

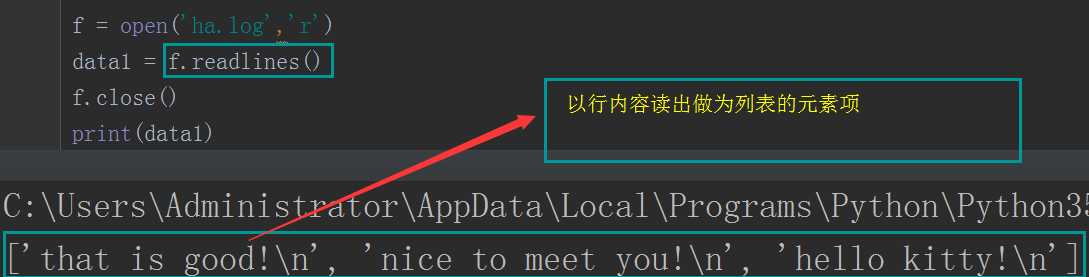
f = open(‘ha.log‘,‘r‘) data1 = f.readlines() f.close() print(data1) #结果为:[‘that is good!\n‘, ‘nice to meet you!\n‘, ‘hello kitty!\n‘] f = open(‘ha.log‘,‘r‘) f.seek(5) data2 = f.readlines() f.close() print(data2) #结果为:[‘is good!\n‘, ‘nice to meet you!\n‘, ‘hello kitty!\n‘]

f = open(‘ha.log‘,‘r‘)
for line in f:
print(line)
f.close()
#结果为:
that is good!
nice to meet you!
hello kitty!
‘r‘模式总结:只读模式在打开文件时是从头开始读,其中read()和readlines()是一次把文件所有内容都读取出来,在文件很大时,不建议这两种方法,非常占内存
而readline和循环文件是一行一行读,两次方法每次读取都是只占一行内容的内存,readline操作比较繁琐,并且你如果不知道最后一行在哪,一般容易报错,
一般用for循环
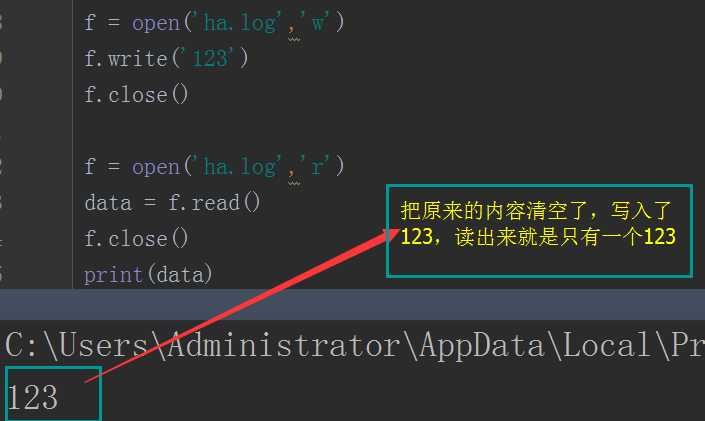
f = open(‘ha.log‘,‘w‘)
f.writelines([‘that is good!\n‘, ‘nice to meet you!\n‘, ‘hello kitty!\n‘])
f.close()
f = open(‘ha.log‘,‘r‘)
data = f.read()
f.close()
print(data)
结果为:
that is good!
nice to meet you!
hello kitty!
‘w’模式总结:只写模式适用于创建不存在的文件,用于清空内容再写入内容情况比较少,如果说想在文件末尾添加内容,这就涉及到我们即将讲的‘a’模式
f = open(‘ha.log‘,‘a‘)
print(f.tell())
f.write(‘大家好‘)
f.close()
f = open(‘ha.log‘,‘r‘)
data = f.read()
f.close()
print(data)
结果为:
48
that is good!
nice to meet you!
hello kitty!
大家好





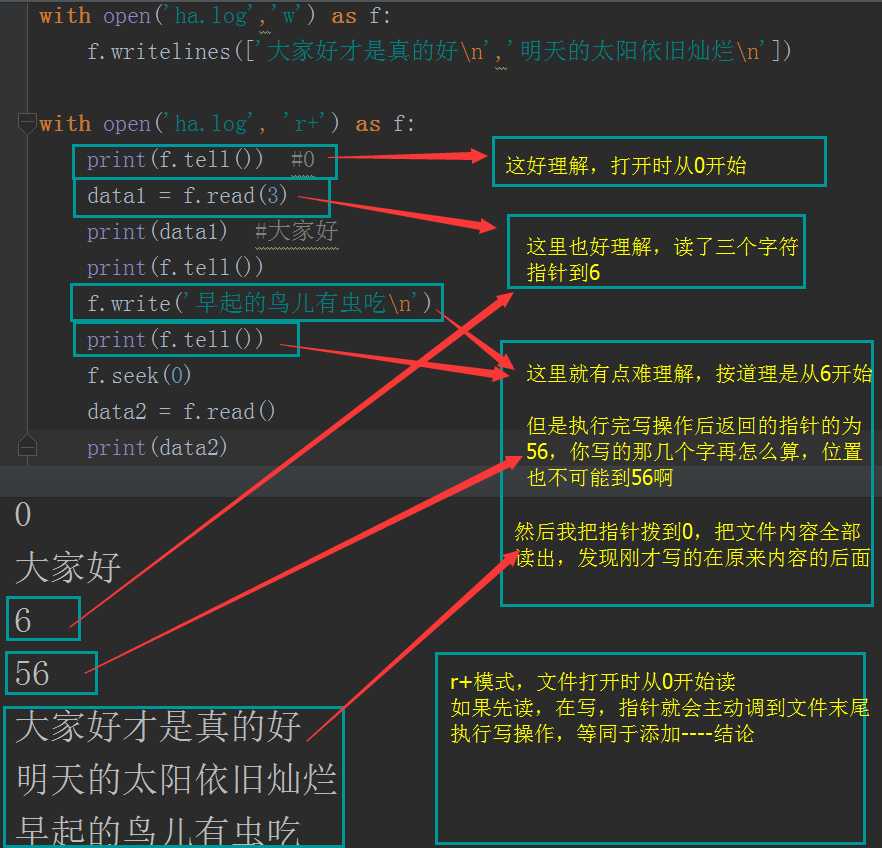

with open(‘ha.log‘,‘w‘) as f:
f.writelines([‘大家好才是真的好\n‘,‘明天的太阳依旧灿烂\n‘])
#打开以a+模式,如果先写,是从当前指针开始往后覆盖内容
with open(‘ha.log‘, ‘r+‘) as f:
print(f.tell()) #0
f.write(‘早起的鸟儿有虫吃\n‘)
f.seek(0)
data3 = f.read()
print(data3)
# 结果为:
# 早起的鸟儿有虫吃
# 明天的太阳依旧灿烂
大型文件复制:
with open(‘ha.log‘,‘r‘) as obj1,open(‘ha2.log‘,‘w‘) as obj2:
for line in obj1:
obj2.write(line)
with open(‘ha2.log‘,‘r‘) as obj2:
data = obj2.read()
print(data)
with open(‘ha2.log‘,‘a+‘) as obj1:
obj1.seek(6)
obj1.truncate()
obj1.seek(0)
data = obj1.read()
print(data) #结果为:大家好
原文:http://www.cnblogs.com/xinsiwei18/p/5551191.html