,系统对事务执行中,受影响的记录设置互斥锁的持续时间,也对受影响的表设置锁。这样可以保证当表中的记录正在更新时,该表不会被删除或更改。数据库在事务结束时释放这些锁。
注意:读取操作不设置任何数据库中表或行的锁,无论使用何种隔离级别。
数据定义语言和事务隔离
数据定义语言(DDL) 语句(CREATE TABLE, DROP TABLE, CREATE VIEW, etc )总是立即对随后的 SQ 语句生效,无论使用何种隔离级别。对于这种行为的一个例子,请考虑下面的顺序:
1. 一个长期运行 SERIALIZABLE 的隔离事务在表 C 开始操作。
2. 一些 DDL 语句在事务外运行,添加一列新列至表 C。
3. 在 SERIALIZABLE 隔离事务内,只要 DDL 语句执行完毕,新生成的列可以要访问。访问发生不论使用何种隔离级别。
例子:
SETTRANSACTION READ COMMITTED;
l Read Uncommited(未提交读):没有提交就可以读取到数据(发出了Insert,但没有commit就可以读取到。)很少用。在该隔离级别,所有事务都可以看到其他未提交事务的执行结果。本隔离级别很少用于实际应用,因为它的性能也不比其他级别好多少。读取未提交的数据,也被称之为脏读(Dirty Read)。
l Read Commited(提交读):只有提交后才可以读,常用。这是大多数数据库系统的默认隔离级别(但不是MySQL默认的,MySql默认为可重复读)。它满足了隔离的简单定义:一个事务只能看见已经提交事务所做的改变。解决了脏读问题。
l Repeatable Read(可重复读):mysql默认级别, 必需提交才能见到,读取数据时数据被锁住。它确保同一事务的多个实例在并发读取数据时,会看到同样的数据行。不过理论上,这会导致另一个棘手的问题:幻读 (Phantom Read)。简单的说,幻读指当用户读取某一范围的数据行时,另一个事务又在该范围内插入了新行,当用户再读取该范围的数据行时,会发现有新的“幻影” 行。InnoDB和Falcon存储引擎通过多版本并发控制(MVCC,Multiversion Concurrency Control)机制解决了该问题。解决了不可重复读的问题
l Serialiazble(序列化读):最高隔离级别,串型的,你操作完了,我才可以操作,并发性特别不好。这是最高的隔离级别,它通过强制事务排序,使之不可能相互冲突,从而解决幻读问题。简言之,它是在每个读的数据行上加上共享锁。在这个级别,可能导致大量的超时现象和锁竞争。
|
隔离级别 |
是否存在脏读 |
是否存在不可重复读 |
是否存在幻读 |
|
Read Uncommitted(未提交读) |
Y |
Y |
Y |
|
Read Commited(提交读) |
N |
Y(可采用悲观锁解决) |
Y |
|
Repeatable Read(可重复读) |
N |
N |
Y |
|
Serialiazble(序列化读) |
N |
N |
N |
事务并发时可能出现问题:脏读、不可重复读、幻读
脏读:没有提交就可以读取到数据称为脏读
不可重复读:再重复读一次,数据与你上的不一样。称不可重复读。
幻读:在查询某一条件的数据,开始查询的后,别人又加入或删除些数据,再读取时与原来的数据不一样了。
脏读(Drity Read):某个事务已更新一份数据,另一个事务在此时读取了同一份数据,由于某些原因前一个RollBack了操作,则后一个事务所读取的数据就会是不正确的。
不可重复读(Non-repeatable read):在一个事务的两次查询之中数据不一致,这可能是两次查询过程中间插入了一个事务更新的原有的数据。
幻读(Phantom Read):在一个事务的两次查询中数据笔数不一致,例如有一个事务查询了几行(Row)数据,而另一个事务却在此时插入了新的几行数据,先前的事务在接下来的查询中,就会发现有几列数据是它先前所没有的。
设置 JDBC 事务隔离级别(注意多数数据库都不支持所有的隔离级别):
1 java.sql.Connection.TRANSACTION_READ_COMMITTED
2 java.sql.Connection.TRANSACTION_READ_UNCOMMITTED
4 java.sql.Connection.TRANSACTION_REPEATABLE_READ
8 java.sql.Connection.TRANSACTION_SERIALIZABLE
一般我们将级别设置为1(提交读)级别后,再通过程序的方式来避免“不可重复读”问题。
如果我们在Hibernate中没有设置数据库的隔离级别,则默认是依赖于数据库的,所以我们最好设置。
银行系统需要将数据库的隔离级别设置成“可重复读”。
悲观锁:具有排他性(我锁住当前数据后,别人看到不此数据)
悲观锁一般由数据机制来做到的。select ... for update
通常依赖于数据库机制,在整修过程中将数据锁定,其它任何用户都不能读取或修改(如:必需我修改完之后,别人才可以修改)
悲观锁一般适合短事务比较多(如某一数据取出后加1,立即释放)
长事务占有时间(如果占有1个小时,那么这个1小时别人就不可以使用这些数据),不常用。
 |
用户1、用户2 同时读取到数据,但是用户2先 -200,这时数据库里的是800,现在用户1也开始-200,可是用户1刚才读取到的数据是1000,现在用户用刚刚一开始读取的数据1000-200为800,而用户1在更新时数据库里的是用房更新的数据800,按理说用户1应该是800-200=600,而现在是800,这样就造成的更新丢失。这种情况该如何处理呢,可采用两种方法:悲观锁、乐观锁。先看看悲观锁:用户1读取数据后,用锁将其读取的数据锁上,这时用户2是读取不到数据的,只有用户1释放锁后用户2才可以读取,同样用户2读取数据也锁上。这样就可以解决更新丢失的问题了。
乐观锁:不是锁,是一种冲突检测机制,如Hibernate就是这样。
乐观锁的并发性较好,因为我改的时候,别人随边修改。
乐观锁的实现方式:常用的是版本的方式(每个数据表中有一个版本字段version,某一个用户更新数据后,版本号+1,另一个用户修改后再+1,当用户更新发现数据库当前版本号与读取数据时版本号不一致(等于小于数据库当前版本号),则更新不了。
为了确保并发用户在存取同一数据库对象时的正确性(即无丢失修改、可重复读、不读“脏”数据),数据库中引入了锁机制。基本的锁类型有两种:排它锁(exclusive locks 记为x 锁)和共享锁(share locks记为 s锁)。加锁是实现数据库并发控制的一个非常重要的技术。当事务在对某个数据对象进行操作前,先向系统发出请求,对其加锁。加锁后事务就对该数据对象有了一定的控制,在该事务释放锁之前,其他的事务不能对此数据对象进行更新操作。
排它锁:若事务t对数据d加x锁,则其它任何事务都不能再对d加任何类型的锁,直至t 释放d 上的x 锁;一般要求在修改数据前要向该数据加排它锁,所以排它锁又称为写锁。
共享锁:若事务t对数据d加s 锁,则其它事务只能对d加 s锁,而不能加x 锁,直至t 释放d 的s 锁;一般要求在读取数据前要向该数据加共享锁,所以共享锁又称为读锁。
锁在用户修改之前就发挥作用:
Select ..for update(nowait)
Select * from tab1 for update
用户发出这条命令之后,oracle将会对返回集中的数据建立行级封锁,以防止其他用户的修改。
如果此时其他用户对上面返回结果集的数据进行dml或ddl操作都会返回一个错误信息或发生阻塞。
1:对返回结果集进行update或delete操作会发生阻塞。
2:对该表进行ddl操作将会报:Ora-00054:resource busy
and acquire with nowait specified.
原因分析
此时Oracle已经对返回的结果集上加了排它的行级锁,所有其他对这些数据进行的修改或删除操作都必须等待这个锁的释放,产生的外在现象就是其他的操作将发生阻塞,这个这个操作commit或rollback.
同样这个查询的事务将会对该表加表级锁,不允许对该表的任何ddl操作,否则将会报出ora-00054错误::resource busy and acquire with
nowait specified.
乐观的认为数据在select出来到update进取并提交的这段时间数据不会被更改。这里面有一种潜在的危险就是由于被选出的结果集并没有被锁定,是存在一种可能被其他用户更改的可能。因此Oracle仍然建议是用悲观封锁,因为这样会更安全。乐观锁一般通过程序版本控制来实现,如Hibernate
定义:
当一个会话保持另一个会话正在请求的资源上的锁定时,就会发生阻塞。被阻塞的会话将一直挂起,直到持有锁的会话放弃锁定的资源为止。4个常见的dml语句会产生阻塞
INSERT
UPDATE
DELETE
SELECT…FOR UPDATE
INSERT
Insert发生阻塞的唯一情况就是用户拥有一个建有主键约束的表。当2个的会话同时试图向表中插入相同的数据时,其中的一个会话将被阻塞,直到另外一个会话提交或会滚。一个会话提交时,另一个会话将收到主键重复的错误。回滚时,被阻塞的会话将继续执行。
UPDATE 和DELETE当执行Update和delete操作的数据行已经被另外的会话锁定时,将会发生阻塞,直到另一个会话提交或会滚。
Select …for update
当一个用户发出select..for update的错作准备对返回的结果集进行修改时,如果结果集已经被另一个会话锁定,就是发生阻塞。需要等另一个会话结束之后才可继续执行。可以通过发出 select… for update nowait的语句来避免发生阻塞,如果资源已经被另一个会话锁定,则会返回以下错误:Ora-00054:resource busy and acquire with nowait specified.
定义:当两个用户希望持有对方的资源时就会发生死锁.
即两个用户互相等待对方释放资源时,oracle认定为产生了死锁,在这种情况下,将以牺牲一个用户作为代价,另一个用户继续执行,牺牲的用户的事务将回滚.
例子:
1:用户1对A表进行Update,没有提交。
2:用户2对B表进行Update,没有提交。
此时双反不存在资源共享的问题。
3:如果用户2此时对A表作update,则会发生阻塞,需要等到用户一的事物结束。
4:如果此时用户1又对B表作update,则产生死锁。此时Oracle会选择其中一个用户进行会滚,使另一个用户继续执行操作。
起因:
Oracle的死锁问题实际上很少见,如果发生,基本上都是不正确的程序设计造成的,经过调整后,基本上都会避免死锁的发生。
ALTER SAML PROVIDER <saml_provider_name> WITH SUBJECT <subject_name> ISSUER <issuer_distinguished_name>
语法元素:
<subject_name> ::=
<string_literal>
<issuer_distinguished_name> ::=
<string_literal>
描述:
ALTER SAML PROVIDER 语句修改 SAP HANA 数据库已知的 SAML 提供商的属性。
<saml_provider_name> 必须是一个现有的 SAML 提供商。只有拥有系统权限 USER ADMIN 的数据库
用户允许修改 SAML 提供商。
<subject_name> 以及 <issuer_distinguished_name>是 SAML 身份提供程序中证书对应的名字。
系统和监控视图:
SAML_PROVIDER:显示所有 SAML 提供商主题名和 issuer_name。
语法:
ALTER USER <user_name> <alter_user_option>
语法元素:
<alter_user_option> ::=PASSWORD <password> [<user_parameter_option>]
| <user_parameter_option>
| IDENTIFIED EXTERNALLY AS <external_identity> [<user_parameter_option>]
| RESET CONNECT ATTEMPTS
| DROP CONNECT ATTEMPTS
| DISABLE PASSWORD LIFETIME
| FORCE PASSWORD CHANGE
| DEACTIVATE [USER NOW]
| ACTIVATE [USER NOW]
| DISABLE <authentication_mechanism>
| ENABLE <authentication_mechanism>
| ADD IDENTITY <provider_identity>...
| ADD IDENTITY <external_identity> FOR KERBEROS
| DROP IDENTITY <provider_info>...
| DROP IDENTITY FOR KERBEROS
| <string_literal>
<authentication_mechanism> ::= PASSWORD | KERBEROS | SAML
<provider_identity> ::=<mapped_user_name> FOR SAML PROVIDER <saml_provider_name>| <external_identity> FOR KERBEROS
<mapped_user_name> ::=ANY | <string_literal>
<saml_provider_name> ::=<simple_identifier>
<provider_info> ::= FOR SAML PROVIDER <saml_provider_name>
<password> ::=<letter_or_digit>...
<user_parameter_option> ::=<set_user_parameters> [<clear_user_parameter_option>] | <clear_user_parameter_option>
<set_user_parameters> ::=SET PARAMETER CLIENT = <string_literal>
<clear_user_parameter_option> ::=CLEAR PARAMETER CLIENT| CLEAR ALL PARAMETERS
<external_identity> ::=<simple_identifier>
描述:
ALTER USER 语句修改数据库用户。 <user_name>必须指定一个现有的数据库用户。
每个用户可以为自己执行 ALTER USER。但并非所有<alter_user_option>可以由用户自己指定。对于<alter_user_option>其他用户,只有拥有系统权限 USER ADMIN 权限的用户可以执行 ALTER USER。
使用 PASSWORD 创建的用户不能修改为 EXTERNALLY,反之亦然。但他们的<password>或者<external_identity>是可以修改的。
你可以使用此命令更改用户的密码。密码的修改必须遵循当前数据库定义的规则,包括最小密码长度和定义的字符类型(大写、小写、数字、特殊字符)必须是密码的一部分。用户根据指定数据库实例定义的策略,必须定期更换密码,或者由首次连接到数据库实例的用户,自己更改密码。
你可以更改外部认证。外部用户使用外部系统需要进行身份验证,例如, Kerberos 系统。这些用户没有密码,但是有 Kerberos 实体名称。有关外部身份的详细信息,请联系您的域管理员。
<user_parameter_option>可以用来设置、修改或者清除用户参数 CLIENT。
<set_user_parameters>用来为数据库中的用户设置用户参数 CLIENT。
当使用报表时,该用户参数 CLIENT 可以用于限制用户 <user_name>访问有关特定客户端的信息。
<user_parameter_option>不能由用户自己指定。
如果在成功连接(正确的用户/密码组合)前,达到参数 MAXIMUM_INVALID_CONNECT_ATTEMPTS(参见监控视图 M_PASSWORD_POLICY)定义的错误次数,用户将在允许重新连接前,被锁定几分钟。拥有系统权限 USER ADMIN 的用户或者用户自己,可以使用命令 ALTER USER <user_name>
RESET CONNECT ATTEMPTS 可以删除已发生的无效连接尝试的信息。
拥有系统权限 USER ADMIN 的用户可以使用命令 ALTER USER <user_name> DISABLE PASSWORD
LIFETIME 排除用户<user_name>的所有密码生命周期检查。这应该只为技术用户使用,而非正常的数据库用户。
拥有系统权限 USER ADMIN 的用户可以使用命令 ALTER USER <user_name> FORCE PASSWORD CHANGE 强制用户<user_name>在下次连接后立即修改密码,然后才可以正常工作。
拥有系统权限 USER ADMIN 的用户可以使用命令 ALTER USER <user_name> DEACTIVATE USER NOW关闭/锁定用户<user_name>的账号。用户<user_name>的账号关闭/锁定之后,用户将不能连接到
SAP HANA 数据库。欲重新激活/解锁用户<user_name>,系统权限 USER ADMIN 用户使用命令USER <user_name> ACTIVATE USER NOW,或者,在用户使用 PASSWORD 身份验证机制的情况下,使用 ALTER USER <user_name> PASSWORD <password>重设用户密码。
拥有系统权限 USER ADMIN 的用户可以使用命令 ALTER USER <user_name> ACTIVATE USER NOW 重新激活/解锁之前已经关闭的用户<user_name>账号。
配置参数:
有关密码的配置参数,可以查看监控视图 M_PASSWORD_POLICY。这些参数存储在
indexserver.ini, ‘password policy‘部分中。相关的参数描述可以在 SAP HANA 安全指南,附录,密码策略参数中找到。
系统和监控视图:
USERS: 显示所有用户、用户的创建者、创建时间和当前状态的信息。
USER_PARAMETERS:显示定义的 user_parameters,目前只提供 CLIENT。
INVALID_CONNECT_ATTEMPTS:显示每个用户无效连接的尝试次数。
LAST_USED_PASSWORDS: 显示用户上次密码修改日期。
M_PASSWORD_POLICY:显示描述密码所允许的样式的配置参数及其生命周期。
例子:
在可能使用给定的密码连接数据库以及已有的 SAML 提供商 OUR_PROVIDER 断言之前,用户名为NEW_USER 的用户已经创建完成。由于断言将提供数据库用户名, <mapped_user_name>设为ANY。这由如下的语句完成:
CREATEUSER new_user PASSWORD Password1 WITHIDENTITYANYFOR SAML PROVIDER OUR_PROVIDER;
现在,该用户将被强制修改密码,用户被禁止使用 SAML。
ALTERUSER new_user FORCE PASSWORD CHANGE;
ALTERUSER new_user DISABLE SAML;
假设用户已经过于频繁的尝试一个错误的密码,管理员将重置无效的连接尝试数为零。
ALTERUSER new_user RESETCONNECT ATTEMPTS;
用户 new_user 应当允许使用 KERBEROS 机制进行身份验证。因此,需要定义该连接的外部身份。
ALTERUSER new_user ADDIDENTITY‘testkerberosName‘FOR KERBEROS;
ALTERUSER new_user ENABLE KERBEROS;
另一方面,用户 new_user 将放松使用 SAML 提供商 OUR_PROVIDER 断言的可能性。
ALTERUSER new_user DROPIDENTITYFOR SAML PROVIDER OUR_PROVIDER;
最后,管理员希望禁止此用户 new_user 的所有连接,因为他最近执行的可疑操作。
ALTERUSER new_user DEACTIVATE;
语法:
CREATE ROLE <role_name>
语法元素:
<role_name> ::= <identifier>
描述:
CREATE ROLE 语句创建一个新的角色。
只有拥有系统权限 ROLE ADMIN 的用户可以创建新角色。
指定的角色名称不能与现有用户或角色的名称相同。
角色是权限的一个命名集合,可以授予一个用户或角色。如果你想允许多个数据库用户执行相同的操作,你可以创建一个角色,授予该角色所需的权限,并将角色授予不同的数据库用户。
每个用户允许将权限授予一个已有的角色,但只有只有拥有系统权限 ROLE ADMIN 的用户可以将角色授予角色和用户。
SAP HANA 数据库提供了四种角色:
PUBLIC:每个数据库用户默认已被授予该角色。
该角色包括只读访问系统视图、监控视图和一些存储过程的执行权限。这些权限可以被撤销。
该角色可以授予过后将被撤销的权限。
MODELING:该角色包含使用 SAP HANA Studio 信息建模器所需的权限。
CONTENT_ADMIN:该角色包含与 MODELING 角色相同的角色,但是使用扩展该角色将被允许授予其他用户这些权限。此外,它包含了与导入对象工作的元库权限。
MONITORING:该角色包含所有元数据、当前的系统状态、监控视图和服务器统计数据的只读访问。
系统和监控视图:
ROLES:显示所有角色、它们的创建者和创建时间。
GRANTED_ROLES:显示每个用户或角色被授予的角色。
GRANTED_PRIVILEGES:显示每个用户或角色被授予的权限。
例子:
创建名称为 role_for_work_on_my_schema 的角色。
CREATE ROLE role_for_work_on_my_schema;
语法:
CREATE SAML PROVIDER <saml_provider_name> WITH SUBJECT <subject_distinguished_name> ISSUER <issuer_distinguished_name>
描述:
CREATE SAML PROVIDER 语句定义 SAP HANA 数据库已知的 SAML 提供商。 <saml_provider_name>必须与已有的 SAML 提供商不同。
只有拥有系统权限 USER ADMIN 的用户可以创建 SAML 提供商,每个有该权限的用户允许删除任何 SAML 提供商。
需要一个现有的 SAML 提供商,能够为用户指定 SAML 连接。 <subject_distinguished_name> 和<issuer_distinguished_name>是 SAML 提供商使用的 X.509 证书的主题和发布者的 X.500 可分辨名字。这些名字的语法可以在 ISO/IEC 9594-1 中找到。
SAML 概念的详细细节可以在 Oasis SAML 2.0 中找到。
系统和监控视图:
SAML_PROVIDERS:显示所有 SAML 提供商主题名和发布者名字。
例子:
创建一个名称为 gm_saml_provider 的 SAML 提供商,指定主题和发布者所属的公司。
CREATE SAML PROVIDER gm_saml_provider WITH SUBJECT ‘CN = wiki.detroit.generalmotors.corp,OU = GMNet,O = GeneralMotors,C = EN‘
ISSUER ‘E = John.Do@gm.com,CN = GMNetCA,OU = GMNet,O = GeneralMotors,C = EN‘;
语法:
CREATE USER <user_name> [PASSWORD <password>] [IDENTIFIED EXTERNALLY AS <external_identity>] [WITH IDENTITY <provider_identity>...] [<set_user_parameters>]
语法元素:
<external_identity> ::=<simple_identifier> | <string_literal>
<provider_identity> ::=<mapped_user_name> FOR SAML PROVIDER <saml_provider_name> | <external_identity> FOR KERBEROS
<mapped_user_name> ::=ANY | <string_literal>
<saml_provider_name> ::=<simple_identifier>
<set_user_parameters> ::=SET PARAMETER CLIENT = <string_literal>
描述:
CREATE USER 创建一个新的数据库用户。
只有拥有系统权限 USER ADMIN 的用户可以创建另一个数据库用户。
指定的用户名必须不能与已有的用户名、角色名或集合名相同。
SAP HANA 数据库提供的用户有: SYS, SYSTEM, _SYS_REPO,_SYS_STATISTICS。
数据库中的用户可以通过不同的机制进行身份验证,内部使用密码的身份验证机制和而外部则使用 Kerberos 或 SAML 等机制验证。用户可以同时使用不止一种方式进行身份验证,但在同一时间,只有一个密码和一个外部识别有效。与之相反的是,同一时间可以有一个以上<provider_identity>为一个用户存在。至少需指定一种验证机制允许用户连接和在数据库实例上工作。
由于兼容性原因,语法 IDENTIFIED EXTERNALLY AS <external_identity>以及<external_identity> FORKERBEROS 会继续使用。
密码必须遵循当前数据库定义的规则。密码的修改必须遵循当前数据库定义的规则,包括最小密码长度和定义的字符类型(大写、小写、数字、特殊字符)必须是密码的一部分.用户根据指定数据库实例定义的策略,必须定期更换密码。在执行 CREATE USER 命令期间提供的密码将被视为已提供, <user_name>将会修改为大写作为每个<simple_identifier>。
外部用户使用外部系统进行身份验证,例如 Kerberos 系统。这些用户没有密码,但是有 Kerberos实体名称。有关外部身份的详细信息,请联系您的域管理员。
如果 ANY 作为映射的用户名, SAML 断言将包含断言生效的数据库用户名。 <saml_provider_name>必须指定一个已有的 SAML 提供商。
<set_user_parameters>可以用于为数据库中的用户设置用户参数 CLIENT。
当使用报表时,该用户参数 CLIENT 可以用于限制用户 <user_name>访问有关特定客户端的信息。
<user_parameter_option>不能由用户自己指定。
对于每个数据库用户,数据集合将以包含用户名方式创建。这是不能显式删除。用户删除时,该集合也将被删除。数据库用户拥有该集合,并当他不显式指定集合名称时,作为自己的默认集合使用。
配置参数:
与密码相关的配置参数可以在监控视图 M_PASSWORD_POLICY 查看。这些参数存储 indexserver.ini的‘password policy‘部分中。相关的参数描述可以在 SAP HANA 安全指南,附录,密码策略参数中找到。
系统和监控视图:
USERS: 显示所有用户、用户的创建者、创建时间和当前状态的信息。
USER_PARAMETERS:显示定义的 user_parameters,目前只提供 CLIENT。
INVALID_CONNECT_ATTEMPTS:显示每个用户无效连接的尝试次数。
LAST_USED_PASSWORDS: 显示用户上次密码修改日期。
M_PASSWORD_POLICY:显示描述密码所允许的样式的配置参数及其生命周期。
SAML_PROVIDERS;显示已有的 SAML 提供商。
SAML_USER_MAPPING:显示每个 SAML 提供商的映射用户名。
例子:
在可能使用给定的密码连接数据库以及已有的 SAML 提供商 OUR_PROVIDER 断言之前,用户名为NEW_USER 的用户已经创建完成。由于断言将提供数据库用户名, <mapped_user_name>设为ANY。 这由如下的语句完成:
CREATEUSER new_user PASSWORD Password1 WITHIDENTITYANYFOR SAML PROVIDER OUR_PROVIDER;
语法:
DROP ROLE <role_name>
例子:
DROP ROLE 语句删除角色。 <drop_name>必须指定已经存在的角色。
只有拥有系统权限 ROLE ADMIN 的用户可以删除角色。任何有该权限的用户允许删除任意角色。
只有 SAP HANA 提供的角色可以删除: PUBLIC, CONTENT_ADMIN, MODELING and MONITORING。
如果一个角色授予用户或角色,在角色删除时将被撤销。撤销角色可能会导致一些视图无法访问或者存储过程再也不工作,如果一个视图或存储过程依赖于该角色中的任意权限,会发生这种情况。
系统和监控视图:
ROLES:显示所有角色、它们的创建者和创建时间。
GRANTED_ROLES:显示每个用户或角色被授予的角色。
GRANTED_PRIVILEGES:显示每个用户或角色被授予的权限。
例子:
创建名为 role_for_work_on_my_schema 的角色,随后立即删除。
CREATE ROLE role_for_work_on_my_schema;
DROP ROLE role_for_work_on_my_schema;
语法:
DROP SAML PROVIDER <saml_provider_name>
描述:
DROP SAML PROVIDER 语句删除指定的 SAML 提供商。 <saml_provider_name>必须是一个已有的SAML 提供商。如果指定的 SAML 提供商正在被 SAP HANA 用户使用,则该提供商不能被删除。
只有拥有系统 USER ADMIN 权限的用户可以删除 SAML 提供商。
系统和监控视图:
SAML_PROVIDERS:显示所有 SAML 提供商主题名称和 issuer_name。
语法:
DROP USER <user_name> [<drop_option>]
语法元素:
<drop_option> ::= CASCADE | RESTRICT
Default = RESTRICT
描述:
DROP USER 语句删除数据库用户。 <user_name>必须指定一个已有的数据库用户。
只有拥有系统 USER ADMIN 权限的用户可以删除用户。拥有该权限的用户可以删除任何用户。 SAPHANA 数据库提供的用户不能删除: SYS, SYSTEM, _SYS_REPO,_SYS_STATISTICS。
如果显式或隐式指定了<drop_option> RESTRICT,则当用户为数据集合的所有者或以及创建了其他集合,或者该用户集合下存有非本人创建的对象时,该用户不能被删除。
如果指定了<drop_option> CASCADE,包含用户名的集合和属于该用户的集合,连同所有存在这些集合中的对象(即使是由其他用户创建)一起删除。用户拥有的对象,即使为其他集合中的一部分,将被删除。依赖于已删除对象的对象将被删除,即使已删除的用户所拥有的公共同义词。
已删除对象的权限将被撤销,授予已删除用户的权限也将被撤销。撤销权限可能会造成更多的撤销操作,如果这些权限被进一步授予。
已删除用户创建的用户和由他们创建的角色将不会被删除。已删除的用户创建的审核策略也不会被删除。
如果用户存在一个已打开的会话,仍然可以删除该用户。
系统和监控视图:
已删除用户将从以下视图删除:
USERS: 显示所有用户、用户的创建者、创建时间和当前状态的信息。
USER_PARAMETERS:显示定义的 user_parameters,目前只提供 CLIENT。
INVALID_CONNECT_ATTEMPTS:显示每个用户无效连接的尝试次数。
LAST_USED_PASSWORDS: 显示用户上次密码修改日期。
M_PASSWORD_POLICY:显示描述密码所允许的样式的配置参数及其生命周期。
对象的删除可能影响所有描述对象的系统视图,例如 TABLES, VIEWS,PROCEDURES, ... .
对象的删除可能影响描述权限的视图:例如 GRANTED_PRIVILEGES 以及所有监控视图,例如M_RS_TABLES, M_TABLE_LOCATIONS, ...
例子:
例如,使用这条语句创建名称为 NEW_USERd 的用户:
CREATEUSER new_user PASSWORD Password1;
已有的用户 new_user 将被删除,连同其所有对象一起:
DROPUSER new_user CASCADE;
语法:
GRANT <system_privilege>,... TO <grantee> [WITH ADMIN OPTION] | GRANT <schema_privilege>,... ON SCHEMA <schema_name> TO <grantee> [WITH GRANT OPTION]| GRANT <object_privilege>,... ON <object_name> TO <grantee> [WITH GRANT OPTION] | GRANT <role_name>,... TO <grantee> [WITH ADMIN OPTION]| GRANT STRUCTURED PRIVILEGE <privilege_name> TO <grantee>
语法元素:
<system_privilege> ::=AUDIT ADMIN | BACKUP ADMIN| CATALOG READ
| CREATE SCENARIO| CREATE SCHEMA | CREATE STRUCTURED PRIVILEGE| DATA ADMIN |
EXPORT| IMPORT
| INIFILE ADMIN| LICENSE ADMIN | LOG ADMIN| MONITOR ADMIN | OPTIMIZER ADMIN|
RESOURCE ADMIN | ROLE ADMIN| SAVEPOINT ADMIN | SCENARIO ADMIN| SERVICE ADMIN |
SESSION ADMIN| STRUCTUREDPRIVILEGE ADMIN | TRACE ADMIN| USER ADMIN | VERSION
ADMIN| <identifier>.<identifier>
系统权限用来限制管理任务。定义如下的系统权限:
AUDIT ADMIN
该权限控制以下审计有关命令的执行: CREATE AUDIT POLICY, DROP AUDIT POLICY and ALTER AUDIT POLICY.
BACKUP ADMIN
该权限授权 ALTER SYSTEM BACKUP 命令来定义和启动备份进程或执行恢复过程。
CATALOG READ
该权限赋予所有用户未经过滤的只读访问所有的系统和监控视图。正常情况下,这些视图的内容根据正在访问用户的权限过滤。权限 CATALOG READ 使用户有只读访问所有的系统和监控视图的内容。
CREATE SCENARIO
该权限控制计算场景和多维数据集(数据库计算)的创建。
CREATE SCHEMA
该权限控制使用 CREATE SCHEMA 命令创建数据库数据集合。每个用户都有个集合。拥有该权限,用户允许创建更多的集合。
CREATE STRUCTURED PRIVILEGE
该权限授权创建结构化权限(分析权限)。注意,只有分析权限的所有者可以进一步授予其他用户或者角色,以及撤销。
DATA ADMIN
该强大的权限授权读取系统和监控视图中的所有数据,包括在 SAP HANA 数据库中执行 DDL (DataDefinition Language) 以及 DDL 命令。这表示拥有该权限的用户不能选择或者修改存储在其他用户表中的数据,但是可以修改表的定义或甚至删除该表。
EXPORT
该权限授权通过 EXPORT TABLE 命令导出数据库中的活动。注意,除了该权限,用户仍需要将要导出的源表 SELECT 权限。
IMPORT
该权限授权通过 IMPORT TABLE 命令导入数据库中的活动。注意,除了该权限,用户仍需要将要导入的目标表 SELECT 权限。
INIFILE ADMIN
该权限授权修改系统设置的不同方式。
LICENSE ADMIN
该权限授权 SET SYSTEM LICENSE 命令安装一个新的许可。
LOG ADMIN
该权限授权 ALTER SYSTEM LOGGING [ON|OFF] 命令启用或禁用 刷新日志机制。
MONITOR ADMIN
该权限授权关于 EVENT 的 ALTER SYSTEM 命令。
OPTIMIZER ADMIN
该权限授权关于 SQL PLAN CACHE 和 ALTER SYSTEM 的 ALTER SYSTEM 命令。
UPDATE STATISTICS 命令影响查询优化器的行为。
RESOURCE ADMIN
该权限授权关于资源,例如 ALTER SYSTEM RECLAIM、 DATAVOLUME 和 ALTER SYSTEM RESET
MONITORING VIEW 的命令,并且授权 Management Console 中的许多命令。
ROLE ADMIN
该权限授权使用 CREATE ROLE 命令创建和删除角色。同时也授权使用 GRANT 和 REVOKE 命令授予和撤销角色。
SAVEPOINT ADMIN
该权限使用 ALTER SYSTEM SAVEPOINT 命令授权保存点流程的执行。
SCENARIO ADMIN
该权限授权所有计算场景相关的活动,包括新建。
SERVICE ADMIN
该权限授权 ALTER SYSTEM [START|CANCEL|RECONFIGURE] 命令,用于管理数据库中的系统服务。
SESSION ADMIN
该权限授权会话相关的 ALTER SYSTEM 命令 ,停止或重新连接用户会话或者修改会话参数。
STRUCTUREDPRIVILEGE ADMIN
该权限授权结构化权限的创建、重新激活和删除。
TRACE ADMIN
该权限授权数据库追踪文件的操作 ALTER SYSTEM [CLEAR|REMOVE] TRACES 命令。
USER ADMIN
该权限授权使用 CREATE USER, ALTER USER, and DROP 命令创建和修改用户。
VERSION ADMIN
该权限授权多版本并发控制(MVCC) ALTER SYSTEM RECLAIM VERSION SPACE command 命令。
<identifier>.<identifier>
SAP HANA 数据库组件可以创建自己需要的权限。这些权限使用组件名作为系统权限的第一标识符,使用组件-权限-名字作为第二标识符。目前元库使用该特点。有关名为 REPO.<identifier>的权限,请参阅元库手册。
<schema_privilege> ::=CREATE ANY| DEBUG| DELETE| DROP| EXECUTE| INDEX| INSERT| SELECT| TRIGGER| UPDATE
数据集合权限用于集合和存储在该集合中对象的访问和修改。集合权限的定义如下:
CREATE ANY
该权限允许用户在数据库中创建各种对象,尤其是表、视图、序列、同义词、 SQL 脚本、或者存储过程。
DELETE, DROP, EXECUTE, INDEX, INSERT, SELECT, UPDATE
指定的权限被授予每个目前和以后存储在集合中的每个对象。有关权限详细说明,请参阅下面的描述对象权限的部分,请检查以下权限适用于哪些类型的对象。
<object_privilege> ::=ALL PRIVILEGES| ALTER| DEBUG| DELETE| DROP| EXECUTE| INDEX| INSERT| SELECT| TRIGGER| UPDATE| <identifier>.<identifier>
对象权限用于限制用户访问和修改数据库对象,例如表、 视图、序列或者存储过程以及诸如此类。并不是所有的这些权限适用于所有类型的数据库对象。
对于对象类型允许的权限,见下表。
对象权限的定义如下:
ALL PRIVILEGES
该权限为所有 DDL(数据定义语言)和 DML(数据操纵语言)权限的组合。该权限一方面是授予人目前有的和允许进一步授予的权限,另一方面,特定对象上可以被授予的权限。该组合为给定的授予人和对象进行动态评估。 ALL PRIVILEGES 适用于表或试图。
ALTER
该 DDL 权限授权对象的 ALTER 命令。
DEBUG
该 DML 权限授权 存储过程或者计算视图的调试功能。
DELETE
该 DML 权限授权对象的 DELETE 和 TRUNCATE 命令。
DROP
该 DDL 权限授权对象的 DROP 命令。
EXECUTE
该 DML 权限授权 SQL Script 函数或者使用 CALLS 或 CALL 命令的存储过程。
INDEX
该 DDL 权限授权对象索引的创建、修改或者删除。
INSERT
该 DML 权限授权对象的 INSERT 命令。 INSERT 连同 UPDATE 权限一起允许使用对该对象的 REPLACE
和 UPSERT 命令。
SELECT
该 DML 权限授予对象的 SELECT 命令或者序列的使用。
TRIGGER
该 DDL 权限授权指定表或者指定集合中表的 CREATE TRIGGER / DROP TRIGGER 命令。
UPDATE
该 DML 权限授权对象的 UPDATE 命令 INSERT 连同 UPDATE 权限一起允许使用对该对象的 REPLACE
和 UPSERT 命令。
<identifier>.<identifier>
SAP HANA 数据库组件可以创建自己需要的权限。这些权限使用组件名作为系统权限的第一标识符,使用组件-权限-名字作为第二标识符。目前元库使用该特点。有关名为 REPO.<identifier>的权限,请参阅元库手册。
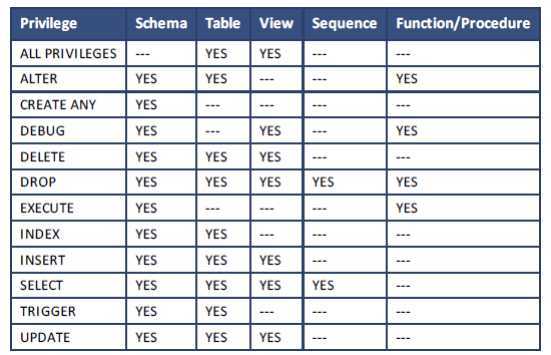
对视图的 DELETE, INSERT and UPDATE 操作只适用于可更新的视图,表示这些视图遵守这样的一些限制:不包含联接、 UNION,没有聚合以及进一步的一些限制。
DEBUG 只对计算视图适用,而非其他类型的视图。
这些限制适用于同义词,以及同义词代表的对象也适用。
<object_name> ::=<table_name>| <view_name>| <sequence_name>| <procedure_name>| <synonym_name>
对象权限用于限制用户访问和修改数据库对象,例如表、 视图、序列、存储过程和同义词。
<grantee> :: =<user_name>| <role_name>
grantee 可以是一个用户或者角色。在权限或角色授予角色的情况下,角色授予的所有用户,将有指定的权限或角色。
角色是权限的一个命名集合,可以授予一个用户或角色。
如果你想允许多个数据库用户执行相同的操作,你可以创建一个角色,授予该角色所需的权限,并将角色授予不同的数据库用户。
当授予角色给角色时,将建立一颗角色树。当将一个角色(R)授予另一个角色或者用户(G) , G 将拥有所有直接授予 R 的权限和角色。
描述:
GRANT 用于授予权限和结构化权限给用户和角色,也用于授予权限给用户和其他角色。
指定的用户、角色、对象和结构化权限必须在使用 GRANT 命令前已经存在。
只有拥有权限并且允许进一步授予权限的用户才能授予权限。每个拥有 ROLE ADMIN 权限的用户允许授予角色给其他角色和用户。
用户不能授予自己权限。
SYSTEM 用户有至少一个系统权限和 PUBLIC 角色。所有其他用户也有 PUBLIC 角色。这些权限和角色不能自己撤销。
虽然 SYSTEM 用户拥有许多权限,该用户不能选择或者修改其他用户的表,如果他没有显式地授权可以这样做。
SYSTEM 用户有在自己默认集合中创建对象的权限,名字和用户本身一样。
对于由用户创建的表,他们拥有所有权限并且可以将权限授予给用户和角色。
对依赖于例如基于表的视图的其他对象,可能发生的是用户如果没有底层对象的权限则在依赖对象也没有权限。或者可能发生的是用户有权限,但是不允许进一步授权。该用户将不能授予这些权限。
WITH ADMIN OPTION 和 WITH GRANT OPTION 指定了已分配的权限可以被特定的用户进一步分配,或者被拥有指定角色的用户分配。
使用 GRANT STRUCTURED PRIVILEGE <structured_privilege_name>,一个之前定义过的分析权限(基于通用结构化权限)被分配给用户或角色。该分析权限用于限制只读访问分析视图、属性视图和计算视图特定的数据,通过过滤属性值。
系统和监控视图:
USERS: 显示所有用户、用户的创建者、创建时间和当前状态的信息。
ROLES:显示所有角色、它们的创建者和创建时间。
GRANTED_ROLES:显示每个用户或角色被授予的角色。
GRANTED_PRIVILEGES:显示每个用户或角色被授予的权限。
例子:
假设已经创建了拥有创建集合、角色和用户权限的用户,他新建了数据集合:
CREATESCHEMA myschema;
另外,他还在该集合中新建了一张名为 work_done 的表。
CREATETABLE myschema.work_done (t TIMESTAMP, userNVARCHAR (256), work_done VARCHAR (256);
他创建了一个新的用户 named worker,在可能使用给定的密码和名为role_for_work_on_my_schema 的角色连接数据库
CREATEUSER worker PASSWORD His_Password_1;
CREATE ROLE role_for_work_on_my_schema;
他将其集合下所有对象的 SELECT 权限授予 role_for_work_on_my_schema 角色:
GRANTSELECTONSCHEMA myschema TO role_for_work_on_my_schema;
另外,用户将表 work_done to 的 INSERT 权限授予 role_for_work_on_my_schema 角色:
GRANTINSERTON myschema.work_done TO role_for_work_on_my_schema;
接着,他将角色授予新的用户:
GRANT role_for_work_on_my_schema TO worker WITHGRANTOPTION;
另外, worker 用户被直接授予表删除权限。该权限的选项允许进一步授予此权限。
GRANTDELETEON myschema.work_done TO worker;
现在,用户将创建任何类型对象的权限授予 worker 用户:
GRANTCREATEANYONSCHEMA myschema TO worker;
结果, worker 用户拥有集合 myschema 下所有表和视图的 SELECT 权限,表 myschema.work_done的 INSERT 和 DELETE 权限,以及在集合 myschema 下创建对象的权限。另外,该用户允许授予表myschema.work_done 的 DELETE 权限给其他用户和角色。
第二个例子中,用户有相应的权限,包括允许进一步授予权限、将系统权限 INIFILE ADMIN 和TRACE ADMIN 授予已有的用户 worker。他允许 worker 进一步授予这些权限。
GRANT INIFILE ADMIN, TRACE ADMIN TO worker WITH ADMIN OPTION;
语法:
REVOKE <system_privilege>,... FROM <grantee>|| REVOKE <schema_privilege>,... ON SCHEMA <schema_name> FROM <grantee>| REVOKE <object_privilege>,... ON <object_name> FROM <grantee>| REVOKE <role_name>,... FROM <grantee>| REVOKE STRUCTURED PRIVILEGE <privilege_name> FROM <grantee>
语法元素:
有关语法元素的定义,参见 GRANT。
描述:
REVOKE 语句撤销指定的角色或者结构化权限或者从指定用户或角色的指定对象中撤销权限。
只有拥有授权的用户可以撤销该权限。这对于有 ROLE ADMIN 的用户和角色的撤销也一样。
SYSTEM 用户有至少一个系统权限和 PUBLIC 角色。所有其他用户也有 PUBLIC 角色。这些权限和角色不能自己撤销。
如果用户也被授予一个角色,就不可能撤销属于该角色的一些权限。这种情况下,必须撤销所有角色,并且需要用户已授予给他的权限。
如果一个角色授予用户或角色,在角色删除时将被撤销。撤销角色可能会导致一些视图无法访问或者存储过程再也不工作,如果一个视图或存储过程依赖于该角色中的任意权限,会发生这种情况。
撤销已用 WITH GRANT OPTION 或 WITH ADMIN OPTION 授权的权限将导致不仅从指定的用户中撤销,也将从所有该用户直接或间接授权给用户和角色的权限中撤销。
由于权限可以用个不同的用户授给用户或角色,用户撤销该权限并一定意味着,该用户将失去这权限。有关语法元素的详请,请参见 GRANT。
系统和监控视图:
USERS: 显示所有用户、用户的创建者、创建时间和当前状态的信息。
ROLES:显示所有角色、它们的创建者和创建时间。
GRANTED_ROLES:显示每个用户或角色被授予的角色。
GRANTED_PRIVILEGES:显示每个用户或角色被授予的权限。
例子:
假设用户已经执行如下语句:
CREATEUSER worker PASSWORD His_Password_1;
CREATE ROLE role_for_work_on_my_schema;
CREATETABLE myschema.work_done (t TIMESTAMP, userNVARCHAR (256), work_done VARCHAR (256);
GRANTSELECTONSCHEMA myschema TO role_for_work_on_my_schema;
GRANTINSERTON myschema.work_done TO role_for_work_on_my_schema;
GRANT role_for_work_on_my_schema TO worker;
GRANT TRACE ADMIN TO worker WITH ADMIN OPTION;
GRANTDELETEON myschema.work_done TO worker WITHGRANTOPTION;
已授权的用户允许撤销这些权限。他从角色中撤销权限,因此,暗示着从所有已授予角色的用户撤销权限。另外, worker 用户将不再有 TRACE ADMIN 权限。撤销权限将导致撤回操作发生至worker 用户授予该权限的所有用户。
REVOKESELECTONSCHEMA myschema FROM role_for_work_on_my_schema;
REVOKE TRACE ADMIN FROM worker;
语法:
EXPORT <object_name_list> AS <export_format> INTO <path> [WITH <export_option_list>]
语法元素:
WITH <export_option_list>:
可以使用 WITH 子句传入 EXPORT 选项。
<object_name_list> ::= <OBJECT_NAME>,... | ALL
<export_import_format> ::= BINARY | CSV
<path> ::= ‘FULL_PATH‘
<export_option_list> ::= <export_option> | <export_option_list> <export_option>
<export_option> ::=REPLACE |CATALOG ONLY |NO DEPENDENCIES |SCRAMBLE [BY <password>] |THREADS <number_of_threads>
描述:
EXPORT 命令以指定的格式 BINARY 或者 CSV,导出表、视图、列视图、同义词、序列或者存储过程。临时表的数据和"no logging"表不能使用 EXPORT 导出表。
OBJECT_NAME
将导出对象的 SQL 名。欲导出所有集合下的所有对象,你要使用 ALL 关键字。如果你想导出指定集合下的对象,你应该使用集合名和星号,如"SYSTEM"."*"。
BINARY
表数据将以内部 BINARY 格式导出。使用这种方式导出数据比以 CSV 格式快几个数量级。只有列式表可以以二进制格式导出。行式表总是以 CSV 格式导出,即使指定了 BINARY 格式。
CSV
表数据将以 CSV 格式导出。导出的数据可以导入至其他数据库中。另外,导出的数据顺序可能被打乱。列式和行式表都可以以 CSV 格式导出。
FULL_PATH
将导出的服务器路径。
注意:当使用分布式系统, FULL_PATH 必须指向一个共享磁盘。由于安全性原因,路径可能不包含符号链接,也可能不指向数据库实例的文件夹内,除了‘backup‘ 和 ‘work‘子文件夹。有效路径(假设数据库实例位于/usr/sap/HDB/HDB00)的例子:
‘/tmp‘<br>
‘/usr/sap/HDB/HDB00/backup‘<br>
‘/usr/sap/HDB/HDB00/work‘<br>
REPLACE
使用 REPLACE 选项,之前导出的数据将被删除,而保存最新导出的数据。如果未指定 REPLACE 选项,如果在指定目录下存在先前导出的数据,将抛出错误。
CATALOG ONLY
使用 CATALOG ONLY 选项,只导出数据库目录,不含有数据。
NO DEPENDENCIES
使用 NO DEPENDENCIES 选项,将不导出已导出对象的相关对象。
SCRAMBLE
以 CSV 格式导出时,使用 SCRAMBLE [BY ‘<password>‘],可以扰乱敏感的客户数据。当未指定额外的数据库,将使用默认的扰乱密码。只能扰乱字符串数据。导入数据时,扰乱数据将以乱序方式导入,使最终用户无法读取数据,并且不可能回复原状。
THREADS
表示用于并行导出的线程数。
使用的线程数
给定 THREADS 数目指定并行导出的对象数,默认为 1。增加数字可能减少导出时间,但也会影响系统性能。
应当考虑如下:
? 对于单个表, THREADS 没有效果。
? 对于视图或者存储过程,应使用2 个或更多的线程(最多取决于对象数)。
? 对于整个集合,考虑使用多余10 个线程(最多取决于系统内核数)。
? 对于整个 BW / ERP 系统( ALL 关键字)的上千张表,数量大的线程是合理的(最多 256)。
系统和监控视图:
你可以使用系统视图 M_EXPORT_BINARY_STATUS 监控导出的进度。
你可以在如下语句中,使用会话 ID 从相应的视图中终止导出会话。
ALTERSYSTEM CANCEL [WORKIN] SESSION ‘sessionId‘
导出的详细结果存储在本地会话临时表#EXPORT_RESULT。
例子:
EXPORT"SCHEMA"."*"AS CSV INTO‘/tmp‘WITHREPLACE SCRAMBLE THREADS 10
语法:
IMPORT <object_name_list> [AS <import_format>] FROM <path> [WITH <import_option_list>]
语法元素:
WITH <import_option_list>:可以使用 WITH 子句传入 IMPORT 选项。
<object_name_list> ::= <object_name>,... | ALL
<import_format> ::= BINARY | CSV
<path> ::= ‘FULL_PATH‘
<import_option_list> ::= <import_option> | <import_option_list> <import_option>
<import_option> ::=REPLACE |CATALOG ONLY |NO DEPENDENCIES |THREADS <number_of_threads>
描述:
IMPORT 命令导入表、视图、列视图、同义词、序列或者存储过程。临时表的数据和"no logging"表不能使用 IMPORT 导入。
OBJECT_NAME
将导入对象的 SQL 名。欲导入路径中的所有对象,你要使用 ALL 关键字。如果你想将对象导入至指定集合下,你应该使用集合名和星号,如"SYSTEM"."*"。
BINARY | CSV
导入过程可能忽略格式的定义,因为在导入过程中,将自动检测格式。将以导出的同样格式导入。
FULL_PATH
从该服务器路径导入。
注意:当使用分布式系统, FULL_PATH 必须指向一个共享磁盘。如果未指定 REPLACE 选项,在指定目录下存在相同名字的表,将抛出错误。
CATALOG ONLY
使用 CATALOG ONLY 选项,只导入数据库目录,不含有数据。
NO DEPENDENCIES
使用 NO DEPENDENCIES 选项,将不导入已导入对象的相关对象。
THREADS
表示用于并行导入的线程数。
使用的线程数
给定 THREADS 数目指定并行导入的对象数,默认为 1。增加数字可能减少导入时间,但也会影响系统性能。
应当考虑如下:
? 对于单个表, THREADS 没有效果。
? 对于视图或者存储过程,应使用2 个或更多的线程(最多取决于对象数)。
? 对于整个集合,考虑使用多余10 个线程(最多取决于系统内核数)。
? 对于整个 BW / ERP 系统( ALL 关键字)的上千张表,数量大的线程是合理的(最多 256)。
系统和监控视图:
你可以使用系统视图 M_IMPORT_BINARY_STATUS 监控导入的进度。
你可以在如下语句中,使用会话 ID 从相应的视图中终止导入会话。
ALTER SYSTEM CANCEL [WORK IN] SESSION ‘sessionId‘
导入的详细结果存储在本地会话临时表#IMPORT_RESULT。
语法:
IMPORT FROM [<file_type>] <file_path> [INTO <table_name>] [WITH <import_from_option_list>]
语法元素:
WITH <import_from_option_list>:
可以使用 WITH 子句传入 IMPORT FROM 选项。
<file_path> ::= ‘<character>...‘
<table_name> ::= [<schema_name>.]<identifier>
<import_from_option_list> ::= <import_from_option> | <import_from_option_list> <import_from_option>
<import_from_option> :: =THREADS <number_of_threads>
|BATCH <number_of_records_of_each_commit> |TABLE LOCK |NO TYPE CHECK |SKIP
FIRST <number_of_rows_to_skip>
ROW |COLUMN LIST IN FIRST ROW |COLUMN LIST ( <column_name_list> )
|RECORD DELIMITED BY ‘<string_for_record_delimiter>‘ |FIELD DELIMITED BY
‘<string_for_field_delimiter>‘ |OPTIONALLY ENCLOSED BY
‘<character_for_optional_enclosure>‘ |DATE FORMAT
‘<string_for_date_format>‘ |TIME FORMAT ‘<string_for_time_format>‘
|TIMESTAMP FORMAT ‘<string_for_timestamp_format>‘ |
描述:
IMPORT FROM 语句将外部 csv 文件的数据导入至一个已有的表中。
THREADS:表示可以用于并行导出的线程数。默认值为 1,最大值为 256。
BATCH:表示每个提交中可以插入的记录数。
THREADS 和 BATCH 可以通过启用并行加载和一次提交多条记录,实现加载的高性能。一般而言,对于列式表, 10 个并行加载线程以及 10000 条记录的提交频率是比较好的设置。
TABLE LOCK:锁住表为了更快的导入数据至列式表。如果指定了 NO TYPE CHECK,记录将在插入时,不检查每个字段的类型。
SKIP FIRST <int> ROW:跳过插入前 n 条记录。
COLUMN LIST IN FIRST ROW:表示在 CSV 文件中第一行的列。
COLUMN LIST ( <column_name_list> ):表示将要插入的字段列表。
RECORD DELIMITED BY ‘<string>‘:表示 CSV 文件中的记录分隔符。
FIELD DELIMITED BY ‘<string>‘:表示 CSV 文件中的字段分隔符。
OPTIONALLY ENCLOSED BY ‘<character>‘:表示字段数据的可选关闭符。
DATE FORMAT ‘<string>‘:表示字符的日期格式。如果 CSV 文件有日期类型,将为日期类型字段使用指定的格式。
TIME FORMAT ‘<string>‘:表示字符的时间格式。如果 CSV 文件有时间类型,将为时间类型字段使用指定的格式。
TIMESTAMP FORMAT ‘<string>‘:表示字符的时间戳格式。如果 CSV 文件有时间戳类型,将为日期类型字段使用指定的格式。
例子:
IMPORTFROM CSV FILE ‘/data/data.csv‘INTO"MYSCHEMA"."MYTABLE"WITH RECORD DELIMITED BY‘\n‘ FIELD DELIMITED BY‘,‘
原文:http://www.cnblogs.com/jiangzhengjun/p/5040526.html