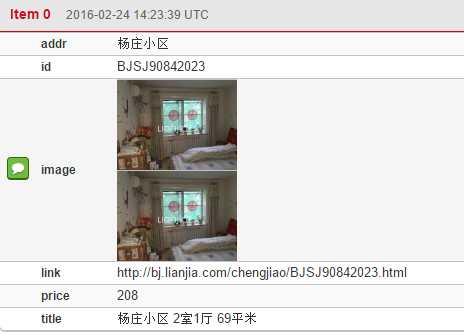
- 抓取图片并显示在item里:
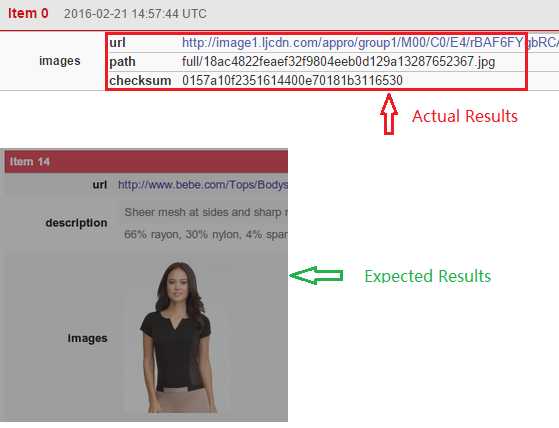
下面来正式进入本文的主题,抓取链家成交房产的信息并显示房子图片:
1. 创建一个scrapy project:
scrapy startproject lianjia_shub
这时会在当前文件夹下创建如下文件夹:
│ scrapy.cfg
│
└─lianjia_shub
│ items.py
│ pipelines.py
│ settings.py
│ __init__.py
│
└─spiders
__init__.py
2. 定义item:
import scrapy
class LianjiaShubItem(scrapy.Item):
id = Field()
title = Field()
price = Field()
addr = Field()
link = Field()
# 这里需要注意image这个字段
# image字段用来存储抓取到的<img>,这样就可以在ScrapingHub的Item Browser里查看图片了
# 而且这个名字必须是image,不然是不会显示图片的
image = Field()
3. 创建spider:
cmd里运行以下命令:
scrapy genspider lianjia http://bj.lianjia.com/chengjiao
定义spider:
# -*- coding: utf-8 -*-
import scrapy
from scrapy.spiders.init import InitSpider
from lianjia_shub.items import LianjiaShubItem
class LianjiaSpider(InitSpider):
name = "lianjia"
allowed_domains = ["http://bj.lianjia.com/chengjiao/"]
start_urls = []
def init_request(self):
return scrapy.Request(‘http://bj.lianjia.com/chengjiao/pg1/‘, callback=self.parse_detail_links)
def parse_detail_links(self, response):
house_lis = response.css(‘.clinch-list li‘)
for house_li in house_lis:
link = house_li.css(‘.info-panel h2 a::attr("href")‘).extract_first().encode(‘utf-8‘)
self.start_urls.append(link)
return self.initialized()
def parse(self, response):
house = LianjiaShubItem()
house[‘link‘] = response.url
house[‘id‘] = response.url.split(‘/‘)[-1].split(‘.‘)[0]
image_url = response.css(‘.pic-panel img::attr(src)‘).extract_first()
# image是一个list。在Scrapinghub中显示的时候会把image里所有的图片显示出来。
house[‘image‘] = [image_url, image_url]
house[‘title‘] = response.css(‘.title-box h1::text‘).extract_first()
house[‘addr‘] = response.css(‘.info-item01 a::text‘).extract_first()
house[‘price‘] = response.css(‘.love-money::text‘).extract_first()
return house
4. 下面我们就需要到Scrapinghub(http://scrapinghub.com/platform/)上注册一个账户。
5. 安装Scrapinghub客户端命令Shub:
pip install shub
6. 在Scrapinghub上创建一个project,并找到对应的api key:
api key: 点击账户 -> Account Settings -> API Key
7. 使用api key和project id登录shub:
shub login
手动输入api key之后会创建一个scrapinghub的配置文件scrapinghub.yml:
8. 把spider部署到Scrapinghub:
shub deploy <projectid>
Project ID可以在链接中找到:
https://dash.scrapinghub.com/p/<projectid>/jobs/
9. 在Scrapinghub上运行spider:
Scrapinghub上的job对应于我们定义的spider:
https://dash.scrapinghub.com/p/<projectid>/spider/lianjia/
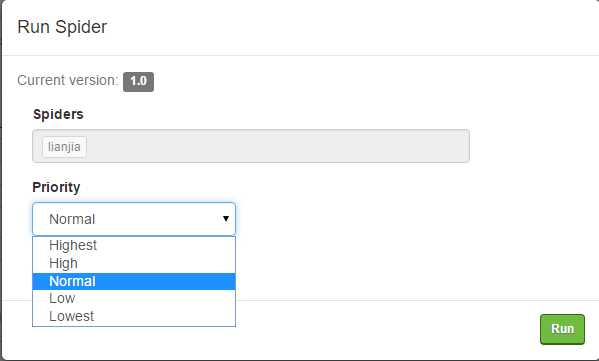
点击页面右上角的Run Spider:
在弹出的对话框中选择Spider的优先级后运行。(如果不想等太长时间的话可以设置成 Highest):
10. 执行结束后可以点击items查看抓取到的信息: