读一下源码,一个数组存储数据:
transient Entry[] table;
内部存key和value的内部类:
static class Entry<K,V> implements Map.Entry<K,V> { final K key; V value; Entry<K,V> next; final int hash; /** * Creates new entry. */ Entry( int h, K k, V v, Entry<K,V> n) { value = v; next = n; key = k; hash = h; } public final K getKey() { return key; } public final V getValue() { return value; } public final V setValue(V newValue) { V oldValue = value; value = newValue; return oldValue; } public final boolean equals(Object o) { if (!(o instanceof Map.Entry)) return false; Map.Entry e = (Map.Entry)o; Object k1 = getKey(); Object k2 = e.getKey(); if (k1 == k2 || (k1 != null && k1.equals(k2))) { Object v1 = getValue(); Object v2 = e.getValue(); if (v1 == v2 || (v1 != null && v1.equals(v2))) return true; } return false; } public final int hashCode() { return ( key== null ? 0 : key.hashCode()) ^ ( value== null ? 0 : value.hashCode()); } public final String toString() { return getKey() + "=" + getValue(); } /** * This method is invoked whenever the value in an entry is * overwritten by an invocation of put(k,v) for a key k that‘s already * in the HashMap. */ void recordAccess(HashMap<K,V> m) { } /** * This method is invoked whenever the entry is * removed from the table. */ void recordRemoval(HashMap<K,V> m) { } }
所以HashMap的数据结构为数组下的链表结构,如图:
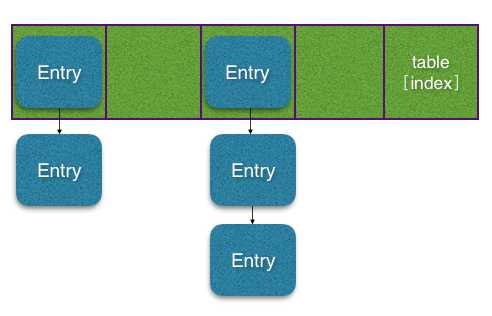
来看下put方法:
public V put(K key, V value) { if (key == null) return putForNullKey(value); int hash = hash(key.hashCode()); int i = indexFor(hash, table.length);//hash 找到数组中位置 //遍历链表 找出key相同的 for (Entry<K, V> e = table [i]; e != null ; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; e.recordAccess( this); return oldValue; } } modCount++; //没有key相同的 在数组的这个位置里新加一个值进去 addEntry(hash, key, value, i); return null; }
放数据的代码可以看出,从性能的角度来说,链表的长度越长,查找一个key是否在这个map中的时间就越长。而在是否同一个链表上的key是由key.hashCode()决定的。
还注意到放null为key的对象时,是直接放入数组的头部的。这样处理也是最好的实现了吧。否则一个null还要找一遍。
private V putForNullKey(V value) { for (Entry<K,V> e = table[0]; e != null; e = e. next) { if (e. key == null) { V oldValue = e. value; e. value = value; e.recordAccess( this); return oldValue; } } modCount++; addEntry(0, null, value, 0); return null; }
void addEntry (int hash, K key, V value, int bucketIndex) { Entry<K,V> e = table[bucketIndex]; table[bucketIndex] = new Entry<K,V>(hash, key, value, e); if (size++ >= threshold) resize(2 * table. length); }
HashMap的hash算法:
static int hash(int h) { // This function ensures that hashCodes that differ only by // constant multiples at each bit position have a bounded // number of collisions (approximately 8 at default load factor). h ^= (h >>> 20) ^ (h >>> 12); return h ^ (h >>> 7) ^ (h >>> 4); } /** * Returns index for hash code h. */ static int indexFor(int h, int length) { return h & (length-1); }
这个要详细看一下,hash方法中的算法在以前文章中有记录,可以参看:http://www.cnblogs.com/killbug/p/4560000.html
为了尽可能的试put的数据能平均的分布在数组上,提高map性能,上面的两个方法就是来做这件事的。
hash方法将key.hashcode再进行了一次hash,hash函数的通过若干次的移位、异或操作,把hashcode的“1位”变得“松散”,在接下来和数组长度的于操作时可以得出更平均的数组下标。
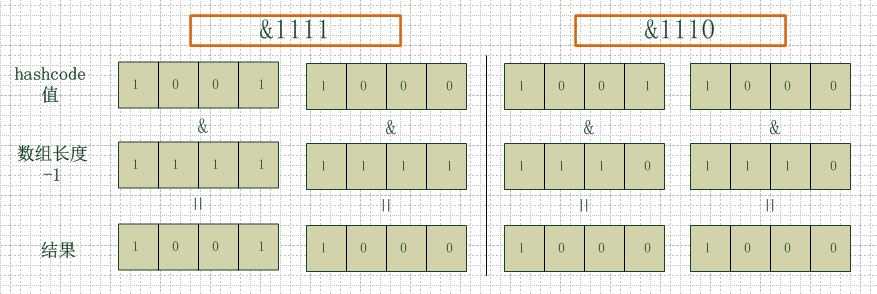
我们注意到数组的length被要求是2的幂次方,如此在做与操作的时候减1就变成1111这种,如此是最好的。
看下图,左边两组是数组长度为16(2的4次方),右边两组是数组长度为15。两组的hashcode均为8和9,但是很明显,当它们和1110“与”的时候,产生了相同的结果,也就是说它们会定位到数组中的同一个位置上去,这就产生了碰撞,8和9会被放到同一个链表上,那么查询的时候就需要遍历这个链表,得到8或者9,这样就降低了查询的效率。同时,我们也可以发现,当数组长度为15的时候,hashcode的值会与14(1110)进行“与”,那么最后一位永远是0,而0001,0011,0101,1001,1011,0111,1101这几个位置永远都不能存放元素了,空间浪费相当大,更糟的是这种情况中,数组可以使用的位置比数组长度小了很多,这意味着进一步增加了碰撞的几率,减慢了查询的效率!
原文:http://www.cnblogs.com/killbug/p/5177813.html