(1) 给定数据集data和标签集label
样本个数为
sampNum = len(data)
(2) 将给定的所有examples分为10组
每个fold个数为
foldNum = sampNum/10
(3) 将给定的所有examples分为10组
参考scikit-learn的3.1节:Cross-validation
import np
from sklearn import cross_validation
# dataset
data = np.array([[1,3],[2,4],[3.1,3],[4,5],[5.0,0.3],[4.1,3.1]])
label = np.array([0,1,1,1,0,0])
sampNum= len(data)
# 10-fold (9份为training,1份为validation)
kf = KFold(len(data), n_folds=4)
iFold = 0
for train_index, val_index in kf:
iFold = iFold+1
X_train, X_val, y_train, y_val = data[train_index], data[val_index], label[train_index], label[val_index] # 这里的X_train,y_train为第iFold个fold的训练集,X_val,y_val为validation set
给定的数据集如下:


所有样本的指标集为:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
每个iFold(共4个)的训练集和validation set的index分别为:
iFold = 0 (训练集中包含6个examples,validation set 中包含3个examples)
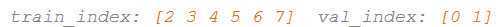
iFold = 1

iFold = 2
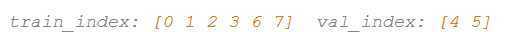
iFold = 3
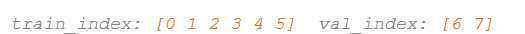
每个iFold的训练集和validation set分别为:
X_train, X_val, y_train, y_val = data[train_index], data[val_index], label[train_index], label[val_index]
Python如何进行10-fold validation training
原文:http://www.cnblogs.com/lutingting/p/5156475.html