在这篇文章中,我将要介绍如何搭建和使用Apache Kafka在windows环境。在开始之前,简要介绍一下Kafka,然后再进行实践。
Apache Kafka
Kafka是分布式的发布-订阅消息的解决方案。相比于传统的消息系统,Kafka快速,可扩展,耐用。想象一下传统的发布-订阅消息系统,producers产生/写消息到topic中,另一边,consumers从topic中消费/读消息。Kafka的topic可以在多个服务器之间分区(partition)和复制(replicate)。
可以得到更多细节信息从Kafka官网。
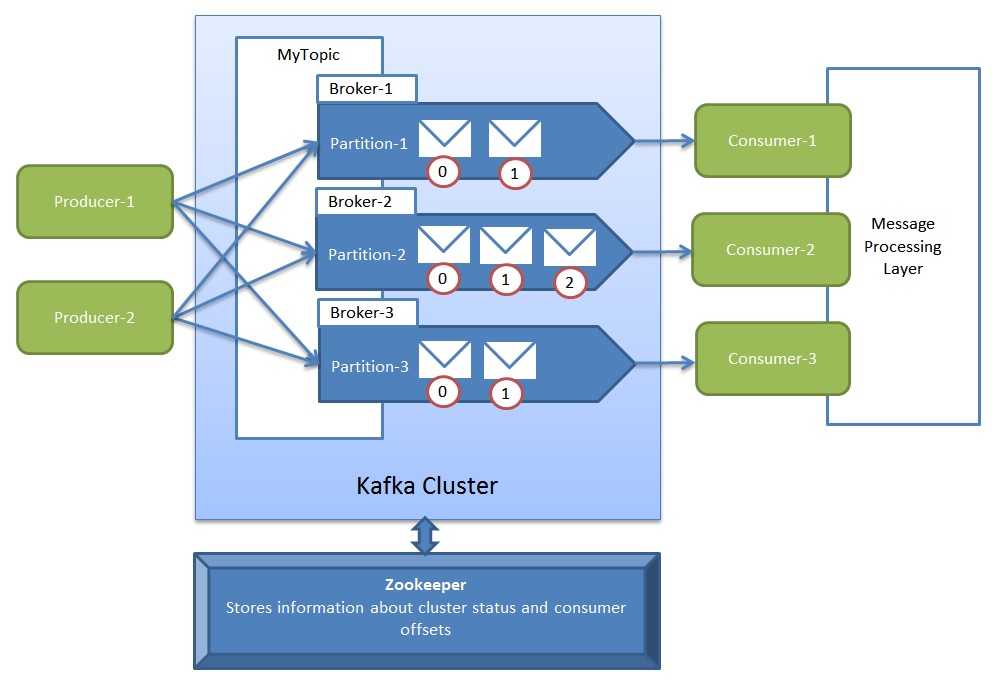
我参考了这篇博客(http://blog.cloudera.com/blog/2014/09/apache-kafka-for-beginners/)。它简单并很好的解释了Kafka是什么。这两张图片也取自同一篇博客。
"Messages are simply byte arrays and the developers can use them to store any object in any format – with String, JSON, and Avro the most common. It is possible to attach a key to each message, in which case the producer guarantees that all messages with the same key will arrive to the same partition. When consuming from a topic, it is possible to configure a consumer group with multiple consumers. Each consumer in a consumer group will read messages from a unique subset of partitions in each topic they subscribe to, so each message is delivered to one consumer in the group, and all messages with the same key arrive at the same consumer."
"What makes Kafka unique is that Kafka treats each topic partition as a log (an ordered set of messages). Each message in a partition is assigned a unique offset. Kafka does not attempt to track which messages were read by each consumer and only retain unread messages; rather, Kafka retains all messages for a set amount of time, and consumers are responsible to track their location in each log. Consequently, Kafka can support a large number of consumers and retain large amounts of data with very little overhead."
Apache Kafka - Quick Start on Windows
原文:http://www.cnblogs.com/zdfjf/p/5645093.html