冒泡算法:
实现1:
a = [10,4,33,21,54,3,8,11,5,22,2,1,17,13,6] def bubble(badlist): sort = False while not sort: sort = True for i in range(len(badlist)-1): if badlist[i]>badlist[i+1]: sort = False badlist[i],badlist[i+1] = badlist[i+1],badlist[i] bubble(a) print(a)
实现2
data = [10,4,33,21,54,3,8,11,5,22,2,1,17,13,6]
for j in range(len(data)):
for i in range(len(data)-1):
if data[i] > data[i+1]:
data[i+1],data[i] = data[i],data[i+1]
# tmp=data[i]
#
# data[i] = data[i+1]
#
# data[i+1] = tmp
print(data)
for (i=1; i<=n; i++)
x++;
for (i=1; i<=n; i++)
for (j=1; j<=n; j++)
x++;
第一个for循环的时间复杂度为Ο(n),第二个for循环的时间复杂度为Ο(n2),则整个算法的时间复杂度为Ο(n+n2)=Ο(n2)。
常数时间
若对于一个算法, 的上界与输入大小无关,则称其具有常数时间,记作
的上界与输入大小无关,则称其具有常数时间,记作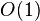 时间。一个例子是访问数组中的单个元素,因为访问它只需要一条指令。但是,找到无序数组中的最小元素则不是,因为这需要遍历所有元素来找出最小值。这是一项线性时间的操作,或称
时间。一个例子是访问数组中的单个元素,因为访问它只需要一条指令。但是,找到无序数组中的最小元素则不是,因为这需要遍历所有元素来找出最小值。这是一项线性时间的操作,或称 时间。但如果预先知道元素的数量并假设数量保持不变,则该操作也可被称为具有常数时间。
时间。但如果预先知道元素的数量并假设数量保持不变,则该操作也可被称为具有常数时间。
对数时间
若算法的T(n) = O(log n),则称其具有对数时间
对数时间的算法是非常有效的,因为每增加一个输入,其所需要的额外计算时间会变小。
递归地将字符串砍半并且输出是这个类别函数的一个简单例子。它需要O(log n)的时间因为每次输出之前我们都将字符串砍半。 这意味着,如果我们想增加输出的次数,我们需要将字符串长度加倍。
线性时间
如果一个算法的时间复杂度为O(n),则称这个算法具有线性时间,或O(n)时间。非正式地说,这意味着对于足够大的输入,运行时间增加的大小与输入成线性关系。例如,一个计算列表所有元素的和的程序,需要的时间与列表的长度成正比。
原文:http://www.cnblogs.com/luoye00/p/5188368.html
 而呈
而呈