Storm架构如下图所示:
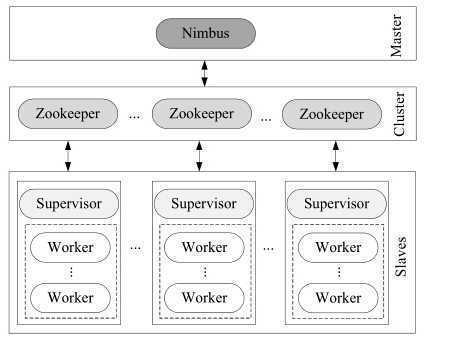
1、主控节点(Master Node)
运行Storm nimbus后台服务的节点(Nimbus),它是storm系统的中心,负责接收用户提交的作业(如同spark submit一样 即为jar包形式保存的topology代码),通过Zookeeper向每个工作节点分配处理任务(有进程级的也有线程级别的)
2、工作节点(Work Node)
运行Storm supervisor后台服务的节点。用来监听nimbus分配的任务并下载作业副本,启动、暂停或撤销任务的工作进程及其线程。其中工作进程执行指定topology的子集,而同一个topology可以由多个工作进程完成;一个工作进程由多个工作线程组成,工作线程是spout/bolt的运行时实例,数量是由spout/bolt的数目及其配置确定。
3、控制台节点(Web console Node)
运行storm UI后台服务的节点。实际上是一个Web服务器,在指定端口提供页面服务。用户可以通过使用浏览器访问控制台节点的Web页面,提交、暂停和撤销作业,也可以以只读的形式获取系统配置、作业及各个组件的运行时状态。(如果需要实现作业的管理,Storm UI须和Storm nimbus部署在同一台机器上,UI进程会检查本机是否存在nimbus的连接,若不存在可导致UI部分功能无法正常工作.)
4、协调节点(Coordinate Node)
运行Zookeeper进程的节点,numbus和supervisor之间所有的协调,包括分布式状态维护和分布式配置管理,都是通过该协调节点实现的。
作业提交:
1、首先,如同spark-submit执行一样,将作业达成jar包,通过Storm的客户端命令或者控制台节点的Web接口,提交至Storm系统的主控节点。
2、主控节点根据系统的全局配置和作业中的局部配置,将接受的代码分发至调度的工作节点。
3、工作节点下载来自主控节点的代码包,并根据主控节点的调度生成相关的工作进程和线程。
原文:http://www.cnblogs.com/yangsy0915/p/5119135.html