Old: print "The answer is" , 2 *2 New: print( "The answer is" , 2 *2 )
print x, #在末尾加上‘ ,’
print(x,end = ‘‘ )
Old: 1 / 2 #结果为0 New: 1/2 #终于等于0.5
New: input() 等于 Old:raw_input
New:eval(input()) 等于 Old:input()
>>> lb=[1,2,3,‘a‘,‘b‘] >>> lb [1, 2, 3, ‘a‘, ‘b‘] >>> lb.sort() Traceback (most recent call last): File "<pyshell#2>", line 1, in <module> lb.sort() TypeError: unorderable types: str() < int() >>> lb.reverse() >>> lb [‘b‘, ‘a‘, 3, 2, 1]
>>> lb=[1,2,3,‘a‘,‘b‘] >>> lb.sort() >>> lb [1, 2, 3, ‘a‘, ‘b‘] >>> lb.reverse() >>> lb [‘b‘, ‘a‘, 3, 2, 1]
>>> data={‘haha‘:123,‘xixi‘:456}
>>> data.keys()
dict_keys([‘haha‘, ‘xixi‘])
>>> type(data.keys())
<class ‘dict_keys‘>
>>> data={‘haha‘:123,‘xixi‘:456}
>>> data.keys()
[‘xixi‘, ‘haha‘]
>>> type(data.keys())
<type ‘list‘>
#!/usr/bin/env python print("你好,世界")
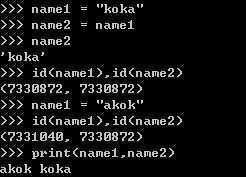
>>> name = "koka"
>>> print("hello %s" %name)
hello koka
>>> ‘%10f‘ % pi #字符宽度 10 ‘ 3.141593‘ >>> ‘%10.2f‘ % pi #字符宽度10,精度2 ‘ 3.14‘ >>> ‘%.2f‘ % pi #精度2 ‘3.14‘
>>> ‘%.*s‘ %(5,‘Guido van Rossum‘) ‘Guido‘
>>> ‘%010.2f‘ % pi ‘0000003.14‘ >>> ‘%-10.2f‘ % pi ‘3.14
>>> ‘With a moo-moo here‘.find(‘moo‘) 7
>>> seq = [1,2,3,4,5] >>> sep = ‘+‘ >>> sep.join(seq) Traceback (most recent call last): File "<pyshell#26>", line 1, in <module> sep.join(seq) TypeError: sequence item 0: expected str instance, int found >>> seq = [‘1‘,‘2‘,‘3‘] >>> sep = ‘+‘ >>> sep.join(seq) ‘1+2+3‘
>>> ‘1+2+3‘.split("+") [‘1‘, ‘2‘, ‘3‘]
>>> ‘ hahaha ‘.strip() ‘hahaha‘
>>> [0,1,2,3,4,5] [0, 1, 2, 3, 4, 5]
>>> [‘th‘] * 10 [‘th‘, ‘th‘, ‘th‘, ‘th‘, ‘th‘, ‘th‘, ‘th‘, ‘th‘, ‘th‘, ‘th‘] >>> 0 in [0,1,2,3,4,5] True >>> num = [0,1,2,3,4,5] >>> num[:] [0, 1, 2, 3, 4, 5] >>> num[0:3] [0, 1, 2]
>>> lst = [1,2,3] >>> lst.append(4) >>> lst [1, 2, 3, 4]
>>> a = [1,2,3] >>> b = [4,5,6] >>> a.extend(b) >>> a [1, 2, 3, 4, 5, 6]
>>> a.pop() 3
>>> [‘a‘,‘b‘,‘c‘,‘a‘].count(‘a‘) 2
>>> x = [1,3,5,2,6,8] >>> x.sort() >>> x [1, 2, 3, 5, 6, 8]
>>> x.reverse() >>> x [8, 6, 5, 3, 2, 1]
>>> y = sorted(x) >>> y [1, 2, 3, 5, 6, 8]
>>> (‘username‘,‘password‘) (‘username‘, ‘password‘) >>> tuple([‘a‘,‘b‘]) (‘a‘, ‘b‘)
{‘key‘:‘value‘}
{}.fromkeys([‘name‘,‘age‘])
{‘age‘:‘None‘,‘name‘:‘None‘}
dict.fromkeys([‘name‘,‘age‘])
{‘age‘:None,‘name‘:None}
d={} print d{[‘name‘]} error print d.get(‘name‘) None
>>> database={‘koka‘:‘123‘,‘wawa‘:‘456‘}
>>> for key,value in database.items():
print(key,value)
wawa 456
koka 123
>>> d = {} >>> d.setdefault(‘name‘,‘N/A‘) ‘N/A‘
>>> d={} >>> d[1]=1 >>> d[2]=2 >>> d[1]=1>>> d.values() dict_values([1, 2])
>>> phonebook={‘tr‘:‘1234‘}
>>> print("tr‘s phone number is %(tr)s." %phonebook)
tr‘s phone number is 1234.
>>> items=[(‘name‘,‘koka‘),(‘age‘,18)] >>> d=dict(items) >>> d[‘name‘] ‘koka‘
dict函数也可以通过关键字参数来创建字典
>>> d = dict(name=‘koka‘,age=18) >>> d {‘name‘: ‘koka‘, ‘age‘: 18}
number=24 number=int(input("please input the number:")) if number == luck_num: print("Bingo!") elif number > luck_num: print("你输入的数字太大。") else: print("你输入的数字太小。")
name = input("what is your name ? ") if name.endswith(‘Gumby‘): if name.startswith(‘Mr.‘): print("hello Mr.Gumby") elif name.startswith(‘Mrs.‘): print(‘hello Mrs.Gumby‘) else: print(‘hello Gumby‘) else: print(‘hello strange‘)
luck_num = 26 counter=0 for i in range(3): number = int(input("please input int number:").strip()) if luck_num > number: print("please input bigger number") elif luck_num < number: print("please input smaller number") else: print("bingo") break else: print("too many time error") #最后的else语句只会在循环正常结束的情况下才会运行,如果中间被break了,就不会继续运行了。 luck_num = 26 counter=0 while counter < 3: number = int(input("please input int number:").strip()) counter+=1 if luck_num > number: print("please input bigger number") elif luck_num < number: print("please input smaller number") else: print("bingo") break else: print("too many time error")
for i in range(10): if i%2 ==0: continue print("这是奇数",i)
loop1 = 0 loop2 = 0 while True: loop1 +=1 print("Loop1:", loop1) break_flag = False #在父循环中设置一个跳出标志,子循环要想连父循环一起跳出,就改变这个标志。 while True: loop2 +=1 if loop2 ==5: break_flag = True #改变标志 break #跳出当前循环 print(‘Loop2:‘,loop2) if break_flag: print("接到子循环跳出通知,我也跳出循环") break
文件操作
打开文件
原文:http://www.cnblogs.com/koka24/p/5094978.html