上个博客写了Hadoop2.6.0的环境部署,下面写一个简单的基于数字排序的小程序,真正实现分布式的计算,原理就是对多个文件中的数字进行排序,每个文件中每个数字占一行,排序原理是按行读取后分块进行排序,最后对块进行合并,通俗来说就是首先对小于100的数据范围进行排序,然后对100-1000之间的数据进行排序,最后对大于1000的数据进行排序,最终这3块合成之后也一定是按顺序排列的,代码如下:
import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.Partitioner; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.GenericOptionsParser; public class Sort { public static class Map extends Mapper<Object, Text, IntWritable, IntWritable> { private static IntWritable data = new IntWritable(); public void map(Object key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); data.set(Integer.parseInt(line)); context.write(data, new IntWritable(1)); } } public static class Reduce extends Reducer<IntWritable, IntWritable, IntWritable, IntWritable> { private static IntWritable linenum = new IntWritable(1); public void reduce(IntWritable key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { for (IntWritable val : values) { context.write(linenum, key); linenum = new IntWritable(linenum.get() + 1); } } } public static class Partition extends Partitioner<IntWritable, IntWritable> { @Override public int getPartition(IntWritable key, IntWritable value, int numPartitions) { int MaxNumber = 65223; int bound = MaxNumber / numPartitions + 1; int keynumber = key.get(); for (int i = 0; i < numPartitions; i++) { if (keynumber < bound * i && keynumber >= bound * (i - 1)) return i - 1; } return 0; } } /** * @param args */ public static void main(String[] args) throws Exception { // TODO Auto-generated method stub Configuration conf = new Configuration(); String[] otherArgs = new GenericOptionsParser(conf, args) .getRemainingArgs(); if (otherArgs.length != 2) { System.err.println("Usage WordCount <int> <out>"); System.exit(2); } Job job = new Job(conf, "Sort"); job.setJarByClass(Sort.class); job.setMapperClass(Map.class); job.setPartitionerClass(Partition.class); job.setReducerClass(Reduce.class); job.setOutputKeyClass(IntWritable.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path(otherArgs[0])); FileOutputFormat.setOutputPath(job, new Path(otherArgs[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } }
将源文件上传到服务器后,进行编译,hadoop2.6.0的编译方式和之前的hadoop1.2.1不太一样,这次需要引入3个jar文件分别是:
share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.6.0.jar
share/hadoop/common/hadoop-common-2.6.0.jar
share/hadoop/common/lib/commons-cli-1.2.jar
编译命令这里为:
javac -classpath ../share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.6.0.jar:../share/hadoop/common/hadoop-common-2.6.0.jar:../share/hadoop/common/lib/commons-cli-1.2.jar Sort.java
如果忽略要警告可以添加-Xlint:deprecation参数进行编译:
javac -classpath ../share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.6.0.jar:../share/hadoop/common/hadoop-common-2.6.0.jar:../share/hadoop/common/lib/commons-cli-1.2.jar -Xlint:deprecation Sort.java
编译成功之后打包操作:
jar -cvf sort.jar *.class
打成sort.jar之后建立几个文件,格式就如下图所示:
然后上传到HDFS文件系统之后,可以用hadoop来跑一下:
hadoop jar sort.jar Sort /sort /sortoutput
注意:输出目录,不能使用原来的,如果原来存在一个目录,不管是空的还是非空的,那么hadoop都会报错,所以应该指定一个不存在的目录,让hadoop去新建他
等运行完毕,然后查看输出就行了:
hdfs dfs -cat /sortoutput/*
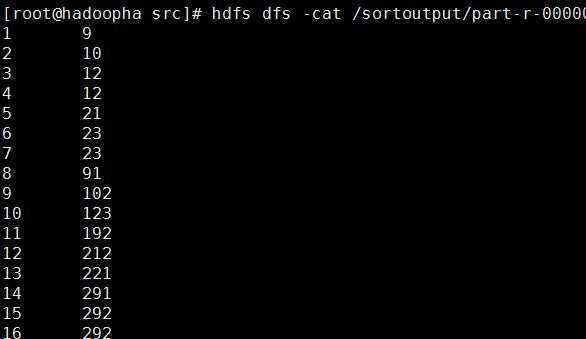
这样就简单的使用hadoop平台以分布式的方式运行了java应用
原文:http://www.cnblogs.com/freeweb/p/5158231.html