同步和异步关注的是消息通信机制 (synchronous communication/ asynchronous communication)。所谓同步,就是在发出一个*调用*时,在没有得到结果之前,该*调用*就不返回。但是一旦调用返回,就得到返回值了。换句话说,就是由*调用者*主动等待这个*调用*的结果。而异步则是相反,*调用*在发出之后,这个调用就直接返回了,所以没有返回结果。换句话说,当一个异步过程调用发出后,调用者不会立刻得到结果。而是在*调用*发出后,*被调用者*通过状态、通知来通知调用者,或通过回调函数处理这个调用。
典型的异步编程模型比如Node.js
举个通俗的例子:你打电话问书店老板有没有《分布式系统》这本书,如果是同步通信机制,书店老板会说,你稍等,"我查一下",然后开始查啊查,等查好了(可能是5秒,也可能是一天)告诉你结果(返回结果)。而异步通信机制,书店老板直接告诉你我查一下啊,查好了打电话给你,然后直接挂电话了(不返回结果)。然后查好了,他会主动打电话给你。在这里老板通过"回电"这种方式来回调。
阻塞和非阻塞关注的是程序在等待调用结果(消息,返回值)时的状态.阻塞调用是指调用结果返回之前,当前线程会被挂起。调用线程只有在得到结果之后才会返回。非阻塞调用指在不能立刻得到结果之前,该调用不会阻塞当前线程。
还是上面的例子,你打电话问书店老板有没有《分布式系统》这本书,你如果是阻塞式调用,你会一直把自己"挂起",直到得到这本书有没有的结果,如果是非阻塞式调用,你不管老板有没有告诉你,你自己先一边去玩了, 当然你也要偶尔过几分钟check一下老板有没有返回结果。在这里阻塞与非阻塞与是否同步异步无关。跟老板通过什么方式回答你结果无关。
由于进程是不可直接访问外部设备的,所以只能调用内核去调用外部的设备(上下文切换),然后外部设备比如磁盘,读出存储在设备自身的数据传送给内核缓冲区,内核缓冲区在copy数据到用户进程的缓冲区。在外部设备响应的给到用户进程过程中,包含了两个阶段;由于数据响应方式的不同,所以就有了不同的I/O模型。
一般有五种I/O模型:
阻塞式I/O模型:
默认情况下,所有套接字都是阻塞的。进程挂起,内核等待外部IO响应,IO完成传送数据到kernel buffer,数据再从buffer复制到用户的进程空间
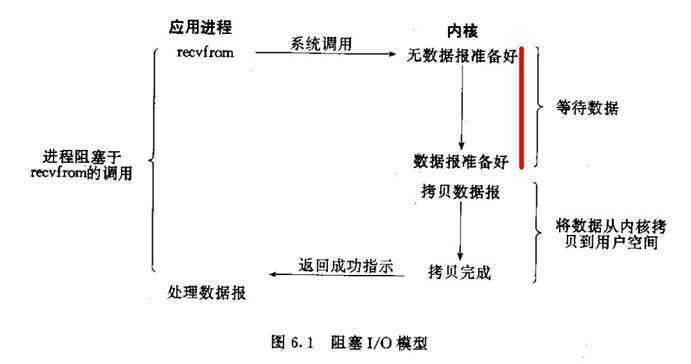
非阻塞式I/O:
在内核请求IO设备响应指令发出后,数据就开始准备,在此期间用户进程没有阻塞,也就是没有挂起,它一值在询问或者check数据有没有传送到kernel buffer中,忙等…。但是第二个阶段(数据从kernel buffer复制到用户进程空间)依然是阻塞的。但这种IO模型会大量的占用CPU的时间,效率很低效,很少使用。
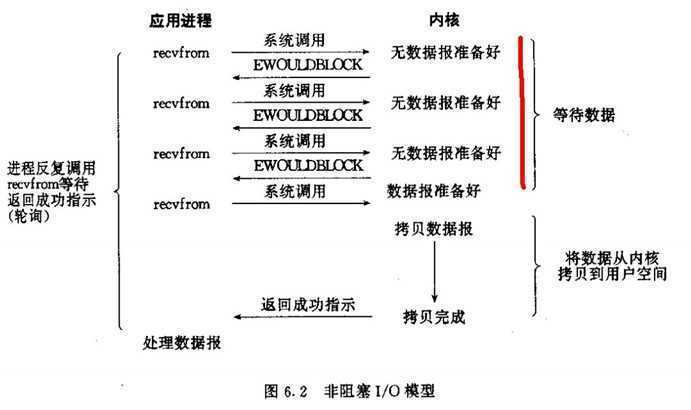
I/O多路复用(select,poll,epoll...):
在内核请求IO设备响应指令发出后,数据就开始准备,在此期间用户进程是阻塞的。数据从kernel buffer复制到用户进程的过程也是阻塞的。但是和阻塞I/O所不同的是,它可以同时阻塞多个I/O操作,而且可以同时对多个读操作,多个写操作的I/O函数进行检测,直到有数据可读或可写时,才真正调用I/O操作函数,也就是说一个线程可以响应多个请求。
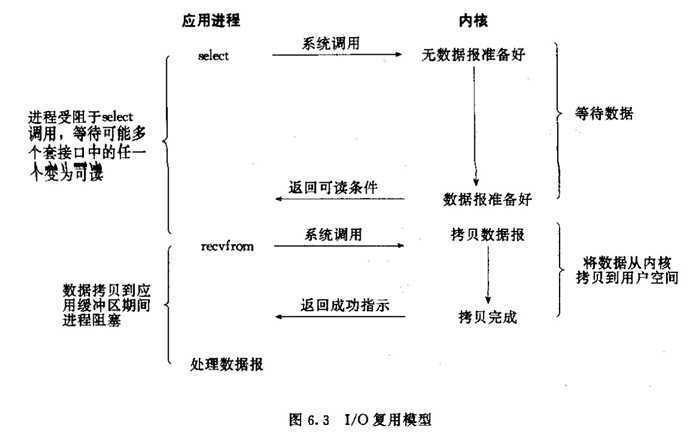
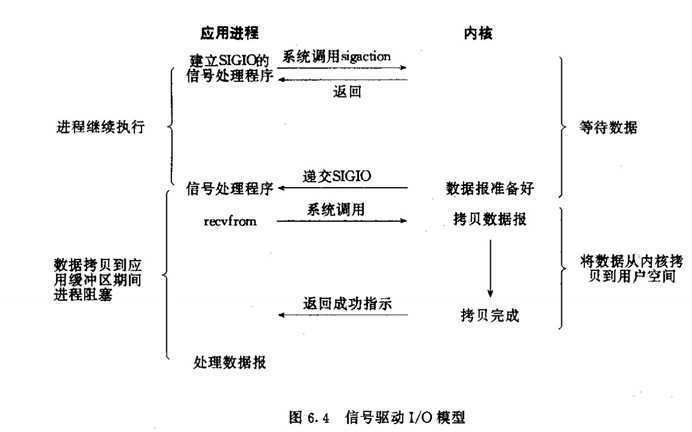
信号驱动式I/O(事件驱动)
第一阶段是非阻塞的,当数据传送的kernel buffer后,直接用信号的方式通知线程,用的不多
异步I/O:
在整个操作(包括将数据从内核拷贝到用户空间)完成后才通知用户进程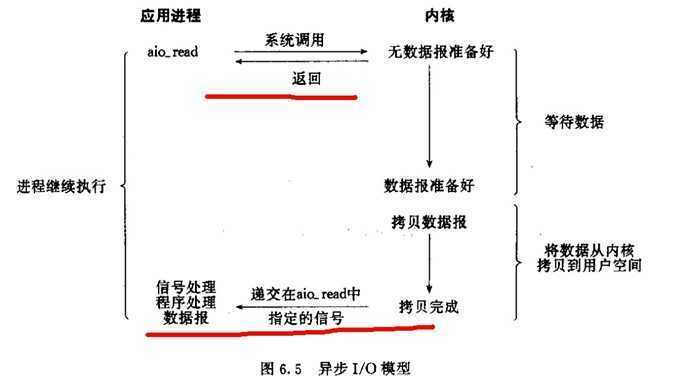
整个的汇总
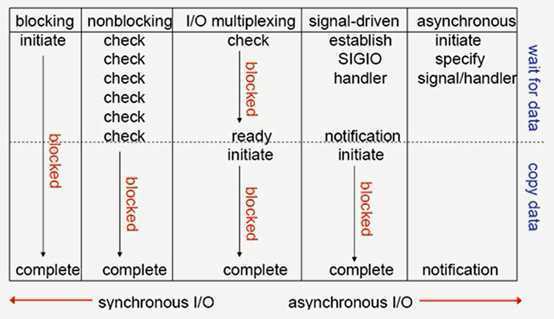
这三种模式都是属于IO复用模型。
select,poll是主动查询,它们可以同时查询多个fd(文件句柄)的状态,另外select有fd个数的限制,poll没有限制。select和poll不同的是,他们创建的事件描述符不同,select创建读、写、异常三个集合,而poll在一个集合内设定三种描述,由于select和poll每个循环都会检查事件的发生,而poll的事件比较少,性能上比select要好一些;
epoll是基于回调函数的,无轮询。如果当套接字比较多的时候,每次select()都要通过遍历FD_SETSIZE个Socket来完成调度,不管哪个Socket是活跃的,都遍历一遍。这会浪费很多CPU时间。如果能给套接字注册某个回调函数,当他们活跃时,自动完成相关操作,那就避免了轮询,这正是epoll(Linux)、kqueue(FreeBSD)、/dev/poll(soloris)做的。举个经典例子,假设你在大学读书,住的宿舍楼有很多间房间,你的朋友要来找你。select版宿管大妈就会带着你的朋友挨个房间去找,直到找到你为止。而epoll版宿管大妈会先记下每位同学的房间号,你的朋友来时,只需告诉你的朋友你住在哪个房间即可,不用亲自带着你的朋友满大楼找人。如果来了10000个人,都要找自己住这栋楼的同学时,select版和epoll版宿管大妈,谁的效率更高,不言自明。同理,在高并发服务器中,轮询I/O是最耗时间的操作之一,select、epoll、/dev/poll的性能谁的性能更高,同样十分明了。
由于web服务器是一对多的关系,通常完成并行处理的方式有多进程、多线程、异步三种方式。
多进程:多进程就是每个进程对应一个连接来处理请求,进程独立响应自己的请求,一个进程挂了,并不会影响到其他的请求;而且设计简单,不会产生内存泄漏等问题,因此进程比较稳定。但是进程在创建的时候一般是fork机制,会存在内存复制的问题,另外在高并发的情况下,上下文切换将很频繁,这样将消耗很多的性能和时间。早期的apache使用的prework模型就多进程方式,但是apache会预先创建几个进程,等待用户的响应,请求完毕,进程也不会结束。因此性能上有优化很多。
多线程:每个线程响应一个请求,由于线程之间共享进程的数据,所以线程的开销较小,性能就会提高。由于线程管理需要程序自己申请和释放内存,所以当存在内存等问题时,可能会运行很长时间才会暴露问题,所以在一定程度上还不是很稳定。apache的worker模式就是这种方式
异步的方式:nginx的epoll,apache的event也支持,不多说了
Nginx的IO模型是基于事件驱动的,使得应用程序在多个IO句柄间快速切换,实现所谓的异步IO。事件驱动服务器,最适合做的就是IO密集型工作,如反向代理,它在客户端与WEB服务器之间起一个数据中转作用,纯粹是IO操作,自身并不涉及到复杂计算。反向代理用事件驱动来做,显然更好,一个工作进程就可以run了,没有进程、线程管理的开销,CPU、内存消耗都小。
Apache这类应用服务器,一般要跑具体的业务应用,如科学计算、图形图像等。它们很可能是CPU密集型的服务,事件驱动并不合适。例如一个计算耗时2秒,那么这2秒就是完全阻塞的,什么event都没用。想想MySQL如果改成事件驱动会怎么样,一个大型的join或sort就会阻塞住所有客户端。这个时候多进程或线程就体现出优势,每个进程各干各的事,互不阻塞和干扰。当然,现代CPU越来越快,单个计算阻塞的时间可能很小,但只要有阻塞,事件编程就毫无优势。所以进程、线程这类技术,并不会消失,而是与事件机制相辅相成,长期存在。
总的说来,事件驱动适合于IO密集型服务,多进程或线程适合于CPU密集型服务
其实也就是说nginx比较适合做前端代理,或者处理静态文件(尤其高并发情况下),而apache适合做后端的应用服务器,功能强大[php, rewrite…],稳定性高。
原文:http://www.cnblogs.com/wxl-dede/p/5134636.html