今天去编程之美打酱油了,又遇到了数据类型取值范围的问题。下面整理一下网上其他地方的资料。
整理自:
http://blog.csdn.net/xuexiacm/article/details/8122267
和
http://blog.csdn.net/yingevil/article/details/6690863
如下:

#include<iostream> #include<string> #include <limits> using namespace std; int main() { cout << "type: \t\t" << "************size**************" << endl; cout << "bool: \t\t" << "所占字节数:" << sizeof(bool); cout << "\t最大值:" << (numeric_limits<bool>::max)(); cout << "\t\t最小值:" << (numeric_limits<bool>::min)() << endl; cout << "char: \t\t" << "所占字节数:" << sizeof(char); cout << "\t最大值:" << (numeric_limits<char>::max)(); cout << "\t\t最小值:" << (numeric_limits<char>::min)() << endl; cout << "signed char: \t" << "所占字节数:" << sizeof(signed char); cout << "\t最大值:" << (numeric_limits<signed char>::max)(); cout << "\t\t最小值:" << (numeric_limits<signed char>::min)() << endl; cout << "unsigned char: \t" << "所占字节数:" << sizeof(unsigned char); cout << "\t最大值:" << (numeric_limits<unsigned char>::max)(); cout << "\t\t最小值:" << (numeric_limits<unsigned char>::min)() << endl; cout << "wchar_t: \t" << "所占字节数:" << sizeof(wchar_t); cout << "\t最大值:" << (numeric_limits<wchar_t>::max)(); cout << "\t\t最小值:" << (numeric_limits<wchar_t>::min)() << endl; cout << "short: \t\t" << "所占字节数:" << sizeof(short); cout << "\t最大值:" << (numeric_limits<short>::max)(); cout << "\t\t最小值:" << (numeric_limits<short>::min)() << endl; cout << "int: \t\t" << "所占字节数:" << sizeof(int); cout << "\t最大值:" << (numeric_limits<int>::max)(); cout << "\t最小值:" << (numeric_limits<int>::min)() << endl; cout << "unsigned: \t" << "所占字节数:" << sizeof(unsigned); cout << "\t最大值:" << (numeric_limits<unsigned>::max)(); cout << "\t最小值:" << (numeric_limits<unsigned>::min)() << endl; cout << "long: \t\t" << "所占字节数:" << sizeof(long); cout << "\t最大值:" << (numeric_limits<long>::max)(); cout << "\t最小值:" << (numeric_limits<long>::min)() << endl; cout << "long long: \t\t" << "所占字节数:" << sizeof(long long); cout << "\t最大值:" << (numeric_limits<long long>::max)(); cout << "\t最小值:" << (numeric_limits<long long>::min)() << endl; cout << "unsigned long: \t" << "所占字节数:" << sizeof(unsigned long); cout << "\t最大值:" << (numeric_limits<unsigned long>::max)(); cout << "\t最小值:" << (numeric_limits<unsigned long>::min)() << endl; cout << "double: \t" << "所占字节数:" << sizeof(double); cout << "\t最大值:" << (numeric_limits<double>::max)(); cout << "\t最小值:" << (numeric_limits<double>::min)() << endl; cout << "long double: \t" << "所占字节数:" << sizeof(long double); cout << "\t最大值:" << (numeric_limits<long double>::max)(); cout << "\t最小值:" << (numeric_limits<long double>::min)() << endl; cout << "float: \t\t" << "所占字节数:" << sizeof(float); cout << "\t最大值:" << (numeric_limits<float>::max)(); cout << "\t最小值:" << (numeric_limits<float>::min)() << endl; cout << "size_t: \t" << "所占字节数:" << sizeof(size_t); cout << "\t最大值:" << (numeric_limits<size_t>::max)(); cout << "\t最小值:" << (numeric_limits<size_t>::min)() << endl; cout << "string: \t" << "所占字节数:" << sizeof(string) << endl; // << "\t最大值:" << (numeric_limits<string>::max)() << "\t最小值:" << (numeric_limits<string>::min)() << endl; cout << "type: \t\t" << "************size**************" << endl; return 0; }
代码是参考这个的:
http://blog.csdn.net/xuexiacm/article/details/8122267
我这边加入了long
long类型的测试后运行结果是: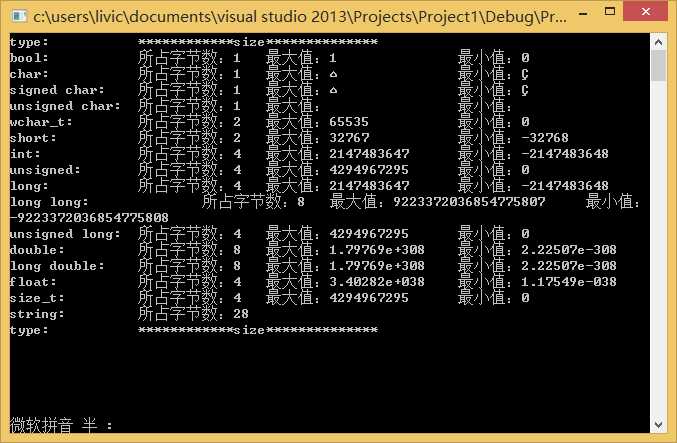
/*运行结果分析:
以上结果已经很明白了,一下补充说明几点:
概念、整型:表示整数、字符和布尔值的算术类型合称为整型(integral type)。
关于带符号与无符号类型:整型 int、stort 和 long 都默认为带符号型。要获得无符号型则必须制定该类型为unsigned,比如unsigned long。unsigned int类型可以简写为unsigned,也就是说,unsigned后不加其他类型说明符就意味着是unsigned int。
一字节表示八位,即:1byte = 8 bit;
int: 4byte = 32 bit有符号signed范围:2^31-1 ~ -2^31即:2147483647 ~ -2147483648无符号unsigned范围:2^32-1 ~ 0即:4294967295 ~ 0
long: 4 byte = 32 bit同int型
double: 8 byte = 64 bit范围:1.79769e+308 ~ 2.22507e-308
long double: 12 byte = 96 bit范围: 1.18973e+4932 ~ 3.3621e-4932
float: 4 byte = 32 bit范围: 3.40282e+038 ~ 1.17549e-038
int、unsigned、long、unsigned long 、double的数量级最大都只能表示为10亿,即它们表示十进制的位数不超过10个,即可以保存所有9位整数。而short只是能表示5位;
另外对于浮点说而言:使用double类型基本上不会有错。在float类型中隐式的精度损失是不能忽视的,二双精度计算的代价相对于单精度可以忽略。事实上,在有些机器上,double类型比float类型的计算要快得多。float型只能保证6位有效数字,而double型至少可以保证15位有效数字(小数点后的数位),long double型提供的精度通常没有必要,而且还要承担额外的运行代价。
double是8字节共64位,其中小数位占52位,2-^52=2.2204460492503130808472633361816e-16,量级为10^-16,故能够保证2^-15的所有精度。
在有些机器上,用long类型进行计算所付出的运行时代价远远高于用int类型进行同样计算的代价,所以算则类型前要先了解程序的细节并且比较long类型与int类型的实际运行时性能代价。
然后是另一篇关于__int64和long long的文章:
http://blog.csdn.net/yingevil/article/details/6690863
也转到这里:
在C语言的C99标准扩展了新的整数类型 long long,long是32位宽,占4个字节,long long通常被定义成 64 位宽,也就可以实现了在32位机器上可以扩展8字节的数据,GUN C也支持,当然在64位平台上就存在这个问题了。C99标准并没有硬性规定具体到某种平台上的某种整数类型究竟占用多少字节、能够表示多大范围的数值等,只是给出一条原则和一个参考数值集合,只要同时满足这两方面条件就算是符合 C 标准。 之后,我查看了C99标准: —The rank of long long int shall be greater than the rank of long int,which shall be greater than the rank of int,which shall be greater than the rank of short int,which shall be greater than the rank of signed char.
意思是说: long long 的级别高于 long ,long 的级别高于 int ,int 的级别高于 short ,short 的级别高于 char 。(另外有 _Bool 永远是最低级别)。级别高的整数类型的宽度大于等于级别较低的整数类型。
编译long long需要支持C99标准的编译器才行,VC并不支持,但有对应的类型__int64
在做ACM题时,经常都会遇到一些比较大的整数。而常用的内置整数类型常常显得太小了:其中long 和 int 范围是[-2^31,2^31),即-2147483648~2147483647。而unsigned范围是[0,2^32),即0~4294967295。也就是说,常规的32位整数只能够处理40亿以下的数。 那遇到比40亿要大的数怎么办呢?这时就要用到C++的64位扩展了。不同的编译器对64位整数的扩展有所不同。基于ACM的需要,下面仅介绍VC6.0与g++编译器的扩展。 VC的64位整数分别叫做__int64与unsigned __int64,其范围分别是[-2^63, 2^63)与[0,2^64),即-9223372036854775808~9223372036854775807与0~18446744073709551615(约1800亿亿)。对64位整数的运算与32位整数基本相同,都支持四则运算与位运算等。当进行64位与32位的混合运算时,32位整数会被隐式转换成64位整数。但是,VC的输入输出与__int64的兼容就不是很好了,如果你写下这样一段代码:
那么,在第2行会收到“error C2679: binary ‘>>‘ : no operator defined which takes a right-hand operand of type ‘__int64‘ (or there is no acceptable conversion)”的错误;在第3行会收到“error C2593: ‘operator <<‘ is ambiguous”的错误。那是不是就不能进行输入输出呢?当然不是,你可以使用C的写法:
scanf("%I64d",&a); printf("%I64d",a);
就可以正确输入输出了。当使用unsigned __int64时,把"I64d"改为"I64u"就可以了。 OJ通常使用g++编译器。其64位扩展方式与VC有所不同,它们分别叫做long long 与 unsigned long long。处理规模与除输入输出外的使用方法同上。对于输入输出,它的扩展比VC好。既可以使用
cin>>a; 3 cout<<a;
也可以使用
scanf("%lld",&a); printf("%lld",a);
最后我补充一点:作为一个特例,如果你使用的是Dev-C++的g++编译器,它使用的是"%I64d"而非"%lld"。
总结:
输入输出long long 也可以借助printf,scanf语句,
但对应的占位符却是和平台相关与编译器相关的:
在Linux中,gcc很统一的用%lld;在windows中,MinGW的gcc和VC6都需要用%I64d;
但VS2008却是用%lld。
另外,以后做ACM之类的比赛,提交c++代码时,一般是要选G++编译器提交的。
(整理)c++中找出各种数据类型的取值范围,布布扣,bubuko.com
原文:http://www.cnblogs.com/cquljw/p/3662821.html