本文旨在以一个有代表性的文字分页的取样规则和过滤规则为蓝本,通过简单的变通和改动,解决一般性文字分页的采集问题
一、范例部分
范例分页区域代码:
范例分页区域代码: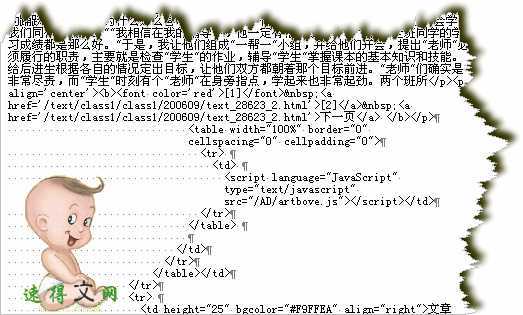
范例分页区域取样代码:
分页区域取样(匹配):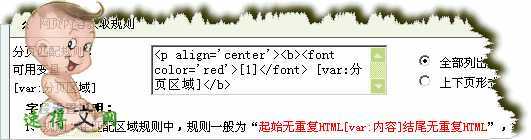
范例分页内容过滤规则:
分页内容过滤规则: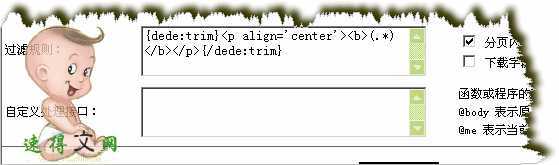
范例采集内容预览:
范例采集内容预览:
范例全代码(说明:此代码为在原基础上进行更改后的代码,原代码版本不同,直接导入后无效,因此在dede论坛中有许多朋友说过‘直接导入人家的代码都不能用‘,确实如此):
输出结果:http://wen.soudata.net/html/guizeceshi/caijibiji/20070327/2044_2.html
与原文比较下吧:http://www.xiaocao.com/text/class1/class1/200609/text_28623.html
这是全部的代码,可导入试下:复制代码 代码如下:
{!-- 节点基本信息 --}
{dede:item name=‘论坛范例_工作总结_成功(改)‘
imgurl=‘/upimg‘ imgdir=‘../upimg‘ language=‘gb2312‘ typeid=‘1‘ macthtype=‘string‘}
{/dede:item}
{!-- 采集列表获取规则 --}
{dede:list source=‘var‘ sourcetype=‘archives‘
varstart=‘‘ varend=‘‘}
{dede:url value=‘http://www.xiaocao.com/text/class1/class1/200609/text_28623.html‘}{/dede:url}
{dede:need}{/dede:need}
{dede:cannot}{/dede:cannot}
{dede:linkarea}[var:区域]{/dede:linkarea}
{/dede:list}
{!-- 网页内容获取规则 --}
{dede:art}
{dede:sppage sptype=‘full‘}<p align=‘center‘><b><font color=‘red‘>[1]</font>[var:分页区域]</b>{/dede:sppage}
{dede:note field=‘dede_archives.title‘ value=‘[var:内容]‘ comment=‘文章标题‘
isunit=‘‘ isdown=‘‘}
{dede:match}<title>[var:内容]</title>{/dede:match}
{dede:function}{/dede:function}
{/dede:note}
{dede:note field=‘dede_archives.sortrank‘ value=‘[var:内容]‘ comment=‘排序级别‘
isunit=‘‘ isdown=‘‘}
{dede:match}{/dede:match}
{dede:function}@me = time();{/dede:function}
{/dede:note}
{dede:note field=‘dede_archives.writer‘ value=‘[var:内容]‘ comment=‘文章作者‘
isunit=‘‘ isdown=‘‘}
{dede:match}{/dede:match}
{dede:function}{/dede:function}
{/dede:note}
{dede:note field=‘dede_archives.litpic‘ value=‘[var:内容]‘ comment=‘缩略图‘
isunit=‘‘ isdown=‘‘}
{dede:match}{/dede:match}
{dede:function}@me = @litpic;{/dede:function}
{/dede:note}
{dede:note field=‘dede_archives.pubdate‘ value=‘[var:内容]‘ comment=‘发布时间‘
isunit=‘‘ isdown=‘‘}
{dede:match}{/dede:match}
{dede:function}if(@me!="") @me = GetMkTime(@me);
else @me = time();{/dede:function}
{/dede:note}
{dede:note field=‘dede_archives.senddate‘ value=‘[var:内容]‘ comment=‘录入时间‘
isunit=‘‘ isdown=‘‘}
{dede:match}{/dede:match}
{dede:function}@me = time();{/dede:function}
{/dede:note}
{dede:note field=‘dede_addonarticle.body‘ value=‘[var:内容]‘ comment=‘文章内容‘
isunit=‘1‘ isdown=‘‘}
{dede:match}<script language="JavaScript" type="text/javascript" src="/AD/artcontent.js"></script>[var:内容]<table width="100%" border="0" cellspacing="0" cellpadding="0">
{/dede:match}
{dede:trim}<p align=‘center‘><b>(.*)</b></p>{/dede:trim}
{dede:function}{/dede:function}
{/dede:note}
{dede:note field=‘dede_archives.source‘ value=‘[var:内容]‘ comment=‘文章来源‘
isunit=‘‘ isdown=‘‘}
{dede:match}{/dede:match}
{dede:function}{/dede:function}
{/dede:note}
{/dede:art}
原文:http://www.jb51.net/article/9138.htm