上一篇介绍了客户端请求在tornado框架中的生命周期,其本质就是利用epoll和socket来获取并处理请求。在上一篇的内容中,我们只是给客户端返回了简单的字符串,如:“Hello World”,而在实际开发中,需要使用html文件的内容作为模板,然后将被处理后的数据(计算或数据库中的数据)嵌套在模板中,然后将嵌套了数据的html文件的内容返回给请求者客户端,本篇就来详细的剖析模板处理的整个过程。
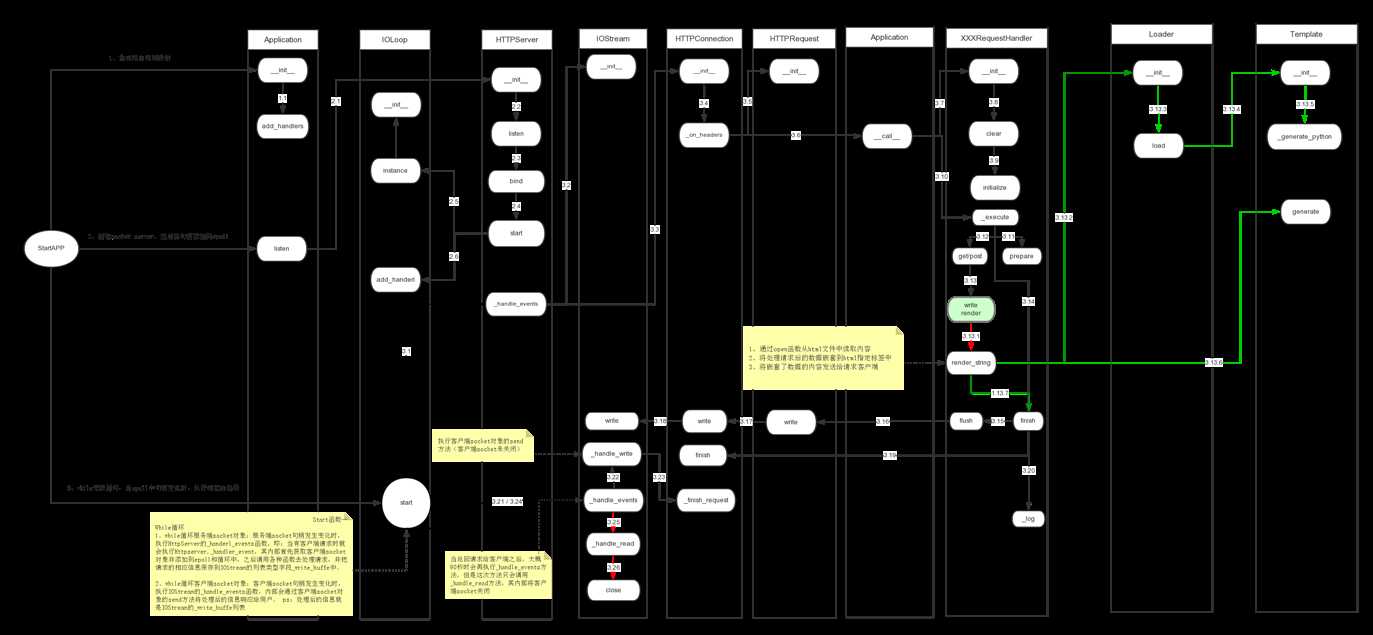
上图是返回给用户一个html文件的整个流程,较之前的Demo多了绿色流线的步骤,其实就是把【self.write(‘hello world‘)】变成了【self.render(‘main.html‘)】,对于所有的绿色流线只做了五件事:
所以,如果要返回给客户端对于一个html文件来说,根据上述的5个阶段其内容的变化过程应该是这样:

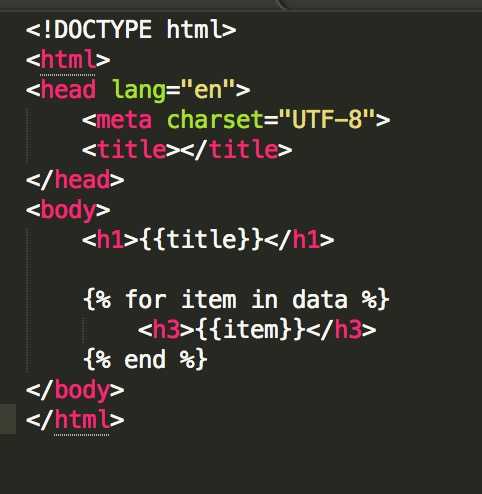
class MainHandler(tornado.web.RequestHandler): def get(self): self.render("main.html",**{‘data‘:[‘11‘,‘22‘,‘33‘],‘title‘:‘main‘}) [main.html] <!DOCTYPE html> <html> <head lang="en"> <meta charset="UTF-8"> <title></title> </head> <body> <h1>{{title}}</h1> {% for item in data %} <h3>{{item}}</h3> {% end %} </body> </html>
<!DOCTYPE html> <html> <head lang="en"> <meta charset="UTF-8"> <title></title> </head> <body> <h1>{{title}}</h1> {% for item in data %} <h3>{{item}}</h3> {% end %} </body> </html> 1.根据open函数读取html文件内容
第1块:‘<!DOCTYPE html><html><head lang="en"><meta charset="UTF-8"><title></title></head><h1>‘ 第2块:‘title‘ 第3块:‘</h1> \n\n‘ 第4块:‘for item in data‘ 第4.1块:‘\n <h3>‘ 第4.2块:‘item‘ 第4.3块:‘</h3> \n‘ 第五块:‘</body>‘ 2.将html内容分块
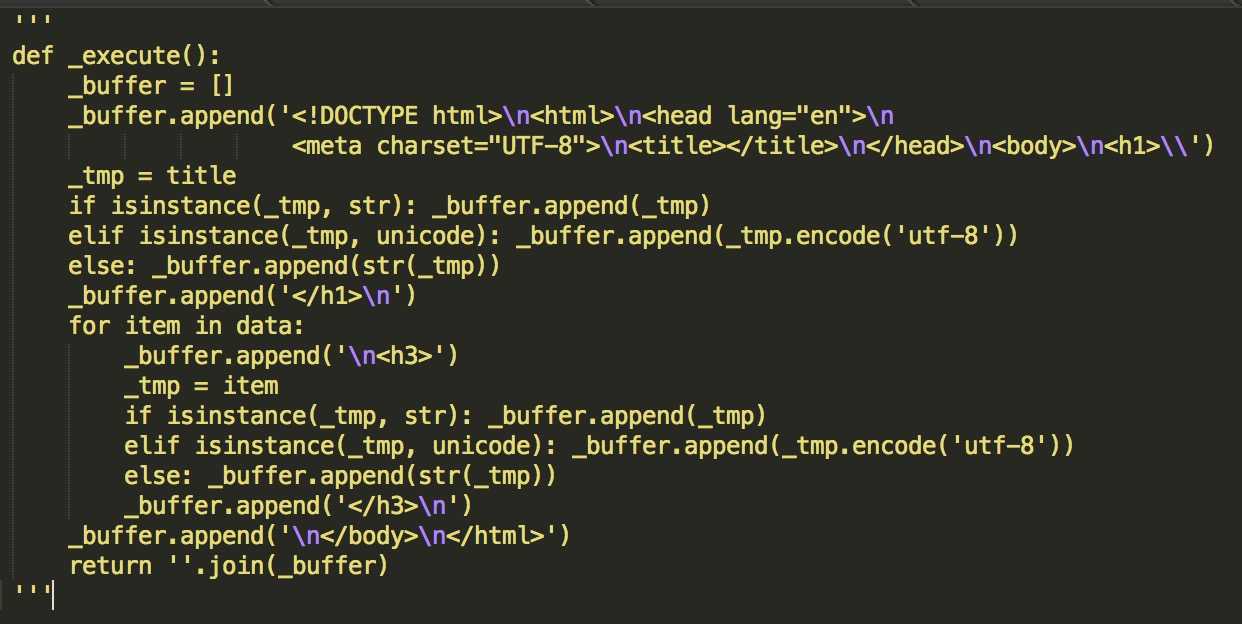
‘def _execute(): _buffer = [] _buffer.append(\\‘<!DOCTYPE html>\\n<html>\\n<head lang="en">\\n<meta charset="UTF-8">\\n<title></title>\\n</head>\\n<body>\\n<h1>\\‘) _tmp = title if isinstance(_tmp, str): _buffer.append(_tmp) elif isinstance(_tmp, unicode): _buffer.append(_tmp.encode(\\‘utf-8\\‘)) else: _buffer.append(str(_tmp)) _buffer.append(\\‘</h1>\\n\\‘) for item in data: _buffer.append(\\‘\\n<h3>\\‘) _tmp = item if isinstance(_tmp, str): _buffer.append(_tmp) elif isinstance(_tmp, unicode): _buffer.append(_tmp.encode(\\‘utf-8\\‘)) else: _buffer.append(str(_tmp)) _buffer.append(\\‘</h3>\\n\\‘) _buffer.append(\\‘\\n</body>\\n</html>\\‘) return \\‘\\‘.join(_buffer) ‘
a、参照本篇博文的前戏 http://www.cnblogs.com/wupeiqi/p/4592637.html b、全局变量有 title = ‘main‘;data = [‘11‘,‘22‘,‘33‘]
在第4步中,执行第3步生成的字符串表示的函数后得到的返回值就是要返回给客户端的响应信息主要内容。
此段代码主要有三项任务:
class RequestHandler(object): def render(self, template_name, **kwargs): #根据Html文件名称获取文件内容并把参数kwargs嵌入到内容的指定标签内 html = self.render_string(template_name, **kwargs) #执行ui_modules,再在html的内容中插入head,js文件、js内容、css文件、css内容和body信息。 js_embed = [] js_files = [] css_embed = [] css_files = [] html_heads = [] html_bodies = [] for module in getattr(self, "_active_modules", {}).itervalues(): embed_part = module.embedded_javascript() if embed_part: js_embed.append(_utf8(embed_part)) file_part = module.javascript_files() if file_part: if isinstance(file_part, basestring): js_files.append(file_part) else: js_files.extend(file_part) embed_part = module.embedded_css() if embed_part: css_embed.append(_utf8(embed_part)) file_part = module.css_files() if file_part: if isinstance(file_part, basestring): css_files.append(file_part) else: css_files.extend(file_part) head_part = module.html_head() if head_part: html_heads.append(_utf8(head_part)) body_part = module.html_body() if body_part: html_bodies.append(_utf8(body_part)) if js_files:#添加js文件 # Maintain order of JavaScript files given by modules paths = [] unique_paths = set() for path in js_files: if not path.startswith("/") and not path.startswith("http:"): path = self.static_url(path) if path not in unique_paths: paths.append(path) unique_paths.add(path) js = ‘‘.join(‘<script src="‘ + escape.xhtml_escape(p) + ‘" type="text/javascript"></script>‘ for p in paths) sloc = html.rindex(‘</body>‘) html = html[:sloc] + js + ‘\n‘ + html[sloc:] if js_embed:#添加js内容 js = ‘<script type="text/javascript">\n//<![CDATA[\n‘ + ‘\n‘.join(js_embed) + ‘\n//]]>\n</script>‘ sloc = html.rindex(‘</body>‘) html = html[:sloc] + js + ‘\n‘ + html[sloc:] if css_files:#添加css文件 paths = [] unique_paths = set() for path in css_files: if not path.startswith("/") and not path.startswith("http:"): path = self.static_url(path) if path not in unique_paths: paths.append(path) unique_paths.add(path) css = ‘‘.join(‘<link href="‘ + escape.xhtml_escape(p) + ‘" ‘ ‘type="text/css" rel="stylesheet"/>‘ for p in paths) hloc = html.index(‘</head>‘) html = html[:hloc] + css + ‘\n‘ + html[hloc:] if css_embed:#添加css内容 css = ‘<style type="text/css">\n‘ + ‘\n‘.join(css_embed) + ‘\n</style>‘ hloc = html.index(‘</head>‘) html = html[:hloc] + css + ‘\n‘ + html[hloc:] if html_heads:#添加html的header hloc = html.index(‘</head>‘) html = html[:hloc] + ‘‘.join(html_heads) + ‘\n‘ + html[hloc:] if html_bodies:#添加html的body hloc = html.index(‘</body>‘) html = html[:hloc] + ‘‘.join(html_bodies) + ‘\n‘ + html[hloc:] #把处理后的信息响应给客户端 self.finish(html)
对于上述三项任务,第一项是模板语言的重中之重,读取html文件并将数据嵌套到指定标签中,以下的步骤用于剖析整个过程(详情见下文);第二项是对返会给用户内容的补充,也就是在第一项处理完成之后,利用ui_modules再次在html中插入内容(head,js文件、js内容、css文件、css内容和body);第三项是通过socket将内容响应给客户端(见上篇)。
对于ui_modules,每一个ui_module其实就是一个类,一旦注册并激活了该ui_module,tornado便会自动执行其中的方法:embedded_javascript、javascript_files、embedded_css、css_files、html_head、html_body和render ,从而实现对html内容的补充。(执行过程见上述代码)
自定义UI Modules
此处是一个完整的 创建 --> 注册 --> 激活 的Demo
目录结构:
├── index.py
├── static
└── views
└── index.html
#!/usr/bin/env python # -*- coding:utf-8 -*- import tornado.ioloop import tornado.web class CustomModule(tornado.web.UIModule): def embedded_javascript(self): return ‘embedded_javascript‘ def javascript_files(self): return ‘javascript_files‘ def embedded_css(self): return ‘embedded_css‘ def css_files(self): return ‘css_files‘ def html_head(self): return ‘html_head‘ def html_body(self): return ‘html_body‘ def render(self): return ‘render‘ class MainHandler(tornado.web.RequestHandler): def get(self): self.render(‘index.html‘) settings = { ‘static_path‘: ‘static‘, "template_path": ‘views‘, "ui_modules": {‘Foo‘: CustomModule}, } application = tornado.web.Application([(r"/", MainHandler), ], **settings) if __name__ == "__main__": application.listen(8888) tornado.ioloop.IOLoop.instance().start()
<!DOCTYPE html> <html> <head lang="en"> <meta charset="UTF-8"> <title></title> </head> <body> <hr> {% module Foo() %} <hr> </body> </html>
<!DOCTYPE html> <html> <head lang="en"> <meta charset="UTF-8"> <title></title> <!-- css_files --> <link href="/static/css_files" type="text/css" rel="stylesheet"> <!-- embedded_css --> <style type="text/css"> embedded_css </style> </head> <body> <!-- html_head --> html_head <hr> <!-- redner --> render <hr> <!-- javascript_files --> <script src="/static/javascript_files" type="text/javascript"></script> <!-- embedded_javascript --> <script type="text/javascript"> //<![CDATA[ embedded_javascript //]]> </script> <!-- html_body --> html_body </body> </html>
该方法是本篇的重中之重,它负责去处理Html模板并返回最终结果,【概述】中提到的5件事中前四件都是此方法来完成的,即:
注意:详细编译和执行Demo请参见《第四篇:白话tornado源码之褪去模板外衣的前戏 》
class RequestHandler(object): def render_string(self, template_name, **kwargs): #获取配置文件中指定的模板文件夹路径,即:template_path = ‘views‘ template_path = self.get_template_path() #如果没有配置模板文件的路径,则默认去启动程序所在的目录去找 if not template_path: frame = sys._getframe(0) web_file = frame.f_code.co_filename while frame.f_code.co_filename == web_file: frame = frame.f_back template_path = os.path.dirname(frame.f_code.co_filename) if not getattr(RequestHandler, "_templates", None): RequestHandler._templates = {} #创建Loader对象,第一次创建后,会将该值保存在RequestHandler的静态字段_template_loaders中 if template_path not in RequestHandler._templates: loader = self.application.settings.get("template_loader") or template.Loader(template_path) RequestHandler._templates[template_path] = loader #执行Loader对象的load方法,该方法内部执行执行Loader的_create_template方法 #在_create_template方法内部使用open方法会打开html文件并读取html的内容,然后将其作为参数来创建一个Template对象 #Template的构造方法被执行时,内部解析html文件的内容,并根据内部的 {{}} {%%}标签对内容进行分割,最后生成一个字符串类表示的函数并保存在self.code字段中 t = RequestHandler._templates[template_path].load(template_name) #获取所有要嵌入到html中的值和框架默认提供的值 args = dict( handler=self, request=self.request, current_user=self.current_user, locale=self.locale, _=self.locale.translate, static_url=self.static_url, xsrf_form_html=self.xsrf_form_html, reverse_url=self.application.reverse_url ) args.update(self.ui) args.update(kwargs) #执行Template的generate方法,编译字符串表示的函数并将namespace中的所有key,value设置成全局变量,然后执行该函数。从而将值嵌套进html并返回。 return t.generate(**args)
class Loader(object): """A template loader that loads from a single root directory. You must use a template loader to use template constructs like {% extends %} and {% include %}. Loader caches all templates after they are loaded the first time. """ def __init__(self, root_directory): self.root = os.path.abspath(root_directory) self.templates = {}
class Loader(object): def load(self, name, parent_path=None): name = self.resolve_path(name, parent_path=parent_path) if name not in self.templates: path = os.path.join(self.root, name) f = open(path, "r") #读取html文件的内容 #创建Template对象 #name是文件名 self.templates[name] = Template(f.read(), name=name, loader=self) f.close() return self.templates[name]
class Template(object): def __init__(self, template_string, name="<string>", loader=None,compress_whitespace=None): # template_string是Html文件的内容 self.name = name if compress_whitespace is None: compress_whitespace = name.endswith(".html") or name.endswith(".js") #将内容封装到_TemplateReader对象中,用于之后根据模板语言的标签分割html文件 reader = _TemplateReader(name, template_string) #分割html文件成为一个一个的对象 #执行_parse方法,将html文件分割成_ChunkList对象 self.file = _File(_parse(reader)) #将html内容格式化成字符串表示的函数 self.code = self._generate_python(loader, compress_whitespace) try: #将字符串表示的函数编译成函数 self.compiled = compile(self.code, self.name, "exec") except: formatted_code = _format_code(self.code).rstrip() logging.error("%s code:\n%s", self.name, formatted_code) raise
class Template(object): def generate(self, **kwargs): """Generate this template with the given arguments.""" namespace = { "escape": escape.xhtml_escape, "xhtml_escape": escape.xhtml_escape, "url_escape": escape.url_escape, "json_encode": escape.json_encode, "squeeze": escape.squeeze, "linkify": escape.linkify, "datetime": datetime, } #创建变量环境并执行函数,详细Demo见上一篇博文 namespace.update(kwargs) exec self.compiled in namespace execute = namespace["_execute"] try: #执行编译好的字符串格式的函数,获取嵌套了值的html文件 return execute() except: formatted_code = _format_code(self.code).rstrip() logging.error("%s code:\n%s", self.name, formatted_code) raise
其中涉及的类有:
class _TemplateReader(object): def __init__(self, name, text): self.name = name self.text = text self.line = 0 self.pos = 0 def find(self, needle, start=0, end=None): assert start >= 0, start pos = self.pos start += pos if end is None: index = self.text.find(needle, start) else: end += pos assert end >= start index = self.text.find(needle, start, end) if index != -1: index -= pos return index def consume(self, count=None): if count is None: count = len(self.text) - self.pos newpos = self.pos + count self.line += self.text.count("\n", self.pos, newpos) s = self.text[self.pos:newpos] self.pos = newpos return s def remaining(self): return len(self.text) - self.pos def __len__(self): return self.remaining() def __getitem__(self, key): if type(key) is slice: size = len(self) start, stop, step = key.indices(size) if start is None: start = self.pos else: start += self.pos if stop is not None: stop += self.pos return self.text[slice(start, stop, step)] elif key < 0: return self.text[key] else: return self.text[self.pos + key] def __str__(self): return self.text[self.pos:]
class _ChunkList(_Node): def __init__(self, chunks): self.chunks = chunks def generate(self, writer): for chunk in self.chunks: chunk.generate(writer) def each_child(self): return self.chunks
def _parse(reader, in_block=None): #默认创建一个内容为空列表的_ChunkList对象 body = _ChunkList([]) # 将html块添加到 body.chunks 列表中 while True: # Find next template directive curly = 0 while True: curly = reader.find("{", curly) if curly == -1 or curly + 1 == reader.remaining(): # EOF if in_block: raise ParseError("Missing {%% end %%} block for %s" %in_block) body.chunks.append(_Text(reader.consume())) return body # If the first curly brace is not the start of a special token, # start searching from the character after it if reader[curly + 1] not in ("{", "%"): curly += 1 continue # When there are more than 2 curlies in a row, use the # innermost ones. This is useful when generating languages # like latex where curlies are also meaningful if (curly + 2 < reader.remaining() and reader[curly + 1] == ‘{‘ and reader[curly + 2] == ‘{‘): curly += 1 continue break # Append any text before the special token if curly > 0: body.chunks.append(_Text(reader.consume(curly))) start_brace = reader.consume(2) line = reader.line # Expression if start_brace == "{{": end = reader.find("}}") if end == -1 or reader.find("\n", 0, end) != -1: raise ParseError("Missing end expression }} on line %d" % line) contents = reader.consume(end).strip() reader.consume(2) if not contents: raise ParseError("Empty expression on line %d" % line) body.chunks.append(_Expression(contents)) continue # Block assert start_brace == "{%", start_brace end = reader.find("%}") if end == -1 or reader.find("\n", 0, end) != -1: raise ParseError("Missing end block %%} on line %d" % line) contents = reader.consume(end).strip() reader.consume(2) if not contents: raise ParseError("Empty block tag ({%% %%}) on line %d" % line) operator, space, suffix = contents.partition(" ") suffix = suffix.strip() # Intermediate ("else", "elif", etc) blocks intermediate_blocks = { "else": set(["if", "for", "while"]), "elif": set(["if"]), "except": set(["try"]), "finally": set(["try"]), } allowed_parents = intermediate_blocks.get(operator) if allowed_parents is not None: if not in_block: raise ParseError("%s outside %s block" % (operator, allowed_parents)) if in_block not in allowed_parents: raise ParseError("%s block cannot be attached to %s block" % (operator, in_block)) body.chunks.append(_IntermediateControlBlock(contents)) continue # End tag elif operator == "end": if not in_block: raise ParseError("Extra {%% end %%} block on line %d" % line) return body elif operator in ("extends", "include", "set", "import", "from", "comment"): if operator == "comment": continue if operator == "extends": suffix = suffix.strip(‘"‘).strip("‘") if not suffix: raise ParseError("extends missing file path on line %d" % line) block = _ExtendsBlock(suffix) elif operator in ("import", "from"): if not suffix: raise ParseError("import missing statement on line %d" % line) block = _Statement(contents) elif operator == "include": suffix = suffix.strip(‘"‘).strip("‘") if not suffix: raise ParseError("include missing file path on line %d" % line) block = _IncludeBlock(suffix, reader) elif operator == "set": if not suffix: raise ParseError("set missing statement on line %d" % line) block = _Statement(suffix) body.chunks.append(block) continue elif operator in ("apply", "block", "try", "if", "for", "while"): # parse inner body recursively block_body = _parse(reader, operator) if operator == "apply": if not suffix: raise ParseError("apply missing method name on line %d" % line) block = _ApplyBlock(suffix, block_body) elif operator == "block": if not suffix: raise ParseError("block missing name on line %d" % line) block = _NamedBlock(suffix, block_body) else: block = _ControlBlock(contents, block_body) body.chunks.append(block) continue else: raise ParseError("unknown operator: %r" % operator)
class Template(object): def _generate_python(self, loader, compress_whitespace): buffer = cStringIO.StringIO() try: named_blocks = {} ancestors = self._get_ancestors(loader) ancestors.reverse() for ancestor in ancestors: ancestor.find_named_blocks(loader, named_blocks) self.file.find_named_blocks(loader, named_blocks) writer = _CodeWriter(buffer, named_blocks, loader, self, compress_whitespace) ancestors[0].generate(writer) return buffer.getvalue() finally: buffer.close()
so,上述整个过程其实就是将一个html转换成一个函数,并为该函数提供全局变量,然后执行该函数!!
上述就是对于模板语言的整个流程,其本质就是处理html文件内容将html文件内容转换成函数,然后为该函数提供全局变量环境(即:我们想要嵌套进html中的值和框架自带的值),再之后执行该函数从而获取到处理后的结果,再再之后则执行UI_Modules继续丰富返回结果,例如:添加js文件、添加js内容块、添加css文件、添加css内容块、在body内容第一行插入数据、在body内容最后一样插入数据,最终,通过soekct客户端对象将处理之后的返回结果(字符串)响应给请求用户。
原文:http://www.cnblogs.com/fanweibin/p/5418845.html
