基础:linux常用命令、Java编程基础
大数据:科学数据、金融数据、物联网数据、交通数据、社交网络数据、零售数据等等。
Hadoop: 一个开源的分布式存储、分布式计算平台.(基于Apache)
Hadoop的组成:
HDFS:分布式文件系统,存储海量的数据。
MapReduce:并行处理框架,实现任务分解和调度。
Hadoop的用处:
搭建大型数据仓库,PB级数据的存储、处理、分析、统计等业务。
比如搜索引擎、网页的数据处理,各种商业智能、风险评估、预警,还有一些日志的分析、数据挖掘的任务。
Hadoop优势:高扩展、低成本、成熟的生态圈(Hadoop Ecosystem Map)
Hadoop开源工具:
Hive:将SQL语句转换成一个hadoop任务去执行,降低了使用Hadoop的门槛。
HBase:存储结构化数据的分布式数据库,habase提供数据的随机读写和实时访问,实现 对表数据的读写功能。
zookeeper:就像动物管理员一样,监控hadoop集群里面每个节点的状态,管理整个集群 的配置,维护节点针之间数据的一次性等等。
hadoop的版本尽量选稳定版本,即较老版本。
===============================================
Hadoop的安装与配置:
1)在Linux中安装JDK,并设置环境变量
安装jdk: >> sudo apt-get install openjdk-7-jdk
设置环境变量:
>> vim /etc/profile
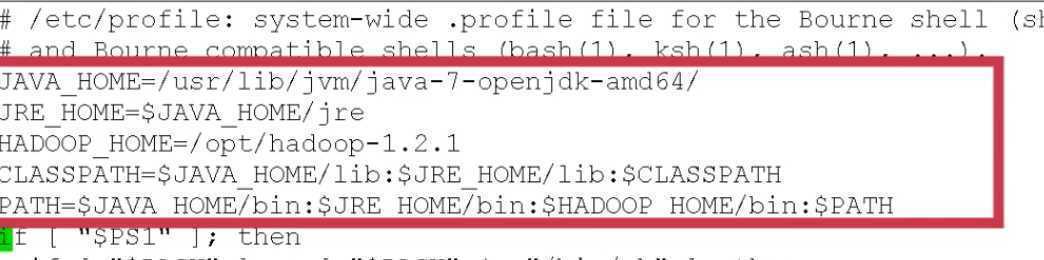
>> :wq
2)下载Hadoop,并设置Hadoop环境变量
下载hadoop解压缩:
>> cd /opt/hadoop-1.2.1/
>> ls
>> vim /etc/profile

>>:wq
3)修改4个配置文件
(a)修改hadoop-env.sh,设置JAVA_HOME
(b)修改core-site.xml,设置hadoop.tmp.dir, dfs.name.dir, fs.default.name
(c)修改mapred-site.xml, 设置mapred.job.tracker
(d)修改hdfs-site.xml,设置dfs.data.dir
>> cd conf
>> ls
>> vim mapred-site.xml

>> :wq
>> vim core-site.xml
第一部分

第二部分

>> :wq
>> vim hdfs-site.xml
>> :wq
>> vim hadoop-env.sh
>> :wq
# hadoop格式化
>> hadoop namenode -format
# hadoop启动
>> start-all.sh
# 通过jps命令查看当前运行进程
>> jps
看见以下进程即说明hadoop安装成功
原文:http://www.cnblogs.com/abelsu/p/5132686.html