上一篇咱们讲解了Scrapy的工作机制和如何使用Scrapy爬取美女图片,而今天接着讲解Scrapy爬取美女图片,不过采取了不同的方式和代码实现,对Scrapy的功能进行更深入的运用。

在学习Scrapy官方文档的过程中,发现Scrapy自身实现了图片和文件的下载功能,不需要咱们之前自己实现图片的下载(不过原理都一样)。

在官方文档中,我们可以看到下面一些话:Scrapy为下载item中包含的文件(比如在爬取到产品时,同时也想保存对应的图片)提供了一个可重用的 item pipelines . 这些pipeline有些共同的方法和结构(我们称之为media pipeline)。一般来说你会使用Files Pipeline或者 Images Pipeline.
这两种pipeline都实现了以下特性:
避免重新下载最近已经下载过的数据
Specifying where to store the media (filesystem directory, Amazon S3 bucket)
The Images Pipeline has a few extra functions for processing images:
将所有下载的图片转换成通用的格式(JPG)和模式(RGB)
缩略图生成
检测图像的宽/高,确保它们满足最小限制
这个管道也会为那些当前安排好要下载的图片保留一个内部队列,并将那些到达的包含相同图片的项目连接到那个队列中。 这可以避免多次下载几个项目共享的同一个图片。
从上面的话中,我们可以了解到 Scrapy不仅可以下载图片,还可以生成指定大小的缩略图,这就非常有用。
当使用 FilesPipeline ,典型的工作流程如下所示:
在一个爬虫里,你抓取一个项目,把其中图片的URL放入 file_urls 组内。
项目从爬虫内返回,进入项目管道。
当项目进入 FilesPipeline,file_urls 组内的URLs将被Scrapy的调度器和下载器(这意味着调度器和下载器的中间件可以复用)安排下载,当优先级更高,会在其他页面被抓取前处理。项目会在这个特定的管道阶段保持“locker”的状态,直到完成文件的下载(或者由于某些原因未完成下载)。
当文件下载完后,另一个字段(files)将被更新到结构中。这个组将包含一个字典列表,其中包括下载文件的信息,比如下载路径、源抓取地址(从 file_urls 组获得)和图片的校验码(checksum)。 files 列表中的文件顺序将和源 file_urls 组保持一致。如果某个图片下载失败,将会记录下错误信息,图片也不会出现在 files 组中。
当使用Imagespipeline ,典型的工作流程如下所示:
在一个爬虫里,你抓取一个项目,把其中图片的URL放入 images_urls 组内。
项目从爬虫内返回,进入项目管道。
当项目进入 Imagespipeline,images_urls 组内的URLs将被Scrapy的调度器和下载器(这意味着调度器和下载器的中间件可以复用)安排下载,当优先级更高,会在其他页面被抓取前处理。项目会在这个特定的管道阶段保持“locker”的状态,直到完成文件的下载(或者由于某些原因未完成下载)。
当文件下载完后,另一个字段(images)将被更新到结构中。这个组将包含一个字典列表,其中包括下载文件的信息,比如下载路径、源抓取地址(从 images_urls 组获得)和图片的校验码(checksum)。 images 列表中的文件顺序将和源 images_urls 组保持一致。如果某个图片下载失败,将会记录下错误信息,图片也不会出现在 images 组中。
Pillow 是用来生成缩略图,并将图片归一化为JPEG/RGB格式,因此为了使用图片管道,你需要安装这个库。 Python Imaging Library (PIL) 在大多数情况下是有效的,但众所周知,在一些设置里会出现问题,因此我们推荐使用 Pillow 而不是PIL.
咱们这次用到的就是Images Pipeline,用来下载图片,同时使用 Pillow 生成缩略图。在安装Scrapy的基础上,使用pip install pillow 安装这个模块。
打开cmd,输入scrapy startproject jiandan,这时候会生成一个工程,然后我把整个工程复制到pycharm中(还是使用IDE开发快)。
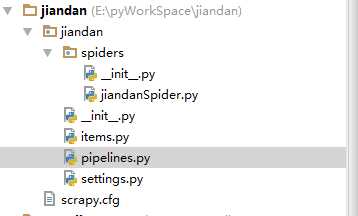
上图就是工程的结构。
jiandanSpider.py ------Spider 蜘蛛
items.py -----------------对要爬取数据的模型定义
pipelines.py-------------咱们最终要存储的数据
settings.py----------------对Scrapy的配置
接下来我把代码贴一下(复制代码请到我博客):
jiandanSpider.py(和之前没有变化):
#coding:utf-8
#需要安装pillow模块
import scrapy
from jiandan.items import JiandanItem
from scrapy.crawler import CrawlerProcess
class jiandanSpider(scrapy.Spider):
name = ‘jiandan‘
allowed_domains = []
start_urls = ["http://jandan.net/ooxx"]
def parse(self, response):
item = JiandanItem()
item[‘image_urls‘] = response.xpath(‘//img//@src‘).extract()#提取图片链接
# print ‘image_urls‘,item[‘image_urls‘]
yield item
new_url= response.xpath(‘//a[@class="previous-comment-page"]//@href‘).extract_first()#翻页
# print ‘new_url‘,new_url
if new_url:
yield scrapy.Request(new_url,callback=self.parse)
items.py(增加了一个字段,请看之前对Images Pipeline的描述) :
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class JiandanItem(scrapy.Item):
# define the fields for your item here like:
image_urls = scrapy.Field()#图片的链接
images = scrapy.Field()
pipelines.py(改变最大,看注释):
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don‘t forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import os
import urllib
import scrapy
from scrapy.exceptions import DropItem
from scrapy.pipelines.images import ImagesPipeline
from jiandan import settings
class JiandanPipeline(ImagesPipeline):#继承ImagesPipeline这个类,实现这个功能
def get_media_requests(self, item, info):#重写ImagesPipeline get_media_requests方法
‘‘‘
:param item:
:param info:
:return:
在工作流程中可以看到,
管道会得到文件的URL并从项目中下载。
为了这么做,你需要重写 get_media_requests() 方法,
并对各个图片URL返回一个Request:
‘‘‘
for image_url in item[‘image_urls‘]:
yield scrapy.Request(image_url)
def item_completed(self, results, item, info):
‘‘‘
:param results:
:param item:
:param info:
:return:
当一个单独项目中的所有图片请求完成时(要么完成下载,要么因为某种原因下载失败),
item_completed() 方法将被调用。
‘‘‘
image_paths = [x[‘path‘] for ok, x in results if ok]
if not image_paths:
raise DropItem("Item contains no images")
return item
settings.py(主要是对缩略图的设置):
# -*- coding: utf-8 -*-
# Scrapy settings for jiandan project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# http://doc.scrapy.org/en/latest/topics/settings.html
# http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
# http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html
BOT_NAME = ‘jiandan‘
SPIDER_MODULES = [‘jiandan.spiders‘]
NEWSPIDER_MODULE = ‘jiandan.spiders‘
ITEM_PIPELINES = {
‘jiandan.pipelines.JiandanPipeline‘: 1,
}
# ITEM_PIPELINES = {‘jiandan.pipelines.ImagesPipeline‘: 1}
IMAGES_STORE=‘E:\\jiandan2‘
DOWNLOAD_DELAY = 0.25
IMAGES_THUMBS = {#缩略图的尺寸,设置这个值就会产生缩略图
‘small‘: (50, 50),
‘big‘: (200, 200),
}
最后咱们开始运行程序,cmd切换到工程目录,
输入scrapy crawl jiandan,启动爬虫。。。
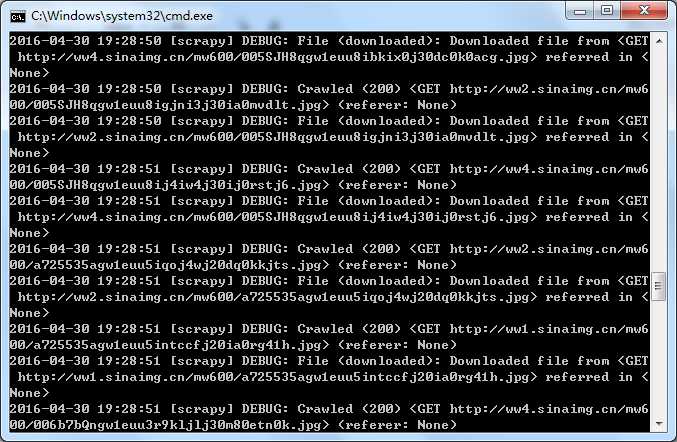
大约25分钟左右,爬虫工作结束。。。
咱们去看看美女图吧。
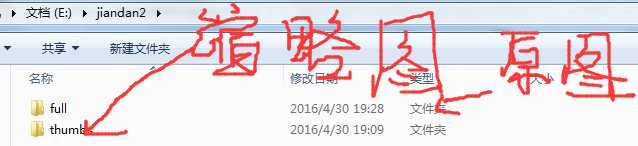
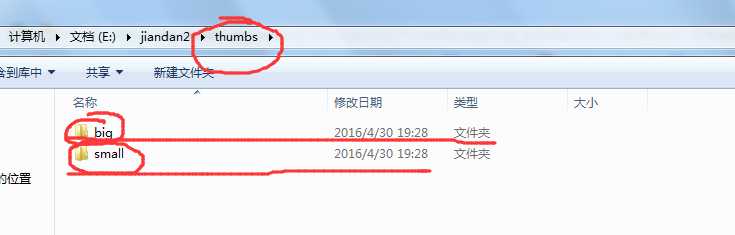
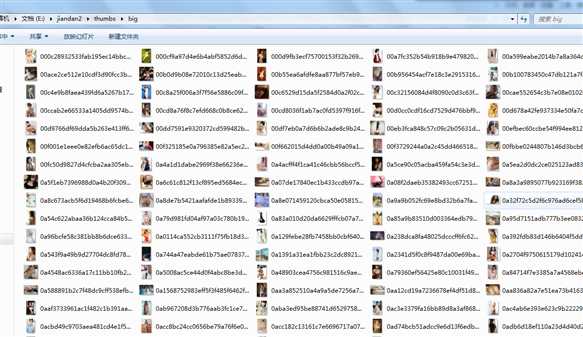
咱们打开thumbs文件夹,看看缩略图,下面有咱们设置的不同的尺寸。
今天的分享就到这里,如果大家觉得还可以呀,记得打赏呦。

欢迎大家支持我公众号:

本文章属于原创作品,欢迎大家转载分享。尊重原创,转载请注明来自:七夜的故事 http://www.cnblogs.com/qiyeboy/
原文:http://www.cnblogs.com/qiyeboy/p/5449266.html