前提,安装了jdk1.7,scala,hadoop单节点
步骤:
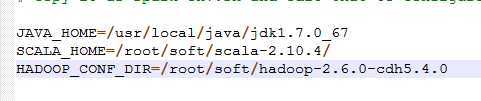
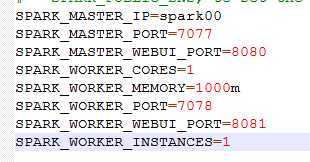
spark-env.sh
加入:
HADOOP_CONF_DIR=/root/------ 表示使用hdfs上的资源,如果需要使用本地资源,请把这一句注销
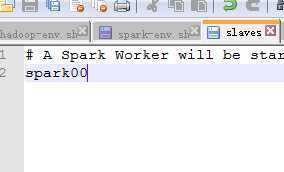
2,slaves
3,spark-defalts.conf
-----------------------------------------------------------------------------------------------------------------
启动:
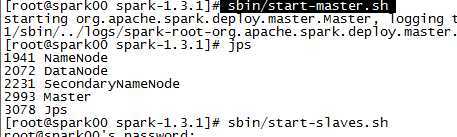
cd /root/soft/spark-1.3.1
sbin/start-master.sh 启动master
sbin/start-slaves.sh 启动worker
安装部署spark standalone 模式集群
原文:http://www.cnblogs.com/xiaoxiao5ya/p/b35e6798b7d9d202d1f7128d324ecf4c.html