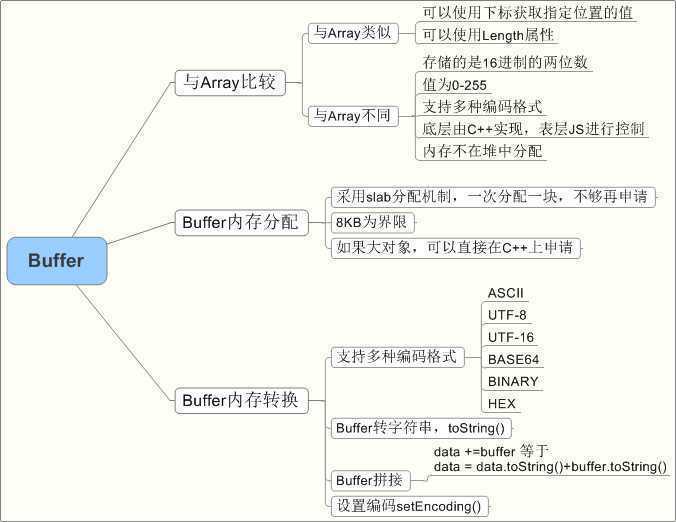
Node里面的Buffer其实就是用于网络请求、文件读取等等操作,而且是分配在堆外,不会占用堆内的内存,这也是因为本来V8的内存就很小,如果读取大文件,那就......
之前有看过Logstash的Buffer源码,感觉比这个高级多了....而Ruby中的Buffer则有点缓存的性质,支持大小的限制,以及定时刷新等等...
看来Buffer就是解决了V8之前应用于浏览器端偏小内存的限制,而直接在底层堆外申请大内存,但是又怕现用现申请增加CPU负载,所以采用了分块申请的形式。
另外Buffer中统一了编码格式,因此存储的数据都是十六进制的两位数,所以存与娶的时候不同的编码存储的内容是不一样的,一定要注意编码。
原文:http://www.cnblogs.com/xing901022/p/5111251.html