[首页]
[文章]
[教程]
首页
Web开发
Windows开发
编程语言
数据库技术
移动平台
系统服务
微信
设计
布布扣
其他
数据分析
首页
>
Web开发
> 详细
dede3.1分页文字采集过滤规则详说(图文教程)续二
时间:
2016-01-31 00:37:12
阅读:
176
评论:
0
收藏:
0
[点我收藏+]
稍微了解dede采集规则的朋友上篇内容完全可以略过,下面看看如何以静制动、以不变就万变地解决分页采集问题。
二、采集新目标
目标地址:
1、
http://www.tiansou.net/Html/Y_CYFW/R_Gzzj/F_Gzjh/index.html
2、
http://www.tiansou.net/Html/Y_CYFW/R_Gzzj/F_Gzjh/2007-2/9/20070209110903558.html
之所以选取两个目标页面,是因为以上的两个页面一个有分页,而另一个没有,并且在分页和全文取样部分有较大的差别。以下的说明是在为采集目标地址(首页)全部链接的基础上改动的,个别地方会显得蛇足,只为说明的方便。
目标文字部分头部代码1:
目标文字部分头部代码2:
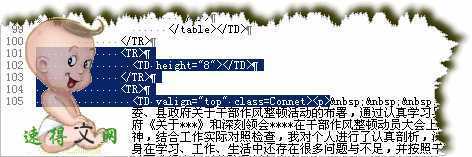
通过比较不难发现,两个文字部分的开始采集部分能确定下来为描黑部分,开头部分好说,代码如下:
复制代码
代码如下:
<TR>
<TD height="8"></TD>
</TR>
<TR>
<TD valign="top" class=Connet><p>
目标文尾及分页区域代码1:
目标文尾及分页区域代码2:
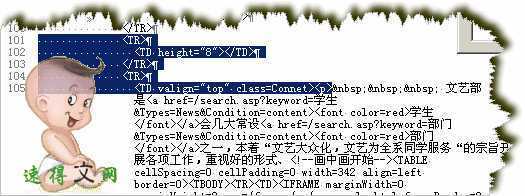
比较一下两个结尾,尽管想把第一个的结尾再往前提一点,但没法子,要考虑到全部链接的共同部分,就只好取描黑的部分了,这也给今后确定过滤规则添了点麻烦,这是后话。先把结尾部分确定了吧:
复制代码
代码如下:
</p>
</TD>
</TR>
dede3.1分页文字采集过滤规则详说(图文教程)续二
原文:http://www.jb51.net/article/9139.htm
踩
(
0
)
赞
(
0
)
举报
评论
一句话评论(
0
)
登录后才能评论!
分享档案
更多>
2021年09月23日 (328)
2021年09月24日 (313)
2021年09月17日 (191)
2021年09月15日 (369)
2021年09月16日 (411)
2021年09月13日 (439)
2021年09月11日 (398)
2021年09月12日 (393)
2021年09月10日 (160)
2021年09月08日 (222)
最新文章
更多>
2021/09/28 scripts
2022-05-27
vue自定义全局指令v-emoji限制input输入表情和特殊字符
2022-05-27
9.26学习总结
2022-05-27
vim操作
2022-05-27
深入理解计算机基础 第三章
2022-05-27
C++ string 作为形参与引用传递(转)
2022-05-27
python 加解密
2022-05-27
JavaScript-对象数组里根据id获取name,对象可能有children属性
2022-05-27
SQL语句——保持现有内容在后面增加内容
2022-05-27
virsh命令文档
2022-05-27
教程昨日排行
更多>
1.
list.reverse()
2.
Django Admin 管理工具
3.
AppML 案例模型
4.
HTML 标签列表(功能排序)
5.
HTML 颜色名
6.
HTML 语言代码
7.
jQuery 事件
8.
jEasyUI 创建分割按钮
9.
jEasyUI 创建复杂布局
10.
jEasyUI 创建简单窗口
友情链接
汇智网
PHP教程
插件网
关于我们
-
联系我们
-
留言反馈
- 联系我们:wmxa8@hotmail.com
© 2014
bubuko.com
版权所有
打开技术之扣,分享程序人生!