自1970年,埃德加·科德提出关系模型之后,关系数据库便开始出现,经过了40多年的演化,如今的关系型数据库具备了强大的存储、维护、查询数据的能力。但在关系数据库日益强大的时候,人们发现,在这个信息爆炸的“大数据”时代,关系型数据库遇到了性能方面的瓶颈,面对一个表中上亿条的数据,SQL语句在大数据的查询方面效率欠佳。我们应该知道,往往添加了越多的约束的技术,在一定程度上定会拖延其效率。
在1998年,Carlo Strozzi提出NOSQL的概念,指的是他开发的一个没有SQL功能,轻量级的,开源的关系型数据库。注意,这个定义跟我们现在对NoSQL的定义有很大的区别,它确确实实字如其名,指的就是“没有SQL”的数据库。但是NoSQL的发展慢慢偏离了初衷,CarloStrozzi也发觉,其实我们要的不是"nosql",而应该是"norelational",也就是我们现在常说的非关系型数据库了。
在关系型数据库中,导致性能欠佳的最主要因素是多表的关联查询,以及复杂的数据分析类型的复杂SQL报表查询。为了保证数据库的ACID特性,我们必须尽量按照其要求的范式进行设计,关系型数据库中的表都是存储一些格式化的数据结构,每个元组字段的组成都一样,即使不是每个元组都需要所有的字段,但数据库会为每个元组分配所有的字段,这样的结构可以便于表与表之间进行连接等操作,但从另一个角度来说它也是关系型数据库性能瓶颈的一个因素。
非关系型数据库提出另一种理念,他以键值对存储,且结构不固定,每一个元组可以有不一样的字段,每个元组可以根据需要增加一些自己的键值对,这样就不会局限于固定的结构,可以减少一些时间和空间的开销。使用这种方式,用户可以根据需要去添加自己需要的字段,这样,为了获取用户的不同信息,不需要像关系型数据库中,要对多表进行关联查询。仅需要根据id取出相应的value就可以完成查询。但非关系型数据库由于很少的约束,他也不能够提供想SQL所提供的where这种对于字段属性值情况的查询。并且难以体现设计的完整性。他只适合存储一些较为简单的数据,对于需要进行较复杂查询的数据,SQL数据库显得更为合适。
目前出现的NoSQL(Not only SQL,非关系型数据库)有不下于25种,除了Dynamo、Bigtable以外还有很多,比如Amazon的SimpleDB、微软公司的AzureTable、Facebook使用的Cassandra、类Bigtable的Hypertable、Hadoop的HBase、MongoDB、CouchDB、Redis以及Yahoo!的PNUTS等等。这些NoSQL各有特色,是基于不同应用场景而开发的,而其中以MongoDB和Redis最为被大家追捧。
以下是MongoDB的一些情况:
MongoDB是基于文档的存储的(而非表),是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。他支持的数据结构非常松散,是类似json的bjson格式,因此可以存储比较复杂的数据类型。模式自由(schema-free),意味着对于存储在MongoDB数据库中的文件,我们不需要知道它的任何结构定义。如果需要的话,你完全可以把不同结构的文件存储在同一个数据库里。Mongo最大的特点是他支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。
Mongo主要解决的是海量数据的访问效率问题。因为Mongo主要是支持海量数据存储的,所以Mongo还自带了一个出色的分布式文件系统GridFS,可以支持海量的数据存储。由于Mongo可以支持复杂的数据结构,而且带有强大的数据查询功能,因此非常受到欢迎。
补充:ACID,是指在数据库管理系统(DBMS)中事务所具有的四个特性:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation,又称独立性)、持久性(Durability)。
为了建立冗余较小、结构合理的数据库,设计数据库时必须遵循一定的规则。在关系型数据库中这种规则就称为范式。范式是符合某一种设计要求的总结。要想设计一个结构合理的关系型数据库,必须满足一定的范式。
在实际开发中最为常见的设计范式有三个:
1.第一范式(确保每列保持原子性)
第一范式是最基本的范式。如果数据库表中的所有字段值都是不可分解的原子值,就说明该数据库表满足了第一范式。
第一范式的合理遵循需要根据系统的实际需求来定。比如某些数据库系统中需要用到“地址”这个属性,本来直接将“地址”属性设计成一个数据库表的字段就行。但是如果系统经常会访问“地址”属性中的“城市”部分,那么就非要将“地址”这个属性重新拆分为省份、城市、详细地址等多个部分进行存储,这样在对地址中某一部分操作的时候将非常方便。这样设计才算满足了数据库的第一范式,如下表所示。
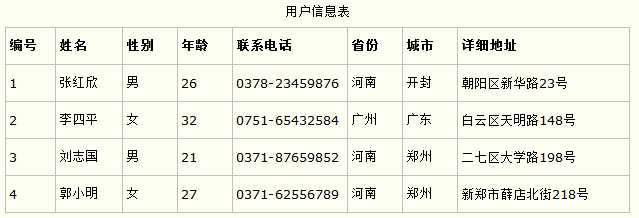
上表所示的用户信息遵循了第一范式的要求,这样在对用户使用城市进行分类的时候就非常方便,也提高了数据库的性能。
2.第二范式(确保表中的每列都和主键相关)
第二范式在第一范式的基础之上更进一层。第二范式需要确保数据库表中的每一列都和主键相关,而不能只与主键的某一部分相关(主要针对联合主键而言)。也就是说在一个数据库表中,一个表中只能保存一种数据,不可以把多种数据保存在同一张数据库表中。
比如要设计一个订单信息表,因为订单中可能会有多种商品,所以要将订单编号和商品编号作为数据库表的联合主键,如下表所示。
订单信息表
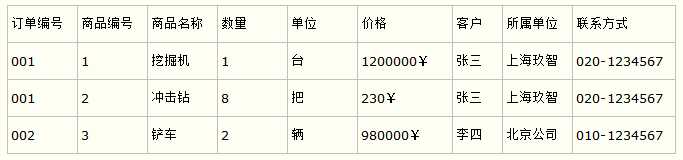
这样就产生一个问题:这个表中是以订单编号和商品编号作为联合主键。这样在该表中商品名称、单位、商品价格等信息不与该表的主键相关,而仅仅是与商品编号相关。所以在这里违反了第二范式的设计原则。
而如果把这个订单信息表进行拆分,把商品信息分离到另一个表中,把订单项目表也分离到另一个表中,就非常完美了。如下所示。
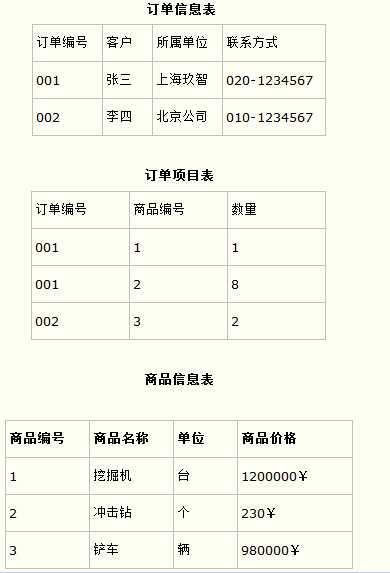
这样设计,在很大程度上减小了数据库的冗余。如果要获取订单的商品信息,使用商品编号到商品信息表中查询即可。
3.第三范式(确保每列都和主键列直接相关,而不是间接相关)
第三范式需要确保数据表中的每一列数据都和主键直接相关,而不能间接相关。
比如在设计一个订单数据表的时候,可以将客户编号作为一个外键和订单表建立相应的关系。而不可以在订单表中添加关于客户其它信息(比如姓名、所属公司等)的字段。如下面这两个表所示的设计就是一个满足第三范式的数据库表。
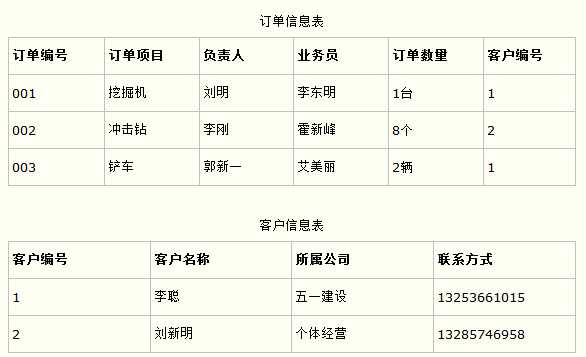
这样在查询订单信息的时候,就可以使用客户编号来引用客户信息表中的记录,也不必在订单信息表中多次输入客户信息的内容,减小了数据冗余。
原文:http://www.cnblogs.com/chenyongblog/p/3703560.html