该算法基于一个简单的操作: 将两个有序的队列合成一个更大的有序队列。

归并排序保证NlogN。
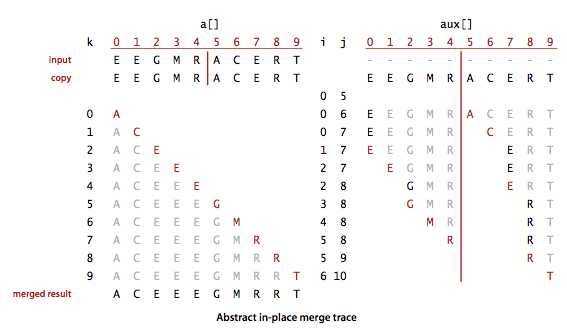
原地归并的抽象算法(Abstract in-place merge):

using System; namespace MergeSort { class Program { static char[] aux = new char[100]; static void Main(string[] args) { char[] data = new char[] { ‘R‘, ‘S‘, ‘T‘, ‘Z‘, ‘B‘, ‘C‘, ‘D‘ }; merge(data,0, 3, 6); // Expect result "BCDRSTZ" } public static void merge(char[] a, int lo, int mid, int hi) { // 将a[lo..mid] 和 a[mid+1..hi]归并 int i = lo, j = mid + 1; for (int k = lo; k <= hi; k++) { aux[k] = a[k]; } for (int k = lo; k <= hi; k++) // merge to a[lo..hi] { if (i > mid) a[k] = aux[j++]; else if (j > hi) a[k] = aux[i++]; else if (aux[j] < aux[i]) a[k] = aux[j++]; else a[k] = aux[i++]; } } } }
如何确定i, j, k 的取值,根据下图可以观察出他们的规律:
Top-down mergesort
自顶向下的归并排序是基于原地归并排序的递归实现。是分治思想的典型例子。

代码如下:
// 将数组a[lo..hi]排序 public static void sort(char[] a, int lo, int hi) { if (hi <= lo) return; int mid = lo + (hi - lo) / 2; sort(a, lo, mid); // 将左边排序 sort(a, mid + 1, hi); // 将右边排序 merge(a, lo, mid, hi); // 归并结果 }
Bottom-up mergesort:
这种方法是先归并较小的,然后才是较大的,这样避免了递归调用:
public void sort(char[] a) {
int N = a.Length; char[] _aux = new char[N]; for (int sz = 1; sz < N; sz = sz + sz)// sz 子数组的大小 for (int lo = 0; lo < N - sz; lo += sz + sz)//sz 子数组的索引 { merge(a, lo, lo + sz - 1, Math.Min(lo + sz + sz - 1, N - 1)); } }
观察下图就可以得出上面的算法,注意下图的sz = 1, 2 ,4...而不是 2,4, 8...:

总体感觉这种分析方法很重要,如果把这些分析过程搞明白了,代码很容易。以后得改掉先代码后想的习惯。
原文:http://www.cnblogs.com/ming11/p/3710486.html