# -*- coding: UTF-8 -*- from HTMLParser import HTMLParser import sys,urllib2,string,re,json reload(sys) sys.setdefaultencoding(‘utf-8‘) class hp(HTMLParser): def __init__(self): self.readingdata_a = False self.title = [] self.usite = [] HTMLParser.__init__(self) def handle_starttag(self,tag,attrs): #print tag if tag == ‘a‘:for h,v in attrs: if v == ‘entrylistItemTitle‘: self.readingdata_a = True self.usite.append(attrs[2][1]) def handle_data(self,data): if self.readingdata_a: self.title.append(data) def handle_endtag(self,tag): if tag == ‘a‘: self.readingdata_a = False def getdata(self): #return zip(self.title,self.usite) 通过zip函数将其一对一合并为tuple i=0 listr = [] while i<len(self.title): listr.append(self.title[i] +‘ : ‘+self.usite[i]) i=i+1 return listr url=‘http://www.cnblogs.com/dreamer-fish/archive/2016/03.html‘ request = urllib2.Request(url) response = urllib2.urlopen(request).read() yk=hp() yk.feed(response) dd = yk.getdata() for i in dd: print i yk.close
结果:
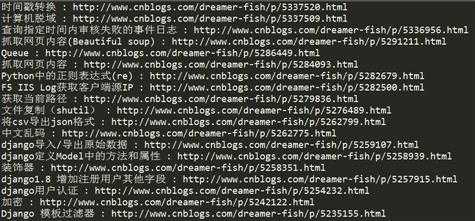
原文:http://www.cnblogs.com/dreamer-fish/p/5377438.html