上一篇文章中我们总结了常用的比较排序算法,主要有冒泡排序,选择排序,插入排序,归并排序,堆排序,快速排序等。
这篇文章中我们来探讨一下常用的非比较排序算法:计数排序,基数排序,桶排序。在一定条件下,它们的时间复杂度可以达到O(n)。
这里我们用到的唯一数据结构就是数组,当然我们也可以利用链表来实现下述算法。
计数排序使用一个额外的数组C,根据数组C来将A中的元素排到正确的位置。
通俗地理解,例如有10个年龄不同的人,统计出有8个人的年龄比A小,那A的年龄就排在第9位,用这个方法可以得到每个人的位置,也就排好了序。当然,年龄有重复时需要特殊处理(保证稳定性),这就是为什么最后要反向填充目标数组,以及将每个数字的统计减去1的原因。算法的步骤如下:
计数排序的实现代码如下:
#include<iostream> using namespace std; // 分类 ------------- 内部非比较排序 // 数据结构 ---------- 数组 // 最差时间复杂度 ---- O(n + k) // 最优时间复杂度 ---- O(n + k) // 平均时间复杂度 ---- O(n + k) // 最差空间复杂度 ---- O(n + k) const int k = 100; // 这里排序[1,100]内的整数(k=100) int C[k]; // 存放数组元素的正确位置 void countingsort(int A[], int n) { for (int i = 0; i < k; i++) // 初始化,将数组C中的元素置0(此步骤可省略,整型数组元素默认值为0) { C[i] = 0; } for (int i = 0; i < n; i++) // 使C[i]保存着等于i的元素个数 { C[A[i]]++; } for (int i = 1; i < k; i++) // 使C[i]保存着小于等于i的元素个数,排序后元素i就放在第C[i]个输出位置上 { C[i] = C[i] + C[i - 1]; } int *B = (int *)malloc((n)* sizeof(int));// 分配临时空间,长度为n,用来暂存中间数据 for (int i = n - 1; i >= 0; i--)// 从后向前扫描保证计数排序的稳定性(重复元素相对次序不变) { B[C[A[i]] - 1] = A[i]; // 把每个元素A[i]放到它在输出数组B中的正确位置上 C[A[i]]--; // 当再遇到重复元素时会被放在当前元素的前一个位置上保证计数排序的稳定性 } for (int i = 0; i < n; i++) //把临时空间B中的数据拷贝回A { A[i] = B[i]; } free(B); // 释放临时空间 } int main() { int A[] = { 15, 22, 19, 46, 27, 73, 1, 19, 8 }; // 针对计数排序设计的输入,每一个元素都在[0,100]上且有重复元素 int n = sizeof(A) / sizeof(int); countingsort(A, n); printf("计数排序结果:"); for (int i = 0; i < n; i++) { printf("%d ",A[i]); } printf("\n"); return 0; }
下图给出了对{ 4, 1, 3, 4, 3 }进行计数排序的简单演示过程
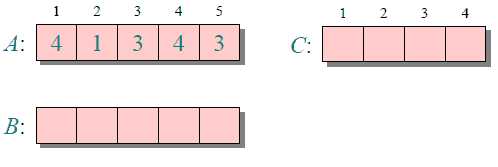
由于用来计数的数组C的长度取决于待排序数组中数据的范围(等于待排序数组的最大值与最小值的差加上1),这使得计数排序对于数据范围很大的数组,需要大量时间和内存。例如:计数排序是用来排序0到100之间的数字的最好的算法,但是它不适合按字母顺序排序人名。但是,计数排序可以用在基数排序算法中,能够更有效的排序数据范围很大的数组。
基数排序的原理是将整数按位数切割成不同的数字,然后按每个位数分别比较。由于整数也可以表达字符串(比如名字或日期)和特定格式的浮点数,所以基数排序也不是只能使用于整数。基数排序的发明可以追溯到1887年赫尔曼·何乐礼在打孔卡片制表机上的贡献。
它是这样实现的:将所有待比较正整数统一为同样的数位长度,数位较短的数前面补零。然后,从最低位开始,依次进行一次排序。这样从最低位排序一直到最高位排序完成以后,数列就变成一个有序序列。
基数排序的实现代码如下:
#include<iostream> using namespace std; // 分类 -------------- 内部非比较排序 // 数据结构 ---------- 数组 // 最差时间复杂度 ---- O(n * dn) // 最差空间复杂度 ---- O(n * dn) const int dn = 3; // 本程序排序的元素为三位数(含以下) const int radix = 10; // 基数为10 int C[radix]; int getdigit(int x, int d) // 获得元素x的第d位数字 { int radix[] = { 1, 1, 10, 100 };// 最大为三位数,所以这里只要到百位就满足了 return (x / radix[d]) % 10; } void countingsort(int A[], int n, int B[], int d)// 应用计数排序(依据元素的第d位数字)对元素排序 { for (int i = 0; i < radix; i++) // 初始化,将数组C中的元素置0 { C[i] = 0; } for (int i = 0; i < n; i++) // 使C[i]保存着当前位等于i的元素个数 { C[getdigit(A[i], d)]++; } for (int i = 1; i < radix; i++) // 使C[i]保存着当前位小于等于i的元素个数,排序后元素i就放在第C[i]个输出位置上 { C[i] = C[i] + C[i - 1]; } for (int i = n - 1; i >= 0; i--)// 从后向前扫描保证计数排序的稳定性(重复元素相对次序不变) { int j = getdigit(A[i], d); // 元素A[i]当前位数字为j B[C[j] - 1] = A[i]; // 根据当前位数字,把每个元素A[i]放到它在输出数组B中的正确位置上 C[j]--; // 当再遇到当前位数字同为j的元素时,会将其放在当前元素的前一个位置上保证计数排序的稳定性 } } void lsd_radixsort(int A[], int n) // 最低位优先基数排序 { int *B = (int*)malloc(n * sizeof(int));// 分配临时空间,长度为n,用来暂存中间数据 for (int d = 1; d <= dn; d++) // 从最低位开始到最高位 { countingsort(A, n, B, d); // 依据第d位调用计数排序 for (int i = 0; i < n; i++) // 把临时空间B中的数据拷贝回A,针对更高位的计数排序在此基础上继续对元素排序 { A[i] = B[i]; } } free(B); } int main() { int A[] = { 20, 90, 64, 289, 998, 365, 852, 123, 789, 456 };// 针对基数排序设计的输入 int n = sizeof(A) / sizeof(int); lsd_radixsort(A, n); printf("基数排序结果:"); for (int i = 0; i < n; i++) { printf("%d ", A[i]); } printf("\n"); return 0; }
下图给出了对{ 329, 457, 657, 839, 436, 720, 355 }进行基数排序的简单演示过程
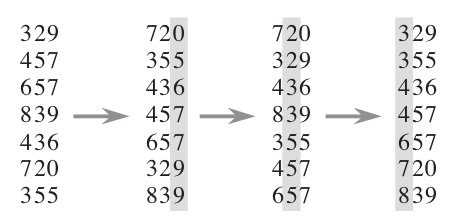
基数排序的时间复杂度是O(n * dn),其中n是排序元素个数,dn是数字位数。注意这不是说这个时间复杂度一定优于O(n log n),dn的大小取决于数字位的选择(比如比特位数),和待排序数据所属数据类型的全集的大小;dn决定了进行多少轮处理,而n是每轮处理的操作数目。
如果考虑和比较排序进行对照,基数排序的形式复杂度虽然不一定更小,但由于不进行比较,因此其基本操作的代价较小,而且如果适当的选择基数,dn一般不大于log n,所以基数排序一般要快过基于比较的排序,比如快速排序。
桶排序也叫箱排序。工作的原理是将数组分到有限数量的桶子里,每个桶子再个别排序(有可能再使用别的排序算法或是以递归方式继续使用桶排序进行排序)。
桶排序以下列程序进行:
桶排序的实现代码如下:
#include<iostream> using namespace std; // 分类 ------------- 内部非比较排序 // 数据结构 ---------- 数组 /* 本程序用数组模拟桶 */ const int bn = 10; // 我们这里打算使用10个桶 int C[bn]; // 临时数组,存放桶的边界信息 int MapToBucket(int x, int max) // 把元素x映射到桶中 { return (9 * x) / max; // 返回值范围{0,1,2,...,9},共10个桶 } void insertionsort(int A[], int left, int right)// 同一个桶内进行插入排序 { for (int i = left + 1; i <= right; i++) // 从桶内第二张牌开始抓,直到最后一张牌 { int get = A[i]; int j = i - 1; while (j >= left && A[j] > get) { A[j + 1] = A[j]; j--; } A[j + 1] = get; } } void countingsort(int A[], int n, int B[])// 应用计数排序把不同桶中的元素排好序 { for (int i = 0; i < bn; i++) // 初始化,将数组C中的元素置0 { C[i] = 0; } int max = A[0]; for (int i = 1; i < n; i++) // 获得输入数组中的最大值,用于把输入元素向桶中映射 { if (A[i] > max) max = A[i]; } for (int i = 0; i < n; i++) // 使C[i]保存着i号桶中元素的个数 { C[MapToBucket(A[i], max)]++; } for (int i = 1; i < bn; i++) // 求出每个桶的右边界索引:C[i]-1为第i号桶中最后一个元素的数组下标 { C[i] = C[i] + C[i - 1]; } for (int i = n - 1; i >= 0; i--)// 从后向前扫描保证计数排序的稳定性(重复元素相对次序不变) { int j = MapToBucket(A[i], max);// 元素A[i]位于第j号桶 B[C[j] - 1] = A[i]; // 把每个元素A[i]放到它在输出数组B中的正确位置上 C[j]--; // 当再遇到同一个桶中的元素时会被放在当前元素的前一个位置上 } // 执行完上述循环,C[j]变成了每个桶的左边界索引:C[j]为第j号桶第一个元素的数组下标(下边的插入排序要使用) } void bucketsort(int A[], int n) { int *B = (int *)malloc((n)* sizeof(int));// 分配临时空间,长度为n,用来暂存中间数据 countingsort(A, n, B); // 应用计数排序把不同桶中的元素排好序,同一桶中的元素暂时按输入次序存放 for (int i = 0; i < n; i++) // 把临时空间B中的数据拷贝回A { A[i] = B[i]; } free(B); // 释放临时空间 for (int i = 0; i < n; i++) // 对同一个桶中的元素应用插入排序 { int left = C[i] ; // C[i]为第i号桶中第一个元素的数组下标 int right = C[i + 1] - 1;// C[i+1]-1为第i号桶中最后一个元素的数组下标 if (left < right) insertionsort(A, left, right); } } int main() { int A[] = { 112, 240, 554, 75, 447, 789, 3, 69, 28, 447 };// 针对桶排序设计的输入 int n = sizeof(A) / sizeof(int); bucketsort(A, n); printf("桶排序结果:"); for (int i = 0; i < n; i++) { printf("%d ",A[i]); } printf("\n"); return 0; }
下图给出了对{ 29, 25, 3, 49, 9, 37, 21, 43 }进行桶排序的简单演示过程
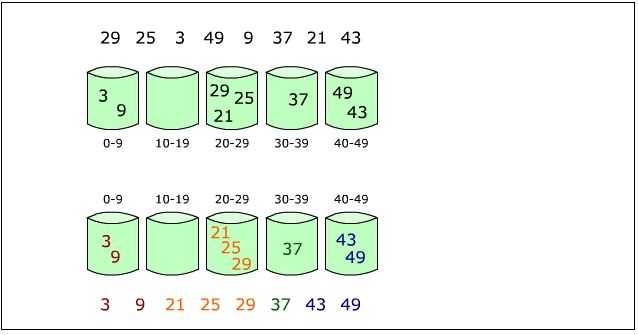
桶排序并不是比较排序,它不受到O(nlogn)下限的影响。它是鸽巢排序的一种归纳结果。当要被排序的数组内的数值是均匀分配的时候,桶排序使用线性时间
原文:http://www.cnblogs.com/eniac12/p/5332117.html