网站经常会被各种爬虫光顾,有的是搜索引擎爬虫,有的不是,通常情况下这些爬虫都有UserAgent,而我们知道UserAgent是可以伪装的,UserAgent的本质是Http请求头中的一个选项设置,通过编程的方式可以给请求设置任意的UserAgent。
所以通过UserAgent判断请求的发起者是否是搜索引擎爬虫(蜘蛛)的方式是不靠谱的,更靠谱的方法是通过请求者的ip对应的host主机名是否是搜索引擎自己家的host的方式来判断。
要获得ip的host,在windows下可以通过nslookup命令,在linux下可以通过host命令来获得,例如:
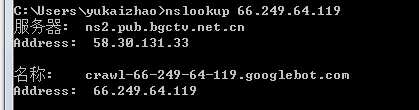
这里我在windows下执行了nslookup ip 的命令,从上图可以看到这个ip的主机名是crawl-66-249-64-119.googlebot.com。 这说明这个ip是一个google爬虫,google爬虫的域名都是 xxx.googlebot.com.
我们也可以通过python程序的方式来获得ip的host信息,代码如下:
原文:http://www.cnblogs.com/zyh-club/p/5208743.html