什么是MapReduce ?
MapReduce是一种计算模型,简单的说就是将大批量的任务分解(Map)运行,然后再将分解运行的结果合并(Reduce)成终于结果。这样做的优点是任务在被分解后。能够通过大量机器进行并行计算。降低整个操作的时间。
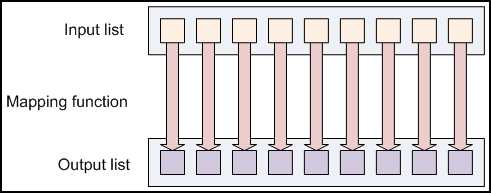
Mapping Lists(分解数据列表)
MapReduce程序的第一步叫做mapping,在这一步会有一些数据元素作为Mapper函数的输入数据。每次一个。
Mapper会把每次map得到的结果单独的传到一个输出数据元素里。
Reducing Lists(合并数据列表)
Reducing能够把数据聚集在一起。
reducer函数接收来自输入列表的迭代器,它会把这些数据聚合在一起,然后返回一个输出值。
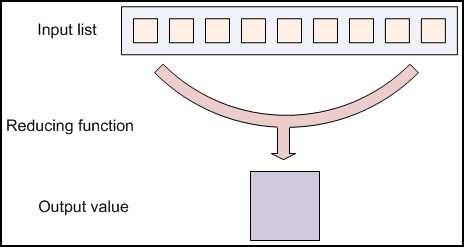
Reducing一般用来生成”总结“数据,把大规模的数据转变成更小的总结数据。
比方。"+"能够用来作一个reducing函数,去返回输入数据列表的值的总和。
举例:
Map-Reduce框架的运作全然基于<key,value>对,即数据的输入是一批<key,value>对,生成的结果也是一批<key,value>对,仅仅是有时候它们的类型不一样而已。
一个Map-Reduce任务的运行过程以及数据输入输出的类型例如以下所看到的:
(input)<k1,v1> -> map -> <k2,v2> -> combine -> <k2,v2> -> reduce -> <k3,v3>(output)
以下通过一个的样例来具体说明这个过程
1 WordCount(词频统计)演示样例
这也是Hadoop自带的一个样例,目标是统计文本文件里单词的个数。
如果有例如以下的两个文本文件来执行WorkCount程序:
Hello World Bye World
Hello Hadoop GoodBye Hadoop
2 map数据输入
Hadoop针对文本文件缺省使用LineRecordReader类来实现读取,一行一个key/value对。key取偏移量,value为行内容。
下表是map1的输入数据:
| Key1 | Value1 |
| 0 | Hello World Bye World |
下表是map2的输入数据:
| Key1 | Value1 |
| 0 | Hello Hadoop GoodBye Hadoop |
| Key2 | Value2 |
| Hello | 1 |
| World | 1 |
| Bye | 1 |
| World | 1 |
下表是map2的输出结果
| Key2 | Value2 |
| Hello | 1 |
| Hadoop | 1 |
| GoodBye | 1 |
| Hadoop | 1 |
下表是combine1的输出
| Key2 | Value2 |
| Hello | 1 |
| World | 2 |
| Bye | 1 |
下表是combine2的输出
| Key2 | Value2 |
| Hello | 1 |
| Hadoop | 2 |
| GoodBye | 1 |
下表是reduce的输出
| Key2 | Value2 |
| Hello | 2 |
| World | 2 |
| Bye | 1 |
| Hadoop | 2 |
| GoodBye | 1 |
即实现了WordCount(词频统计)的处理。
下图是用MapReduce实现(WordCount)词频统计的流程图:

原文:http://www.cnblogs.com/mengfanrong/p/5209475.html