由于awk具有上述特色,在问题处理的过程中,可轻易使用awk来撰写一些小工具;这些小工具并非用来解决整个大问题,它们只扮演解决个别问题过程的某些角色,可通过Shell所提供的pipe将数据按需要传送给不同的小工具进行处理,以解决整个大问题。这种解题方式,使得这些小工具可因不同需求而被重复组合及使用(reuse);也可通过这种方式来先行测试大程序原型的可行性与正确性,将来若需要较高的执行速度时再用C语言来改写。这是awk最常被应用之处。若能常常如此处理问题,读者可以以更高的角度来思考抽象的问题,而不会被拘泥于细节的部分。本手册作为awk入门的学习指引,其内容将先强调如何撰写awk程序,未列入进一步解题方式的应用实例,这部分将留待UNIX进阶手册中再行讨论。
一般的UNIX操作系统,本身即带有awk。不同的UNIX操作系统所带的awk其版本亦不尽相同。若读者所使用的系统上未带有awk,可通过anonymous ftp到下列地方取得:
phi.sinica.edu.tw:/pub/gnu
ftp.edu.tw:/UNIX/gnu
prep.ai.mit.edu:/pub/gnu
为便于解释awk程序架构,及有关术语(terminology),先以一个员工薪资数据文件(emp.dat),来加以介绍。
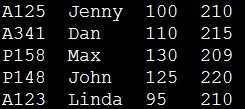
数据文件中各字段依次为 员工ID、姓名、时薪 及 实际工时。ID中的第一个字母为部门识别码,"A"、"P"分别表示"组装"及"包装"部门。
本小节着重于说明awk程序的主要架构及工作原理,并对一些重要的名词加以必要的解释。通过学习这部分内容,读者可体会出awk语言的主要精神及awk与其它语程序言的差别。为便于说明,之后以条列方式说明。
1. 记录(Record):awk从数据文件上读取数据的基本单位。以上列数据文件emp.dat为例,awk读入的
第一条记录是 "A125 Jenny 100 210"
第二条记录是 "A341 Dan 110 215"
一般而言, 一条 记录 就相当于数据文件上的一行资料。 (参考 : 附录 B 内建变量"RS")
2. 字段(Field):为记录中被分隔开的子字符串。以数据行"A125 Jenny 100 210"为例,
| 第一个 | 第二个 | 第三个 | 第四个 |
| “A125" | "Jenny" | 100 | 210 |
一般是以空格符来分隔相邻的字段。( 参考:附录 D 内建变量"FS" )
在UNIX的命令行上输入下列格式的指令:("$"表示Shell命令行上的提示符号)

$ awk ‘awk程序‘ 数据文件名
则awk会先编译该程序,然后执行该程序来处理所指定的数据文件。(上述方式直接把程序写在UNIX的命令行上)
awk程序中主要语法是 Pattern { Actions },故常见的awk程序其形式如下:
Pattern1 { Actions1 }
Pattern2 { Actions2 }
......
Pattern3 { Actions3 }
awk 可接受许多不同形式的 Pattern。一般常使用 "关系表达式"(Relational expression)来当作 Pattern。
例如:
x > 34 是一个Pattern,判断变量 x 与 34 是否存在大于的关系。
x == y 是一个Pattern,判断变量 x 与变量 y 是否存在等于的关系。
上式中 x >34 、 x == y 便是典型的Pattern。
awk 提供 C 语言中常见的关系运算符(Relational Operators) 如 >, <, >=, <=, ==, !=。此外,awk 还提供 ~ (match) 及 !~(not match) 二个关系运算符(注一)。
其用法与涵义如下:
若 A 为一字符串,B 为一正则表达式(Regular Expression)
A ~ B 判断 字符串A 中是否 包含 能匹配(match)B表达式的子字符串。
A !~ B 判断 字符串A 中是否 不包含 能匹配(match)B表达式的子字符串。
例如 :
"banana" ~ /an/ 整个是一个Pattern。
因为"banana"中含有可以匹配 /an/ 的子字符串,故此关系式成立(true),整个Pattern的值也是true。
相关细节请参考 附录 A Patterns, 附录 E Regular Expression
(注一:) 有少数awk文献,把 ~, !~ 当成另一类的 Operator,并不视为一种 Relational Operator。本手册中将这两个运算符当成一种 Relational Operator。
Actions 是由许多awk指令构成。而awk的指令与 C 语言中的指令十分类似。
例如:
awk的 I/O指令:print, printf( ), getline, ...
awk的 流程控制指令:if(...){..} else{..}, while(...){...}, ...
(请参考 附录 B --- "Actions" )
awk 会先判断(Evaluate) 该 Pattern 的值,若 Pattern 判断后的值为true (或不为0的数字,或不是空的字符串),则awk将执行该 Pattern 所对应的 Actions。反之,若 Pattern 的值不为 true,则awk将不执行该 Pattern所对应的 Actions。
例如:若awk程序中有下列两指令
50 > 23 {print "Hello! The word!!" }
"banana" ~ /123/ {print "Good morning !" }
awk会先判断 50 >23 是否成立。因为该式成立,所以awk将打印出"Hello! The word!!"。而另一 Pattern 为"banana"~/123/,因为"banana" 内未含有任何子字符串可 match /123/,该 Pattern 的值为false,故awk将不会打印出 "Good morning !"
有时语法 Pattern { Actions }中,Pattern 部分被省略,只剩 {Actions}。这种情形表示 "无条件执行这个 Actions"。
awk 所内建的字段变量及其涵意如下 :
|
字段变量 |
含义 |
|
$0 |
一字符串,其内容为目前 awk 所读入的整行数据。 |
|
$1 |
$0 上第一个字段的数据。 |
|
$2 |
$0 上第二个字段的数据。 |
|
... |
其余类推 |
1. 当 awk 从数据文件中读取一行数据时,awk 会使用内置变量$0 予以记录。
2. 每当 $0 被改动时 (例如:读入新的数据行 或 自行变更 $0) awk 会立刻重新分析 $0 的字段情况,并将 $0 上各字段的数据用 $1、$2、...等予以记录。
awk 提供了许多内置变量,使用者在程序中可使用这些变量来取得相关信息(不用加$)。常见的内置变量有:
|
内置变量 |
含义 |
|
NF (Number of Fields) |
为一整数,其值表示$0上所存在的字段总数。 |
|
NR (Number of Records) |
为一整数,其值表示awk已读入的数据行数目。 |
|
FILENAME |
awk正在处理的数据文件名。 |
例如 : awk 从数据文件 emp.dat 中读入第一行记录"A125 Jenny 100 210" 之后,程序中:
$0 的值将是 "A125 Jenny 100 210"
$1 的值为 "A125" $2 的值为 "Jenny"
$3 的值为 100 $4 的值为 210
NF 的值为 4 $NF 的值为 210 (笔者注:$NF即为$4)
NR 的值为 1 FILENAME 的值为 "emp.dat"
执行awk时,它会反复进行下列四步骤。
awk会自动重复进行上述4个步骤,使用者不须在程序中编写这个循环 (Loop)。
【译】 AWK教程指南 2概述,布布扣,bubuko.com
原文:http://www.cnblogs.com/qieerbushejinshikelou/p/3705468.html