既然能把冒泡时间复杂度为O(n2),经测试1秒内只能排17000个数据。但现实的数据往往是十万级和百万级,怎么办,一个新的排序产生了,他就是快速排序。
快速排序算法如下:
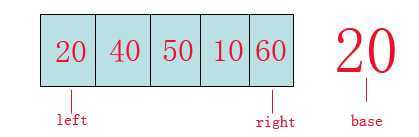
从图中我们可以看到:
left指针,right指针,base参照数。
其实思想是蛮简单的,就是通过第一遍的遍历(让left和right指针重合)来找到数组的切割点。
第一步:首先我们从数组的left位置取出该数(20)作为基准(base)参照物。
第二步:从数组的right位置向前找,一直找到比(base)小的数,
如果找到,将此数赋给left位置(也就是将10赋给20),
此时数组为:10,40,50,10,60,
left和right指针分别为前后的10。
第三步:从数组的left位置向后找,一直找到比(base)大的数,
如果找到,将此数赋给right的位置(也就是40赋给10),
此时数组为:10,40,50,40,60,
left和right指针分别为前后的40。
第四步:重复“第二,第三“步骤,直到left和right指针重合,
最后将(base)插入到40的位置,
此时数组值为: 10,20,50,40,60,至此完成一次排序。
第五步:此时20已经潜入到数组的内部,20的左侧一组数都比20小,20的右侧作为一组数都比20大,
以20为切入点对左右两边数按照"第一,第二,第三,第四"步骤进行,最终快排大功告成。
快排的时间复杂度为:
平均复杂度: N(logN)
最坏复杂度: 0(n^2)
C++源程序如下:
原文:http://www.cnblogs.com/jjzzx/p/5068050.html