最近在研究spark 还有 kafka , 想通过kafka端获取的数据,利用spark streaming进行一些计算,但搭建整个环境着实不易,故特此写下该过程,分享给大家,希望大家可以少走点弯路,能帮到大家!
操作系统 : ubuntu14.04 LTS
hadoop 2.7.1 伪分布式搭建
sbt-0.13.9
kafka_2.11-0.8.2.2
spark-1.3.1-bin-hadoop2.6
scala 版本 : 2.10.4
注: 请重视版本问题,之前作者用的是spark-1.4.1 ,scala版本是2.11.7 结果作业提交至spark-submit 总是失败,所以大家这点注意下!
hadooop 2.7.1 伪分布式搭建 大家可以参照 http://www.wjxfpf.com/2015/10/517149.html
kafka安装与测试:
kafka 有其自带默认的zookeeper 所以省去了我们一些功夫,现在可以开始测试下kafka:
bin/zookeeper-server-start.sh config/zookeeper.properties & 后台运行zookeeper
bin/kafka-server-start.sh config/server.properties & 后台启动kafka-server
现在,在1号终端输入HAHA,如果2号终端能输出HAHA,说明kafka测试成功!
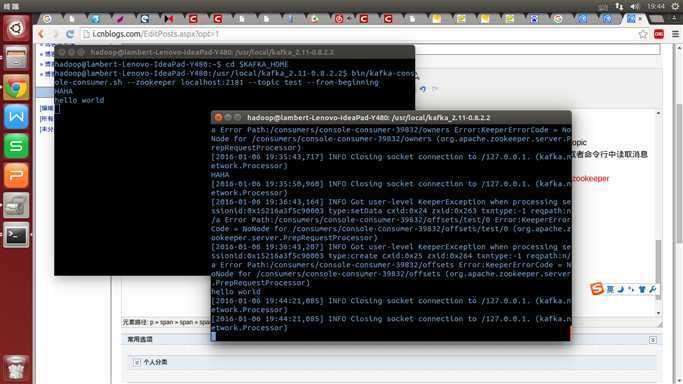
SBT构建一个关于单词计数的scala程序
其中,KafkaDemo.scala 代码如下
import java.util.Properties import kafka.producer._ import org.apache.spark.streaming._ import org.apache.spark.streaming.StreamingContext._ import org.apache.spark.streaming.kafka._ import org.apache.spark.SparkConf object KafkaDemo { def main(args: Array[String]) { val zkQuorum = "127.0.0.1:2181" val group = "test-consumer-group" val topics = "test" val numThreads = 2 val sparkConf = new SparkConf().setAppName("KafkaWordCount").setMaster("local[2]") val ssc = new StreamingContext(sparkConf, Seconds(10)) ssc.checkpoint("checkpoint") val topicpMap = topics.split(",").map((_,numThreads.toInt)).toMap val lines = KafkaUtils.createStream(ssc, zkQuorum, group, topicpMap).map(_._2) val words = lines.flatMap(_.split(" ")) val pairs = words.map(word => (word, 1)) val wordCounts = pairs.reduceByKey(_ + _) wordCounts.print() ssc.start() ssc.awaitTermination() } }
assmebly.sbt 代码如下
name := "KafkaDemo"
version := "1.0"
scalaVersion := "2.10.4"
libraryDependencies ++= Seq(
("org.apache.spark" %% "spark-core" % "1.3.1" % "provided")
)
libraryDependencies += "org.apache.spark" % "spark-streaming_2.10" % "1.3.1" % "provided"
libraryDependencies += "org.apache.spark" % "spark-streaming-kafka_2.10" % "1.3.0"
mergeStrategy in assembly <<= (mergeStrategy in assembly) { (old) =>
{
case PathList("org", "apache", xs @ _*) => MergeStrategy.first
case PathList(ps @ _*) if ps.last endsWith "axiom.xml" => MergeStrategy.filterDistinctLines
case PathList(ps @ _*) if ps.last endsWith "Log$Logger.class" => MergeStrategy.first
case PathList(ps @ _*) if ps.last endsWith "ILoggerFactory.class" => MergeStrategy.first
case x => old(x)
}
}
resolvers += "OSChina Maven Repository" at "http://maven.oschina.net/content/groups/public/"
externalResolvers := Resolver.withDefaultResolvers(resolvers.value, mavenCentral = false)
plugins.sbt 内容如下:
addSbtPlugin("com.eed3si9n" % "sbt-assembly" % "0.14.1")
请大家注意 :
mergeStrategy in assembly <<= (mergeStrategy in assembly) { (old) =>
{
case PathList("org", "apache", xs @ _*) => MergeStrategy.first
case PathList(ps @ _*) if ps.last endsWith "axiom.xml" => MergeStrategy.filterDistinctLines
case PathList(ps @ _*) if ps.last endsWith "Log$Logger.class" => MergeStrategy.first
case PathList(ps @ _*) if ps.last endsWith "ILoggerFactory.class" => MergeStrategy.first
case x => old(x)
}
}
这段代码只是针对我本机的解决依赖冲突的方法,如果没有这段代码,那么我打包的时候会有依赖冲突的发生,原因是不同包下有相同的类,解决的方法是合并依赖,下面是贴出没有这段代码的错误:
[error] (*:assembly) deduplicate: different file contents found in the following:
[error] /home/hadoop/.ivy2/cache/org.apache.spark/spark-streaming-kafka_2.10/jars/spark-streaming-kafka_2.10-1.3.0.jar:org/apache/spark/unused/UnusedStubClass.class
[error] /home/hadoop/.ivy2/cache/org.spark-project.spark/unused/jars/unused-1.0.0.jar:org/apache/spark/unused/UnusedStubClass.class
大家注意红色高亮的代码,当大家发生其他依赖冲突的时候,可以照猫画虎,解决依赖冲突
接下来,就是在较好的网络环境下进行打包,终端进入spark_kafka 目录 ,敲入sbt assembly , 耐心等代下载打包
$SPARK_HOME/bin/spark-submit --class "KafkaDemo" target/scala-2.10/KafkaDemo-assembly-1.0.jar
(打包成功的话,会有一个target 目录,而且target下有scala-2.10/KafkaDemo-assembly-1.0.jar ) 。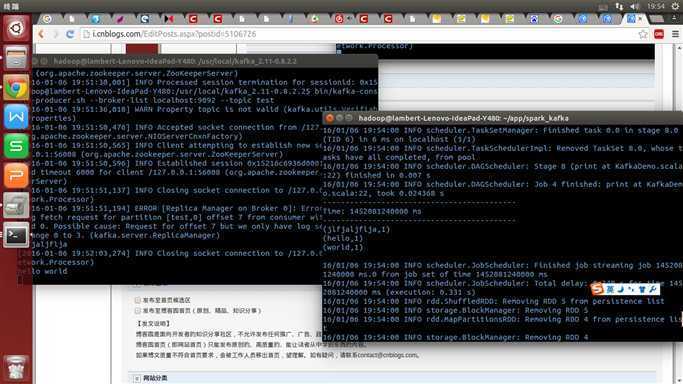
如果能看到该结果,那就恭喜你了。
弄这个其实弄了有一段时间,主要问题是依赖的解决,以及版本的问题。如果大家在做的过程发现出现有scala :no such method... 等问题的时候,说明是scala版本不符合了
其他的问题大家可以谷歌,此外强调一点,以上命令跟我个人目录环境有关,比如$SPARK_HOME代表我自己的spark 路径,如果你的目录跟我不一样,自己要换一换;
此文是面向有linux基础的同学,懂基本环境配置,这是最起码的要求!此文也给自己,毕竟确实辛苦!
SBT 构建 spark streaming集成kafka (scala版本)
原文:http://www.cnblogs.com/scnu-ly/p/5106726.html