为了保持生产环境中数据库的稳定性和性能,增强用户体验。同时也为了避免因数据库连接超时产生页面5xx的错误,有时候我们需要对数据库进行某些方面的优化。主要包括以下几个方面:
它们具体的优化效果及成本关系如下图所示:
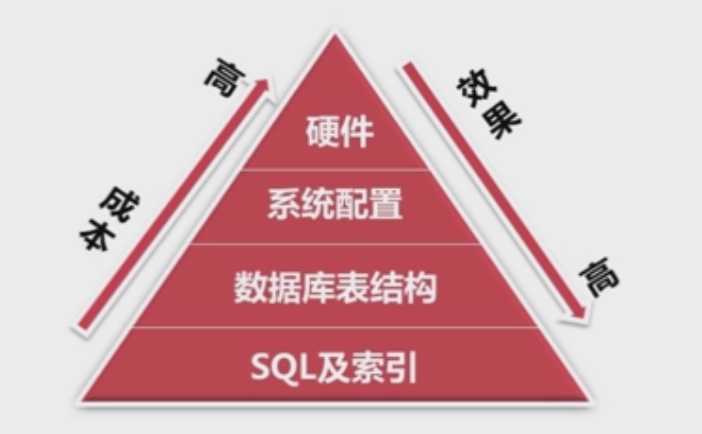
在生产环境下,SQL及索引优化占有比较大的比重,而且效果比较明显,根据左边的箭头,越往上优化的成本越高;效果却越来越不明显。
一、SQL及索引优化
1、如何发现有问题的SQL?
通过慢查询日志可以发现,在使用慢查询日志之前,需要设置以下变量参数:
(product)root@localhost [(none)]> show variables like ‘slow_query_log‘; #开启慢查询 +----------------+-------+ | Variable_name | Value | +----------------+-------+ | slow_query_log | ON | +----------------+-------+ 1 row in set (0.01 sec) (product)root@localhost [(none)]> show variables like ‘long_query_time‘; #记录超过多少秒的sql将记录到慢查询日志中。为0表示记录所有sql +-----------------+----------+ | Variable_name | Value | +-----------------+----------+ | long_query_time | 1.000000 | +-----------------+----------+ 1 row in set (0.00 sec) (product)root@localhost [(none)]> show variables like ‘log_queries_not_using_indexes‘; #记录没有使用索引的sql到日志中 +-------------------------------+-------+ | Variable_name | Value | +-------------------------------+-------+ | log_queries_not_using_indexes | ON | +-------------------------------+-------+ 1 row in set (0.00 sec)
1) 慢查询日志的存储格式?
### 开始时间
# Time: 151224 17:27:43
### 执行SQL的主机信息 # User@Host: root[root] @ localhost [] Id: 4
### SQL的执行信息 # Query_time: 0.125071 Lock_time: 0.122781 Rows_sent: 10 Rows_examined: 10 use sakila;
### 执行时间 SET timestamp=1450949263;
### SQL的内容 select * from actor limit 10;
2) 使用官方mysqldumpslow工具
[root@node1 ~]# mysqldumpslow -t 1 /data/mysql/mysql_3306/data/slow.log -a Reading mysql slow query log from /data/mysql/mysql_3306/data/slow.log Count: 1 Time=0.00s (0s) Lock=0.00s (0s) Rows=0.0 (0), 0users@0hosts # Time: 151224 17:27:43 # User@Host: root[root] @ localhost [] Id: 4 # Query_time: 0.125071 Lock_time: 0.122781 Rows_sent: 10 Rows_examined: 10 use sakila; SET timestamp=1450949263; select * from actor limit 10
官方提供的慢查询分析工具比较方便快捷,但是提供的分析数据比较有限,下面介绍一款更强大的工具
3) pt-query-digest工具
[root@node1 bin]# pt-query-digest /data/mysql/mysql_3306/data/slow.log #############################第一部分###################################### # 190ms user time, 490ms system time, 25.93M rss, 213.35M vsz # Current date: Mon Dec 28 15:00:03 2015 # Hostname: node1 # Files: /data/mysql/mysql_3306/data/slow.log # Overall: 1 total, 1 unique, 0 QPS, 0x concurrency ______________________ # Time range: all events occurred at 2015-12-24 17:27:43 # Attribute total min max avg 95% stddev median # ============ ======= ======= ======= ======= ======= ======= ======= # Exec time 125ms 125ms 125ms 125ms 125ms 0 125ms # Lock time 123ms 123ms 123ms 123ms 123ms 0 123ms # Rows sent 10 10 10 10 10 0 10 # Rows examine 10 10 10 10 10 0 10 # Query size 28 28 28 28 28 0 28
###############################第二部分#################################### # Profile # Rank Query ID Response time Calls R/Call V/M Item # ==== ================== ============= ===== ====== ===== ============ # 1 0x5665CD6BAE86EAEC 0.1251 100.0% 1 0.1251 0.00 SELECT actor
###############################第三部分#################################### # Query 1: 0 QPS, 0x concurrency, ID 0x5665CD6BAE86EAEC at byte 0 ________ # This item is included in the report because it matches --limit. # Scores: V/M = 0.00 # Time range: all events occurred at 2015-12-24 17:27:43 # Attribute pct total min max avg 95% stddev median # ============ === ======= ======= ======= ======= ======= ======= ======= # Count 100 1 # Exec time 100 125ms 125ms 125ms 125ms 125ms 0 125ms # Lock time 100 123ms 123ms 123ms 123ms 123ms 0 123ms # Rows sent 100 10 10 10 10 10 0 10 # Rows examine 100 10 10 10 10 10 0 10 # Query size 100 28 28 28 28 28 0 28 # String: # Databases sakila # Hosts localhost # Users root # Query_time distribution # 1us # 10us # 100us # 1ms # 10ms # 100ms ################################################################ # 1s # 10s+ # Tables # SHOW TABLE STATUS FROM `sakila` LIKE ‘actor‘\G # SHOW CREATE TABLE `sakila`.`actor`\G # EXPLAIN /*!50100 PARTITIONS*/ select * from actor limit 10\G
pt-query-digest输出内容大体分三部分,那么如何通过这个结果找到问题SQL?
4) explain工具
explain可以分析某个查询的执行计划,通过执行计划分析查询是否利用索引。具体的输出参数如下:
(product)root@localhost [sakila]> explain select * from actor order by last_update; +----+-------------+-------+------+---------------+------+---------+------+------+----------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+------+---------------+------+---------+------+------+----------------+ | 1 | SIMPLE | actor | ALL | NULL | NULL | NULL | NULL | 200 | Using filesort | +----+-------------+-------+------+---------------+------+---------+------+------+----------------+ 1 row in set (0.00 sec)
2、count()和max()的优化
---恢复内容结束---
原文:http://www.cnblogs.com/mysql-dba/p/5083484.html