load、save方法的用法
DataFrame usersDF = sqlContext.read().load("hdfs://spark1:9000/users.parquet");
usersDF.select("name", "favorite_color").write()
.save("hdfs://spark1:9000/namesAndFavColors.parquet");
//load、save方法~指定文件格式
DataFrame peopleDF = sqlContext.read().format("json")
.load("hdfs://spark1:9000/people.json");
peopleDF.select("name").write().format("parquet")
.save("hdfs://spark1:9000/peopleName_java");
parquet数据源:
-》加载parquet数据
DataFrame usersDF = sqlContext.read().parquet("hdfs://spark1:9000/spark-study/users.parquet");
-》parquet分区自动推断
将只有两个字段的user.parquet存到 /users/gender=male/country=us/ 目录下(如下),

使用如下代码加载users.parquet的数据后,得到的usersDF中将会有4个字段
DataFrame usersDF = sqlContext.read().parquet("hdfs://spark1:9000/spark-study/users/gender=male/country=us/users.parquet");
其中gender字段的值为male,country的值为us
-》合并元数据
parquet合并元数据: http://www.cnblogs.com/key1309/p/5332089.html
json数据源:
DataFrame studentScoresDF = sqlContext.read().json("hdfs://spark1:9000/spark-study/students.json");
//json数据源的格式要求:
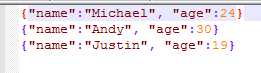
Hive数据源
// 待续。。。
JDBC数据源:
http://www.cnblogs.com/key1309/p/5350179.html
load、save方法、spark sql的几种数据源
原文:http://www.cnblogs.com/key1309/p/5352365.html