Hadoop思想之源:Google
面对的数据和计算难题
——大量的网页怎么存储
——搜索算法
带给我们的关键技术和思想
——GFS
——Map-Reduce
——Bigtable
Hadoop创始人介绍:
Hadoop作者Doug cutting,就职Yahoo期间开发了Hadoop项目,目前在CLoudera公司从事架构工作。他不但是Hadoop项目的发起人,还是Lucene、Nutch项目的发起人。

Hadoop简介:
——名字来源于Hadoop之父Doug Cutting儿子的玩具大象。
2003-2004年,Google公开了部分GFS和Mapreduce思想的细节,以此为基础Doug Cutting等人用了2年业余时间实现了DFS和Mapreduce机制,一个微缩版:Nutch。
Hadoop于2005年秋天作为Lucene的子项目Nutch的一部分正式引入Apache基金会。2006年3月份,Map-Reduce和Nutch Distributed File System(NDFS)分别被纳入成为Hadoop的项目中。
——分布式存储系统HDFS(Hadoop Distributed File System)
——分布式计算框架Map-Reduce
HDFS优点:
- 高容错性:
- 高可靠性
- 高扩展性
- 高效性:
- 适合批处理:
- 适合大数据处理:
- 可构建在廉价机器上:
HDFS缺点:
- 不适合低延迟数据访问:
- 不适合小文件存取:
- 不支持并发写入、文件随机修改:
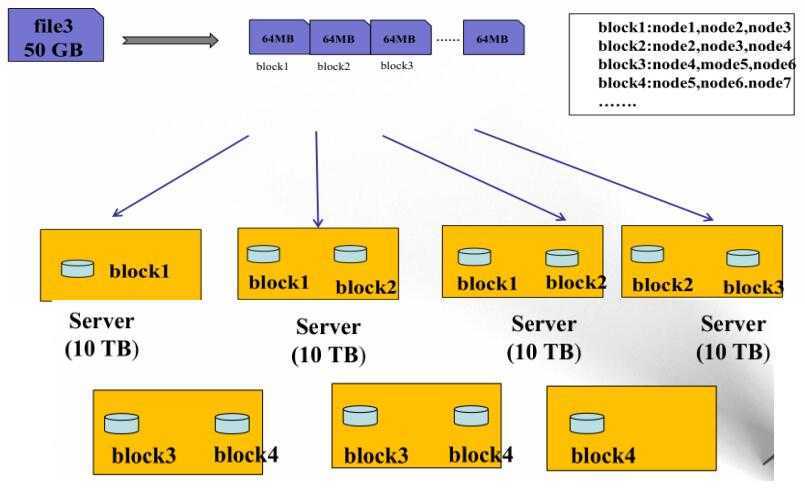
HDFS数据存储元(block)
- 文件被切分成固定大小的数据块
- 一个文件存储方式
- Block大小和副本数通过Clien端上传文件时设置,文件上传成功后副本数可以变更,Block Size不可变更
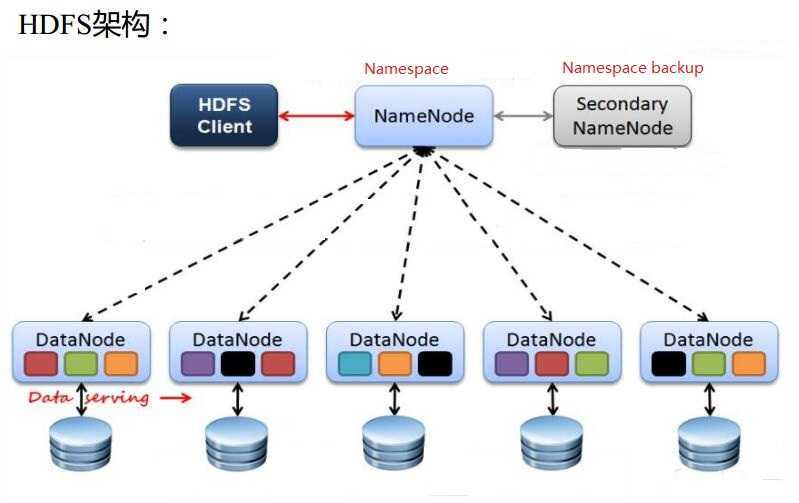
HDFS设计思想:
NameNode(NN):
- NameNode主要功能:接受客户端的读写服务
- NameNode保存metadata信息,包括:
- NameNode的metadata信息在启动后会加载到内存:
SecondaryNameNode(SNN):
- 它不是NameNode的备份(但可以做备份),它的主要工作是帮助NameNode合并edits log,减少NameNode启动时间
- SecondaryNameNode执行合并时机:
DataNode(DN):
- 存储数据(block)
- 启动DataNode线程的时候会向NameNode汇报block信息(block位置信息),保存到NameNode的metadata(fsimage文件)中
- 通过向NameNode发送心跳保持与其联系(3秒一次),如果NameNode10分钟没有收到DataNode的心跳,则认为其已经lost,并copy其上的block到其他DataNode,以保证每个文件的每个Block至少保存有3个副本
原文:http://www.cnblogs.com/zhoujingyu/p/5040957.html