在过去10 年中,随着互联网应用的高速发展,企业积累的数据量越来越大,越来越多。随着Google MapReduce、Hadoop 等相关技术的出现,处理大规模数据变得简单起来,但是这些数据处理技术都不是实时的系统,它们的设计目标也不是实时计算。毕竟实时的计算系统和基于批处理模型的系统(如Hadoop)有着本质的区别。
但是随着大数据业务的快速增长,针对大规模数据处理的实时计算变成了一种业务上的需求,缺少“实时的Hadoop 系统”已经成为整个大数据生态系统中的一个巨大缺失。Storm 正是在这样的需求背景下出现的,Storm 很好地满足了这一需求。
在Storm 出现之前,对于需要实现计算的任务,开发者需要手动维护一个消息队列和消息处理者所组成的实时处理网络,消息处理者从消息队列中取出消息进行处理,然后更新数据库,发送消息给其他队列。所有这些操作都需要开发者自己实现。这种编程实现的模式存在以下缺陷。
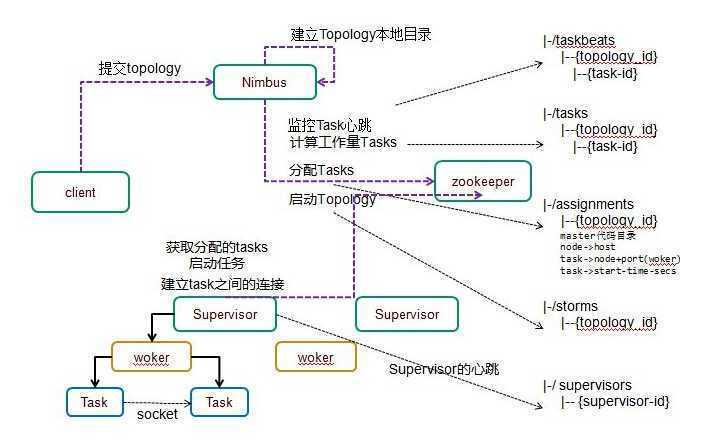
集群环境配置下的Storm存在两类节点:主控节点和工作节点。此外,为了实现集群的状态维护和配置管理,还需要一类特殊的节点:协调节点。整体架构如下图:
一、组成原理:
1、主控节点,即运行nimbus守护进程的节点。 nimbus负责在集群分发的代码,将任务分配给其他机器,并负责故障监测。
2、工作节点,即运行supervisor守护进程的节点。
supervisor监听分配所在机器,根据nimbus的委派,在必要时启动和关闭工作进程。(工作节点是实时数据处理作业运行的节点)
其中,计算在节点上的物理单元是worker,也即工作进程;计算的逻辑单元是executor,也即计算线程。(有点像spark哦) 然而计算的作业逻辑单元是topology,也称拓扑;计算的任务逻辑单元是task(还是有点像spark哦).
每个worker执行特定topology的executor子集,每个executor执行一个或多个task。
一个topology主要有两类组件(component):spout和bolt.分别是流失数据在topology中的起始单元和处理单元。
3、协调节点,即运行Zookeeper服务端进程的节点。
Zookeeper是一种分布式的状态协同服务,通过放松一致性的要求,为应用建立高层的协同原语(阻塞和更强一致性的要求),当前分布式系统中,广泛应用于状态监控和配置管理。
二、Storm主要的编程概念:spout、blot和topology。
1、spout 是流式处理的源头,是一个计算的起始单元,它封装数据源中的数据为storm可以识别的数据项。 spout可以从消息中间件中(如kafka、kestrel等)中读取数据产生流式元祖数据,也可以从其他接口如Twitter streaming API直接获取流式数据。
2、bolt 是处理过程单元,从输入流中获取一定数量的数据项处理后,将结果作为输出流发送。流式数据处理的业务逻辑,大部分是在bolt中实现的,如各类函数、过滤器、连接操作、聚集操作、数据库操作等。
3、topology是由spout和bolt为点组成的网络,网络中的边表示一个bolt订阅了某个或某个其他bolt或spout的输出流。topology可以是任意复杂多阶段流计算的网络,在Storm急群众提交后立即运行。
storm概念学习
原文:http://www.cnblogs.com/yangsy0915/p/5118950.html