因内置变量的个数不多,此处按其相关性分类说明,并未按其字母顺序排列。
ARGC表示命令行上除了选项 -F, -v, -f 及其所对应的参数之外的所有参数的个数。若将"awk程序"直接写在命令列上,则 ARGC 亦不将该"程序部分"列入计算。
ARGV数组用以记录命令列上的参数。
例:执行下列命令

$ awk -F\t -v a=8 -f prg.awk file1.dat file2.dat
或
$ awk -F\t -v a=8 ‘{ print $1 * a }‘ file1.dat file2.dat
执行上述任一程序后
ARGC = 3
ARGV[0] = "awk"
ARGV[1] = "file1.dat"
ARGV[2] = "file2.dat"
读者请留心:当 ARGC = 3 时,命令行上仅指定了 2 个文件。
注:
-F\t 表示以 tab 为字段分隔字符 FS(field seporator)。
-v a=8 用以初始化程序中的变量 a。
FILENAME用以表示目前正在处理的文件的文件名。
字段分隔字符。
表示目前awk所读入的数据行。
分別表示所读入的数据行的第一个字段,第二个字段,...(参考下列说明)
当awk读入一行数据 "A123 8:15" 时,会先以$0 记录,故 $0 = "A123 8:15"。若程序中进一步使用了 $1, $2.. 或 NF 等内置变量时,awk才会自动分割 $0以便取得字段相关的数据,切割后各个字段的数据会分別以$1, $2, $3...记录。
awk缺省(default)的 字段分隔字符(FS) 为 空白字符(空格及tab)。以本例而言,读者若未改变 FS,则分割后:
第一个字段($1)="A123", 第二个字段($2)="8:15"。
使用者可用正则表达式自行定义 FS。awk每次需要分割数据行时,都会参考目前FS的值。
例如:
令 FS = "[ :]+" 表示任何由 空白" " 或 冒号":" 所组成的字串都可当成分隔字符,则分割后:
第一个字段($1) = "A123",第二个字段($2) = "8",第三个字段($3) = "15"
NR 表示从 awk 开始执行该程序后所读取的数据行数。
FNR 与 NR 功用类似,不同的是awk每打开一个新的文件,FNR 便从 0 重新累计。
NF表示目前的数据行所被切分的字段数。awk 每读入一行数据后,在程序中可用 NF 来得知该行数据包含的字段个数。在下一行数据被读入之前,NF 并不会改变。但使用者若自行使用$0来记录数据,例如:使用 getline,此时 NF 将代表新的 $0 上所记载的数据的字段个数。
输出时的字段分隔字符。缺省为 " "(一个空白),详见下面说明。
输出时数据行的分隔字符。缺省为 "\n"(换行),见下面说明。
数值数据的输出格式。缺省为 "%.6g"(若须要时最多打印6位小数)
当使用 print 指令一次打印多项数据时,
例如:print $1, $2
输出时,awk会自动在 $1 与 $2 之间补上一个 OFS 的值(缺省为一个空白)。
每次使用 print 输出后,awk会自动补上 ORS 的值(缺省为换行符)。
使用 print 输出数值数据时,awk将采用 OFMT 的值为输出格式。
例如:
$ awk ‘BEGIN { print 2/3,1; OFS=":"; OFMT="%.2g"; print 2/3,1 }‘
输出:
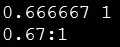
程序中通过改变OFS和OFMT的值,改变了指令 print 的输出格式。
RS( Record Separator):awk从文件上读取数据时,将根据 RS 的定义把数据切割成许多记录,而awk一次仅读入一条记录进行处理。
RS 的缺省值是 "\n",所以一般 awk一次仅读入一行数据。有时一个Record含括了几行数据(Multi-line Record),这情況下不能再以"\n"
来分隔相邻的记录,可改用 空白行 来分隔。
在awk程序中,令 RS = "" 表示以 空白行 来分隔相邻的记录。
与使用字串函数 match( )有关的变量,详见下面说明。
与使用字串函数match( )有关的变量。
当使用者使用 match(...) 函数后,awk会将 match(...) 执行的结果以RSTART、RLENGTH 记录。
请参考 附录 C awk的内置函数 match()。
SUBSEP(Subscript Separator) 数组下标的分隔字符,缺省值为"\034"。
实际上,awk中的 数组 只接受 字串 当它的下标,如: Arr["John"]。但使用者在 awk 中仍可使用 数字 当阵列的下标,甚至可使用多维的数组(Multi-dimenisional Array) 如:Arr[2,79]。事实上,awk在接受 Arr[2,79] 之前,就已先把其下标转换成字串"2\03479",之后便以Arr["2\03479"] 代替 Arr[2,79]。
可参考下例:
awk ‘BEGIN {
Arr[2,79] = 78
print Arr[2,79]
print Arr[ 2 , 79 ]
print Arr["2\03479"]
idx = 2 SUBSEP 79
print Arr[idx]
}
‘ $*
执行结果:

【译】 AWK教程指南 附录D-AWK的内置变量,布布扣,bubuko.com
原文:http://www.cnblogs.com/qieerbushejinshikelou/p/3705562.html