一、作用域
对于变量的作用域,执行声明并在内存中存在,该变量就可以在下面的代码中使用。
if 1==1:
name = ‘lenliu‘
print name
下面的结论对吗?(对)
外层变量,可以被内层变量使用
内层变量,无法被外层变量使用
二、三元运算
result = 值1 if 条件 else 值2
result = ‘lenliu‘ if 1 == 1 else ‘amy‘
print result
如果条件为真:result = 值1
如果条件为假:result = 值2
三、进制
对于Python,一切事物都是对象,对象基于类创建
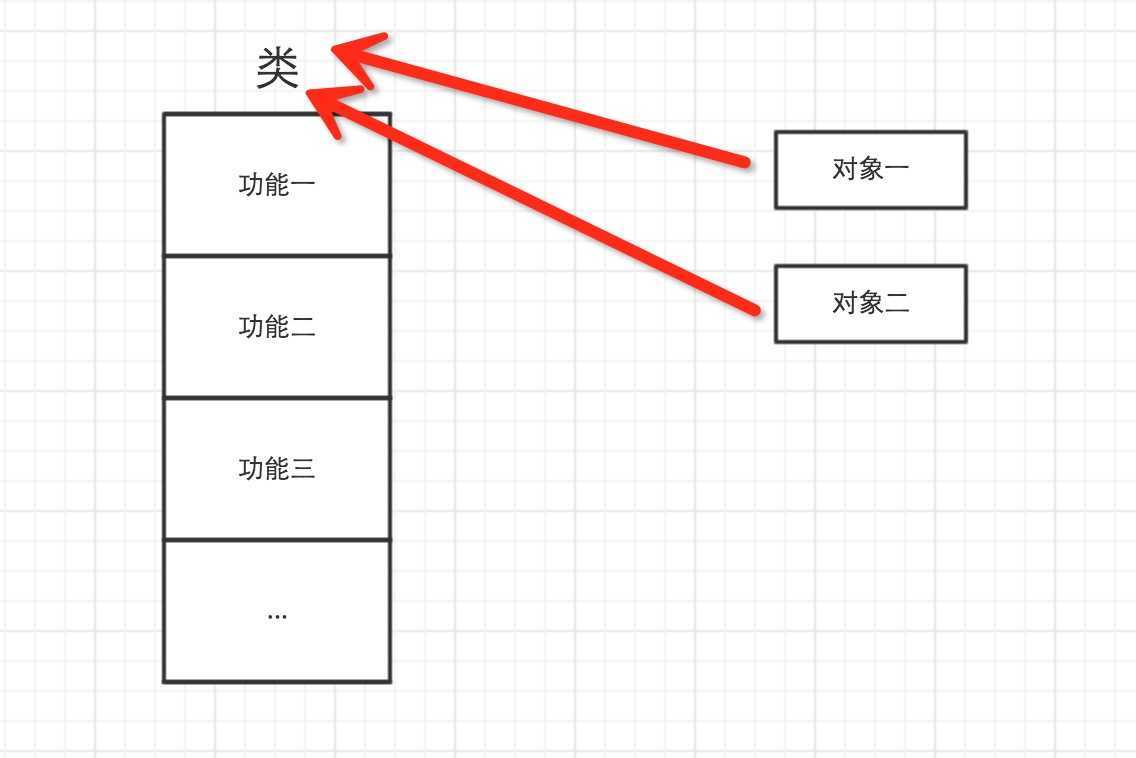
所以,以下这些值都是对象: "lenliu"、38、[ ‘上海‘, ‘深圳‘],并且是根据不同的类生成的对象。

四、数字类型
1、整数:int()
如: 18、73、84
2、长整型:long()
可能如:2147483649、9223372036854775807
3、浮点型:float()
如:3.1415926、2.88
4、字符串:str()
如:lenliu、‘amy‘
五、列表:list()
如:[11,22,33]、[lenliu, ‘amy‘]
每个元组都具备如下功能:
>>> help(list)
>>>dir(list)
[‘__add__‘, ‘__class__‘, ‘__contains__‘, ‘__delattr__‘, ‘__delitem__‘, ‘__delslice__‘, ‘__doc__‘, ‘__eq__‘, ‘__format__‘, ‘__ge__‘, ‘__getattribute__‘, ‘__getitem__‘, ‘__getslice__‘, ‘__gt__‘, ‘__hash__‘, ‘__iadd__‘, ‘__imul__‘, ‘__init__‘, ‘__iter__‘, ‘__le__‘, ‘__len__‘, ‘__lt__‘, ‘__mul__‘, ‘__ne__‘, ‘__new__‘, ‘__reduce__‘, ‘__reduce_ex__‘, ‘__repr__‘, ‘__reversed__‘, ‘__rmul__‘, ‘__setattr__‘, ‘__setitem__‘, ‘__setslice__‘, ‘__sizeof__‘, ‘__str__‘, ‘__subclasshook__‘, ‘append‘, ‘count‘, ‘extend‘, ‘index‘, ‘insert‘, ‘pop‘, ‘remove‘, ‘reverse‘, ‘sort‘]






![]() 删除整个列表的数据 list1.sort(reverse=False) 从小大到排序
删除整个列表的数据 list1.sort(reverse=False) 从小大到排序

![]()
六、元组:tuple (只能读取,不能被修改)
如:(11,22,33)、(‘wupeiqi‘, ‘alex‘)
每个元组都具备如下功能:
>>>help(tuple)
>>>dir(tuple)
[‘__add__‘, ‘__class__‘, ‘__contains__‘, ‘__delattr__‘, ‘__doc__‘, ‘__eq__‘, ‘__format__‘, ‘__ge__‘, ‘__getattribute__‘, ‘__getitem__‘, ‘__getnewargs__‘, ‘__getslice__‘, ‘__gt__‘, ‘__hash__‘, ‘__init__‘, ‘__iter__‘, ‘__le__‘, ‘__len__‘, ‘__lt__‘, ‘__mul__‘, ‘__ne__‘, ‘__new__‘, ‘__reduce__‘, ‘__reduce_ex__‘, ‘__repr__‘, ‘__rmul__‘, ‘__setattr__‘, ‘__sizeof__‘, ‘__str__‘, ‘__subclasshook__‘, ‘count‘, ‘index‘]



把元组拆成两部分,能后加入元素,逗号很关键 ( 删除元组 :del temp1 )

七、字典 (字典由索引key和它对应的值value组成)
如:{‘name‘: ‘wupeiqi‘, ‘age‘: 18} 、{‘host‘: ‘2.2.2.2‘, ‘port‘: 80]}
ps:循环时,默认循环key
每个字典都具备如下功能:
>>>help(dict)
>>> dir(dict)
[‘__class__‘, ‘__cmp__‘, ‘__contains__‘, ‘__delattr__‘, ‘__delitem__‘, ‘__doc__‘, ‘__eq__‘, ‘__format__‘, ‘__ge__‘, ‘__getattribute__‘, ‘__getitem__‘, ‘__gt__‘, ‘__hash__‘, ‘__init__‘, ‘__iter__‘, ‘__le__‘, ‘__len__‘, ‘__lt__‘, ‘__ne__‘, ‘__new__‘, ‘__reduce__‘, ‘__reduce_ex__‘, ‘__repr__‘, ‘__setattr__‘, ‘__setitem__‘, ‘__sizeof__‘, ‘__str__‘, ‘__subclasshook__‘, ‘clear‘, ‘copy‘, ‘fromkeys‘, ‘get‘, ‘has_key‘, ‘items‘, ‘iteritems‘, ‘iterkeys‘, ‘itervalues‘, ‘keys‘, ‘pop‘, ‘popitem‘, ‘setdefault‘, ‘update‘, ‘values‘, ‘viewitems‘, ‘viewkeys‘, ‘viewvalues‘]


八、set集合
set是一个无序且不重复的元素集合
练习:寻找差异
# 数据库中原有
old_dict = {
"#1":{ ‘hostname‘:c1, ‘cpu_count‘: 2, ‘mem_capicity‘: 80 },
"#2":{ ‘hostname‘:c1, ‘cpu_count‘: 2, ‘mem_capicity‘: 80 }
"#3":{ ‘hostname‘:c1, ‘cpu_count‘: 2, ‘mem_capicity‘: 80 }
}
# cmdb 新汇报的数据
new_dict = {
"#1":{ ‘hostname‘:c1, ‘cpu_count‘: 2, ‘mem_capicity‘: 800 },
"#3":{ ‘hostname‘:c1, ‘cpu_count‘: 2, ‘mem_capicity‘: 80 }
"#4":{ ‘hostname‘:c2, ‘cpu_count‘: 2, ‘mem_capicity‘: 80 }
}
需要删除、需要新建、需要更新
注意:无需考虑内部元素是否改变,只要原来存在,新汇报也存在,就是需要更新
old_set = set(old_dict.keys())
update_list = list(old_set.intersection(new_dict.keys()))
new_list = []
del_list = []
for i in new_dict.keys():
if i not in update_list:
new_list.append(i)
for i in old_dict.keys():
if i not in update_list:
del_list.append(i)
print update_list,new_list,del_list
九、collection系列
1、计数器(counter)
Counter是对字典类型的补充,用于追踪值的出现次数。
ps:具备字典的所有功能 + 自己的功能
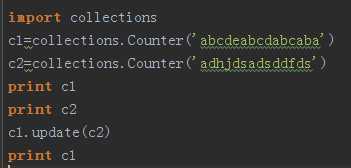
在上面的例子我们可以看出,Counter方法返回的是一个字典,它将字符串中出现的所有字符都进行了统计。
在这里再介绍一下update方法,这个update方法是将两次统计的结果相加,和字典的update略有不同。
2、有序字典(orderedDict )
orderdDict是对字典类型的补充,他记住了字典元素添加的顺序
3、默认字典(defaultdict)

需求:有如下值集合 [11,22,33,44,55,66,77,88,99,90...],将所有大于 66 的值保存至字典的第一个key中,将小于 66 的值保存至第二个key的值中。
即: {‘k1‘: 大于66 , ‘k2‘: 小于66}
# 字典解决方法
values = [11, 22, 33,44,55,66,77,88,99,90]
my_dict = {}
for value in values:
if value>66:
if my_dict.has_key(‘k1‘):
my_dict[‘k1‘].append(value)
else:
my_dict[‘k1‘] = [value]
else:
if my_dict.has_key(‘k2‘):
my_dict[‘k2‘].append(value)
else:
my_dict[‘k2‘] = [value]
#默认字典解决方法
from collections import defaultdict
values = [11, 22, 33,44,55,66,77,88,99,90]
my_dict = defaultdict(list)
for value in values:
if value>66:
my_dict[‘k1‘].append(value)
else:
my_dict[‘k2‘].append(value)
PS:defaultdict是对字典的类型的补充,他默认给字典的值设置了一个类型。
4、可命名元组(namedtuple)
根据nametuple可以创建一个包含tuple所有功能以及其他功能的类型。
import collections Mytuple = collections.namedtuple(‘Mytuple‘,[‘x‘, ‘y‘, ‘z‘])
>>> dir(Mytuple)
[‘__add__‘, ‘__class__‘, ‘__contains__‘, ‘__delattr__‘, ‘__doc__‘, ‘__eq__‘, ‘__format__‘, ‘__ge__‘, ‘__getattribute__‘, ‘__getitem__‘, ‘__getnewargs__‘, ‘__getslice__‘, ‘__gt__‘, ‘__hash__‘, ‘__init__‘, ‘__iter__‘, ‘__le__‘, ‘__len__‘, ‘__lt__‘, ‘__module__‘, ‘__mul__‘, ‘__ne__‘, ‘__new__‘, ‘__reduce__‘, ‘__reduce_ex__‘, ‘__repr__‘, ‘__rmul__‘, ‘__setattr__‘, ‘__sizeof__‘, ‘__slots__‘, ‘__str__‘, ‘__subclasshook__‘, ‘_asdict‘, ‘_fields‘, ‘_make‘, ‘_replace‘, ‘count‘, ‘index‘, ‘x‘, ‘y‘, ‘z‘]
5、双向队列(deque)
一个线程安全的双向队列
注:既然有双向队列,也有单项队列(先进先出 FIFO )
友情链接:http://www.cnblogs.com/wupeiqi/articles/4911365.html 武sir
原文:http://www.cnblogs.com/lenliu/p/5057147.html


